Perception Model Training for Autonomous Vehicles with Tensor Parallelism
Due to the adoption of multicamera inputs and deep convolutional backbone networks, the GPU memory footprint for training autonomous driving perception models...
New LLM: Snowflake Arctic Model for SQL and Code Generation
Large language models (LLMs) have revolutionized natural language processing (NLP) in recent years, enabling a wide range of applications such as text...
Enhance Text-to-Image Fine-Tuning with DRaFT+, Now Part of NVIDIA NeMo
Text-to-image diffusion models have been established as a powerful method for high-fidelity image generation based on given text. Nevertheless, diffusion models...
Announcing Confidential Computing General Access on NVIDIA H100 Tensor Core GPUs
NVIDIA launched the initial release of the Confidential Computing (CC) solution in private preview for early access in July 2023 through NVIDIA LaunchPad....
Democratizing AI Workflows with Union.ai and NVIDIA DGX Cloud
GPUs were initially specialized for rendering 3D graphics in video games, primarily to accelerate linear algebra calculations. Today, GPUs have become one of...
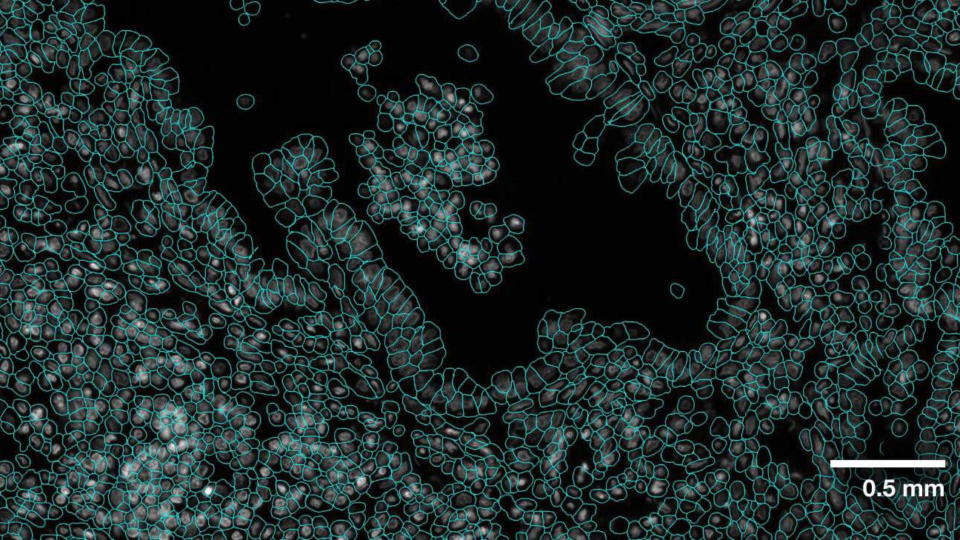
Advancing Cell Segmentation and Morphology Analysis with NVIDIA AI Foundation Model VISTA-2D
Genomics researchers use different sequencing techniques to better understand biological systems, including single-cell and spatial omics. Unlike single-cell,...
Developing Virtual Factory Solutions with OpenUSD and NVIDIA Omniverse
With NVIDIA AI, NVIDIA Omniverse, and the Universal Scene Description (OpenUSD) ecosystem, industrial developers are building virtual factory solutions that...
Mistral Large and Mixtral 8x22B LLMs Now Powered by NVIDIA NIM and NVIDIA API
This week’s model release features two new NVIDIA AI Foundation models, Mistral Large and Mixtral 8x22B, both developed by Mistral AI. These cutting-edge...
Turbocharging Meta Llama 3 Performance with NVIDIA TensorRT-LLM and NVIDIA Triton Inference Server
We're excited to announce support for the Meta Llama 3 family of models in NVIDIA TensorRT-LLM, accelerating and optimizing your LLM inference performance. You...
Enhanced DU Performance and Workload Consolidation for 5G/6G with NVIDIA Aerial CUDA-Accelerated RAN
Aerial CUDA-Accelerated radio access network (RAN) enables acceleration of telco workloads, delivering new levels of spectral efficiency (SE) on a cloud-native...
New LLM: Snowflake Arctic Model for SQL and Code Generation
Large language models (LLMs) have revolutionized natural language processing (NLP) in recent years, enabling a wide range of applications such as text...
Enhance Text-to-Image Fine-Tuning with DRaFT+, Now Part of NVIDIA NeMo
Text-to-image diffusion models have been established as a powerful method for high-fidelity image generation based on given text. Nevertheless, diffusion models...
Announcing Confidential Computing General Access on NVIDIA H100 Tensor Core GPUs
NVIDIA launched the initial release of the Confidential Computing (CC) solution in private preview for early access in July 2023 through NVIDIA LaunchPad....
Democratizing AI Workflows with Union.ai and NVIDIA DGX Cloud
GPUs were initially specialized for rendering 3D graphics in video games, primarily to accelerate linear algebra calculations. Today, GPUs have become one of...
Advancing Cell Segmentation and Morphology Analysis with NVIDIA AI Foundation Model VISTA-2D
Genomics researchers use different sequencing techniques to better understand biological systems, including single-cell and spatial omics. Unlike single-cell,...
Mistral Large and Mixtral 8x22B LLMs Now Powered by NVIDIA NIM and NVIDIA API
This week’s model release features two new NVIDIA AI Foundation models, Mistral Large and Mixtral 8x22B, both developed by Mistral AI. These cutting-edge...
Turbocharging Meta Llama 3 Performance with NVIDIA TensorRT-LLM and NVIDIA Triton Inference Server
We're excited to announce support for the Meta Llama 3 family of models in NVIDIA TensorRT-LLM, accelerating and optimizing your LLM inference performance. You...
Pushing the Boundaries of Speech Recognition with NVIDIA NeMo Parakeet ASR Models
NVIDIA NeMo, an end-to-end platform for the development of multimodal generative AI models at scale anywhere—on any cloud and on-premises—released the...
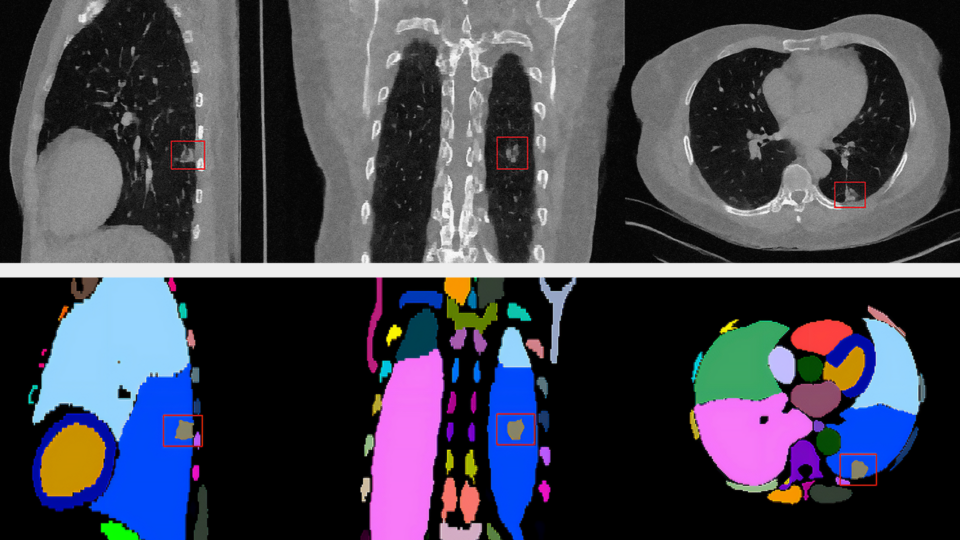
Advancing Medical Image Decoding with GPU-Accelerated nvImageCodec
This post delves into the capabilities of decoding DICOM medical images within AWS HealthImaging using the nvJPEG2000 library. We'll guide you through the...
How Generative AI is Empowering Climate Tech with NVIDIA Earth-2
In the context of global warming, NVIDIA Earth-2 has emerged as a pivotal platform for climate tech, generating actionable insights in the face of increasingly...
Developing Virtual Factory Solutions with OpenUSD and NVIDIA Omniverse
With NVIDIA AI, NVIDIA Omniverse, and the Universal Scene Description (OpenUSD) ecosystem, industrial developers are building virtual factory solutions that...
Enhanced DU Performance and Workload Consolidation for 5G/6G with NVIDIA Aerial CUDA-Accelerated RAN
Aerial CUDA-Accelerated radio access network (RAN) enables acceleration of telco workloads, delivering new levels of spectral efficiency (SE) on a cloud-native...
Universal Scene Description, also called OpenUSD or USD, is an open and extensible framework for creating, editing, querying, rendering, collaborating, and...
How Generative AI is Empowering Climate Tech with NVIDIA Earth-2
In the context of global warming, NVIDIA Earth-2 has emerged as a pivotal platform for climate tech, generating actionable insights in the face of increasingly...
Efficient CUDA Debugging: Using NVIDIA Compute Sanitizer with NVIDIA Tools Extension and Creating Custom Tools
NVIDIA Compute Sanitizer is a powerful tool that can save you time and effort while improving the reliability and performance of your CUDA applications....
Building High-Performance Applications in the Era of Accelerated Computing
AI is augmenting high-performance computing (HPC) with novel approaches to data processing, simulation, and modeling. Because of the computational requirements...
NVIDIA cuOpt is an accelerated optimization engine for solving complex routing problems. It efficiently solves problems with different aspects such as breaks,...
Accelerating the Future of Wireless Communication with the NVIDIA 6G Developer Program
6G will make the telco network AI-native for the first time. To develop 6G technologies, the telecom industry needs a whole new approach to research. The...
Generative AI for Digital Humans and New AI-powered NVIDIA RTX Lighting
At GDC 2024, NVIDIA announced that leading AI application developers such as Inworld AI are using NVIDIA digital human technologies to accelerate the deployment...
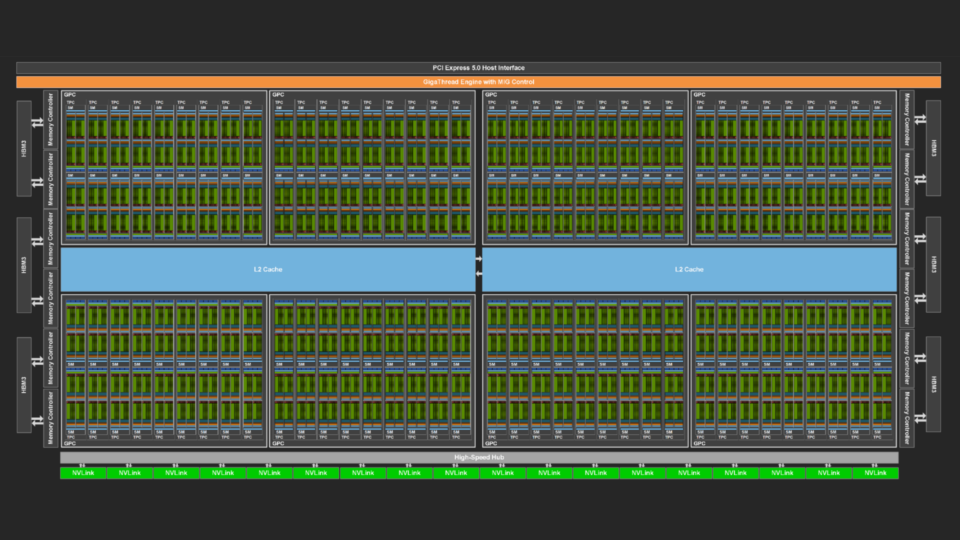
NVIDIA GB200 NVL72 Delivers Trillion-Parameter LLM Training and Real-Time Inference
What is the interest in trillion-parameter models? We know many of the use cases today and interest is growing due to the promise of an increased capacity for:...
An Introduction to Quantum Accelerated Supercomputing
The development of useful quantum computing is a massive global effort, spanning government, enterprise, and academia. The benefits of quantum computing could...
New Standard for Speech Recognition and Translation from the NVIDIA NeMo Canary Model
NVIDIA NeMo is an end-to-end platform for the development of multimodal generative AI models at scale anywhere—on any cloud and on-premises. The NeMo team...
Pushing the Boundaries of Speech Recognition with NVIDIA NeMo Parakeet ASR Models
NVIDIA NeMo, an end-to-end platform for the development of multimodal generative AI models at scale anywhere—on any cloud and on-premises—released the...
Explainer: What Is a Convolutional Neural Network?
A convolutional neural network is a type of deep learning network used primarily to identify and classify images and to recognize objects within images.
Develop Custom Enterprise Generative AI with NVIDIA NeMo
Generative AI is transforming computing, paving new avenues for humans to interact with computers in natural, intuitive ways. For enterprises, the prospect of...
Generative AI for Digital Humans and New AI-powered NVIDIA RTX Lighting
At GDC 2024, NVIDIA announced that leading AI application developers such as Inworld AI are using NVIDIA digital human technologies to accelerate the deployment...
NVIDIA Speech and Translation AI Models Set Records for Speed and Accuracy
Speech and translation AI models developed at NVIDIA are pushing the boundaries of performance and innovation. The NVIDIA Parakeet automatic speech recognition...
Turning Machine Learning to Federated Learning in Minutes with NVIDIA FLARE 2.4
Federated learning (FL) is experiencing accelerated adoption due to its decentralized, privacy-preserving nature. In sectors such as healthcare and financial...
Solve Complex AI Tasks with Leaderboard-Topping Smaug 72B from NVIDIA AI Foundation Models
This week’s model release features the NVIDIA-optimized language model Smaug 72B, which you can experience directly from your browser. NVIDIA AI Foundation...
Scalable Federated Learning with NVIDIA FLARE for Enhanced LLM Performance
In the ever-evolving landscape of large language models (LLMs), effective data management is a key challenge. Data is at the heart of model performance. While...
Coding is essential in the digital age, but it can also be tedious and time-consuming. That's why many developers are looking for ways to automate and...
Advancing Medical Image Decoding with GPU-Accelerated nvImageCodec
This post delves into the capabilities of decoding DICOM medical images within AWS HealthImaging using the nvJPEG2000 library. We'll guide you through the...
Explainer: What Is a Convolutional Neural Network?
A convolutional neural network is a type of deep learning network used primarily to identify and classify images and to recognize objects within images.
Developing Production-Ready AI Sensor Processing Applications with NVIDIA Holoscan 1.0
Edge AI developers are building AI applications and products for safety-critical and regulated use cases. With NVIDIA Holoscan 1.0, these applications can...
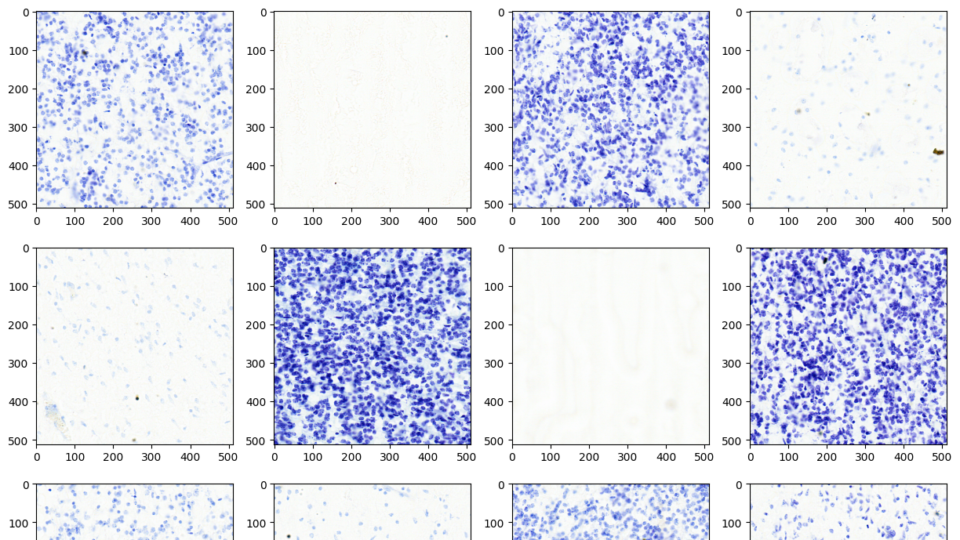
Breaking Barriers in Healthcare with New Models for Generative AI and Cellular Imaging
Driving the future of healthcare imaging, NVIDIA MONAI microservices are creating unique state-of-the-art models and expanded modalities to meet the demands of...
Calculating Video Quality Using NVIDIA GPUs and VMAF-CUDA
Video quality metrics are used to evaluate the fidelity of video content. They provide a consistent quantitative measurement to assess the performance of the...
While part 1 focused on the usage of the new NVIDIA cuTENSOR 2.0 CUDA math library, this post introduces a variety of usage modes beyond that, specifically...
cuTENSOR 2.0: A Comprehensive Guide for Accelerating Tensor Computations
NVIDIA cuTENSOR is a CUDA math library that provides optimized implementations of tensor operations where tensors are dense, multi-dimensional arrays or array...
Generate Stunning Images with Stable Diffusion XL on the NVIDIA AI Inference Platform
Diffusion models are transforming creative workflows across industries. These models generate stunning images based on simple text or image inputs by...
Spotlight: Honeywell Accelerates Industrial Process Simulation with NVIDIA cuDSS
For over a decade, traditional industrial process modeling and simulation approaches have struggled to fully leverage multicore CPUs or acceleration devices to...
Democratizing AI Workflows with Union.ai and NVIDIA DGX Cloud
GPUs were initially specialized for rendering 3D graphics in video games, primarily to accelerate linear algebra calculations. Today, GPUs have become one of...
Advancing Cell Segmentation and Morphology Analysis with NVIDIA AI Foundation Model VISTA-2D
Genomics researchers use different sequencing techniques to better understand biological systems, including single-cell and spatial omics. Unlike single-cell,...
Advancing Medical Image Decoding with GPU-Accelerated nvImageCodec
This post delves into the capabilities of decoding DICOM medical images within AWS HealthImaging using the nvJPEG2000 library. We'll guide you through the...
Explainer: What Is a Convolutional Neural Network?
A convolutional neural network is a type of deep learning network used primarily to identify and classify images and to recognize objects within images.
Universal Scene Description, also called OpenUSD or USD, is an open and extensible framework for creating, editing, querying, rendering, collaborating, and...
Optimizing Memory and Retrieval for Graph Neural Networks with WholeGraph, Part 2
Large-scale graph neural network (GNN) training presents formidable challenges, particularly concerning the scale and complexity of graph data. These challenges...
Sentiment analysis is the automated interpretation and classification of emotions (usually positive, negative, or neutral) from textual data such as written...
Efficient CUDA Debugging: Using NVIDIA Compute Sanitizer with NVIDIA Tools Extension and Creating Custom Tools
NVIDIA Compute Sanitizer is a powerful tool that can save you time and effort while improving the reliability and performance of your CUDA applications....
Scale and Curate High-Quality Datasets for LLM Training with NVIDIA NeMo Curator
Enterprises are using large language models (LLMs) as powerful tools to improve operational efficiency and drive innovation. NVIDIA NeMo microservices aim to...
Speed Up Your AI Development: NVIDIA AI Workbench Goes GA
NVIDIA AI Workbench, a toolkit for AI and ML developers, is now generally available as a free download. It features automation that removes roadblocks for...
Universal Scene Description, also called OpenUSD or USD, is an open and extensible framework for creating, editing, querying, rendering, collaborating, and...
Next-Generation Live Media Apps on Repurposable Clusters with NVIDIA Holoscan for Media
NVIDIA Holoscan for Media is now available to all developers looking to build next-generation live media applications on fully repurposable clusters. ...
Speed Up Your AI Development: NVIDIA AI Workbench Goes GA
NVIDIA AI Workbench, a toolkit for AI and ML developers, is now generally available as a free download. It features automation that removes roadblocks for...
Upgrade Your Graphics: Explore New Ray Tracing Features for NVIDIA Nsight Tools
The union of ray tracing and AI is pushing graphics fidelity and performance to new heights. Helping you build optimized, bug-free applications in this era of...
Generative AI for Digital Humans and New AI-powered NVIDIA RTX Lighting
At GDC 2024, NVIDIA announced that leading AI application developers such as Inworld AI are using NVIDIA digital human technologies to accelerate the deployment...
Powerful Shader Insights: Using Shader Debug Info with NVIDIA Nsight Graphics
As ray tracing becomes the predominant rendering technique in modern game engines, a single GPU RayGen shader can now perform most of the light simulation of a...
Streamline Live Media Application Development with New Features in NVIDIA Holoscan for Media
NVIDIA Holoscan for Media is a software-defined platform for building and deploying applications for live media. Recent updates introduce a user-friendly...
Advancing GPU-Driven Rendering with Work Graphs in Direct3D 12
GPU-driven rendering has long been a major goal for many game applications. It enables better scalability for handling large virtual scenes and reduces cases...
Work Graphs in Direct3D 12: A Case Study of Deferred Shading
When it comes to game application performance, GPU-driven rendering enables better scalability for handling large virtual scenes. Direct3D 12 (D3D12) introduces...
Make the Most of NVIDIA GTC 2024 with In-Person, Hands-On Learning
We are so excited to be back in person at GTC this year at the San Jose Convention Center. With thousands of developers, industry leaders, researchers, and...
Video Series: Getting Started with Universal Scene Description (OpenUSD)
Gain a foundational understanding of USD, the open and extensible framework for creating, editing, querying, rendering, collaborating, and simulating within 3D...
Perception Model Training for Autonomous Vehicles with Tensor Parallelism
Due to the adoption of multicamera inputs and deep convolutional backbone networks, the GPU memory footprint for training autonomous driving perception models...
Developing Virtual Factory Solutions with OpenUSD and NVIDIA Omniverse
With NVIDIA AI, NVIDIA Omniverse, and the Universal Scene Description (OpenUSD) ecosystem, industrial developers are building virtual factory solutions that...
Developing Production-Ready AI Sensor Processing Applications with NVIDIA Holoscan 1.0
Edge AI developers are building AI applications and products for safety-critical and regulated use cases. With NVIDIA Holoscan 1.0, these applications can...
NVIDIA cuOpt is an accelerated optimization engine for solving complex routing problems. It efficiently solves problems with different aspects such as breaks,...
Scale AI-Enabled Robotics Development Workloads with NVIDIA OSMO
Autonomous machine development is an iterative process of data generation and gathering, model training, and deployment characterized by complex multi-stage,...
Make the Most of NVIDIA GTC 2024 with In-Person, Hands-On Learning
We are so excited to be back in person at GTC this year at the San Jose Convention Center. With thousands of developers, industry leaders, researchers, and...
Detecting Real-Time Waste Contamination Using Edge Computing and Video Analytics
The past few decades have witnessed a surge in rates of waste generation, closely linked to economic development and urbanization. This escalation in waste...
Webinar: Accelerate Edge AI Development With NVIDIA Metropolis Microservices For Jetson
On March 5, 8am PT, learn how NVIDIA Metropolis microservices for Jetson Orin helps you modernize your app stack, streamline development and deployment, and...
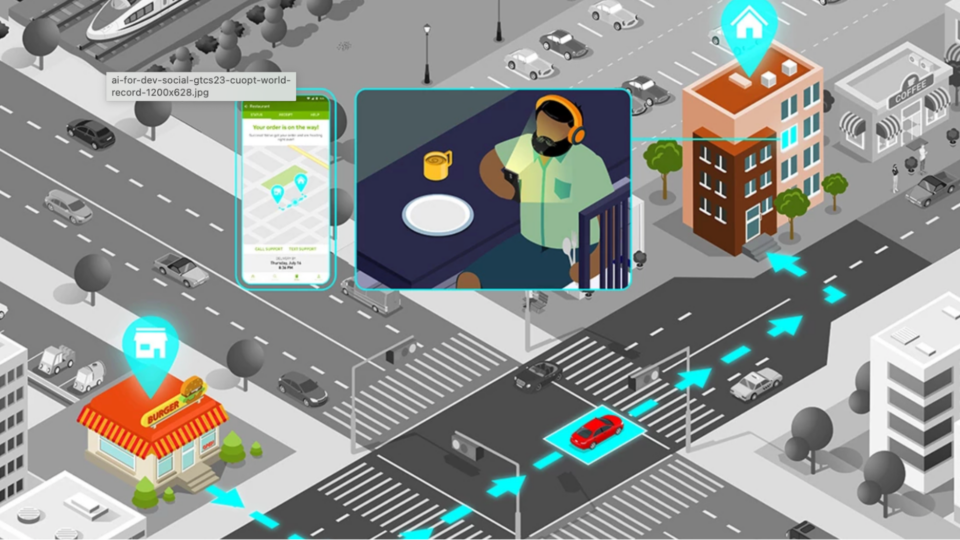
Experience NVIDIA cuOpt Accelerated Optimization to Boost Operational Efficiency
This week’s model release features NVIDIA cuOpt, a world-record-breaking accelerated optimization engine that helps teams solve complex routing problems and...
Enhanced DU Performance and Workload Consolidation for 5G/6G with NVIDIA Aerial CUDA-Accelerated RAN
Aerial CUDA-Accelerated radio access network (RAN) enables acceleration of telco workloads, delivering new levels of spectral efficiency (SE) on a cloud-native...
Developing Production-Ready AI Sensor Processing Applications with NVIDIA Holoscan 1.0
Edge AI developers are building AI applications and products for safety-critical and regulated use cases. With NVIDIA Holoscan 1.0, these applications can...
Powering Mission-Critical AI at the Edge with NVIDIA AI Enterprise IGX
NVIDIA SDKs have been instrumental in accelerating AI applications across a spectrum of use cases spanning smart cities, medical, and robotics. However,...
Accelerating the Future of Wireless Communication with the NVIDIA 6G Developer Program
6G will make the telco network AI-native for the first time. To develop 6G technologies, the telecom industry needs a whole new approach to research. The...
Spotlight: Honeywell Accelerates Industrial Process Simulation with NVIDIA cuDSS
For over a decade, traditional industrial process modeling and simulation approaches have struggled to fully leverage multicore CPUs or acceleration devices to...
Hear from Amdocs, Indosat, KT, NTT, ServiceNow, Singtel, SoftBank, and Verizon, plus a special address from NVIDIA at GTC. Explore AI transforming customer...
Detecting Real-Time Waste Contamination Using Edge Computing and Video Analytics
The past few decades have witnessed a surge in rates of waste generation, closely linked to economic development and urbanization. This escalation in waste...
Top Computer Vision/Video Analytics Sessions at NVIDIA GTC 2024
Discover the transformative power of computer vision and video analytics at GTC. Dive into cutting-edge techniques such as vision transformers, AI agents,...
Webinar: Accelerate Edge AI Development With NVIDIA Metropolis Microservices For Jetson
On March 5, 8am PT, learn how NVIDIA Metropolis microservices for Jetson Orin helps you modernize your app stack, streamline development and deployment, and...
Emulating the Attention Mechanism in Transformer Models with a Fully Convolutional Network
The past decade has seen a remarkable surge in the adoption of deep learning techniques for computer vision (CV) tasks. Convolutional neural networks (CNNs)...
Announcing NVIDIA Metropolis Microservices for Jetson for Rapid Edge AI Development
Building vision AI applications for the edge often comes with notoriously long and costly development cycles. At the same time, quickly developing edge AI...
Announcing Confidential Computing General Access on NVIDIA H100 Tensor Core GPUs
NVIDIA launched the initial release of the Confidential Computing (CC) solution in private preview for early access in July 2023 through NVIDIA LaunchPad....
Democratizing AI Workflows with Union.ai and NVIDIA DGX Cloud
GPUs were initially specialized for rendering 3D graphics in video games, primarily to accelerate linear algebra calculations. Today, GPUs have become one of...
Advancing Cell Segmentation and Morphology Analysis with NVIDIA AI Foundation Model VISTA-2D
Genomics researchers use different sequencing techniques to better understand biological systems, including single-cell and spatial omics. Unlike single-cell,...
Enhanced DU Performance and Workload Consolidation for 5G/6G with NVIDIA Aerial CUDA-Accelerated RAN
Aerial CUDA-Accelerated radio access network (RAN) enables acceleration of telco workloads, delivering new levels of spectral efficiency (SE) on a cloud-native...
Measuring the GPU Occupancy of Multi-stream Workloads
NVIDIA GPUs are becoming increasingly powerful with each new generation. This increase generally comes in two forms. Each streaming multi-processor (SM), the...
Advancing Medical Image Decoding with GPU-Accelerated nvImageCodec
This post delves into the capabilities of decoding DICOM medical images within AWS HealthImaging using the nvJPEG2000 library. We'll guide you through the...
How Generative AI is Empowering Climate Tech with NVIDIA Earth-2
In the context of global warming, NVIDIA Earth-2 has emerged as a pivotal platform for climate tech, generating actionable insights in the face of increasingly...
Next-Generation Live Media Apps on Repurposable Clusters with NVIDIA Holoscan for Media
NVIDIA Holoscan for Media is now available to all developers looking to build next-generation live media applications on fully repurposable clusters. ...
Efficient CUDA Debugging: Using NVIDIA Compute Sanitizer with NVIDIA Tools Extension and Creating Custom Tools
NVIDIA Compute Sanitizer is a powerful tool that can save you time and effort while improving the reliability and performance of your CUDA applications....
Develop Custom Enterprise Generative AI with NVIDIA NeMo
Generative AI is transforming computing, paving new avenues for humans to interact with computers in natural, intuitive ways. For enterprises, the prospect of...