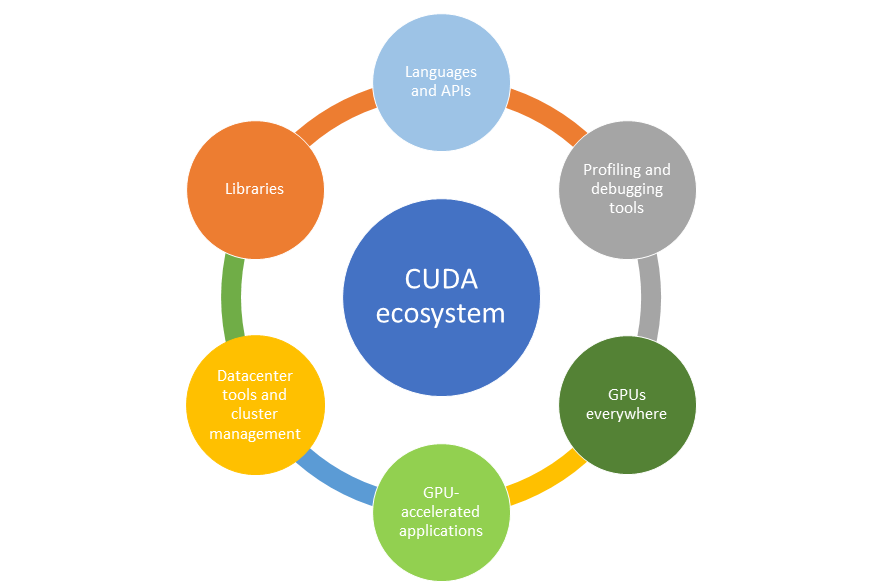
You may already know NVIDIA Tesla as a line of GPU accelerator boards optimized for high-performance, general-purpose computing. They are used for parallel scientific, engineering, and technical computing, and they are designed for deployment in supercomputers, clusters, and workstations. But it’s not just the GPU boards that make Tesla a great computing solution. The combination of the world’s fastest GPU accelerators, the widely used CUDA parallel computing model, and a comprehensive ecosystem of software developers, software vendors, and data center system OEMs make Tesla the leading platform for accelerating data analytics and scientific computing.
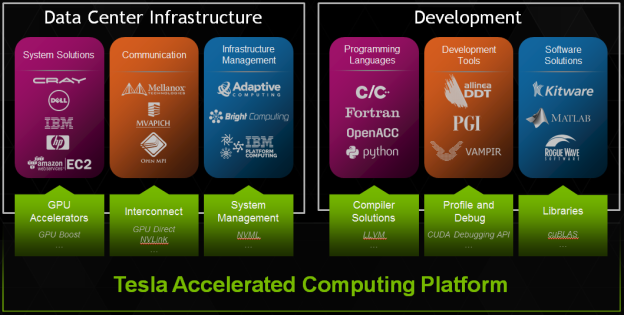 The Tesla Accelerated Computing Platform provides advanced system management features and accelerated communication technology, and it is supported by popular infrastructure management software. These enable HPC professionals to easily deploy and manage Tesla accelerators in the data center. Tesla-accelerated applications are powered by CUDA, NVIDIA’s pervasive parallel computing platform and programming model, which provides application developers with a comprehensive suite of tools for productive, high-performance software development.
The Tesla Accelerated Computing Platform provides advanced system management features and accelerated communication technology, and it is supported by popular infrastructure management software. These enable HPC professionals to easily deploy and manage Tesla accelerators in the data center. Tesla-accelerated applications are powered by CUDA, NVIDIA’s pervasive parallel computing platform and programming model, which provides application developers with a comprehensive suite of tools for productive, high-performance software development.
This post gives an overview of the broad range of technologies, tools, and components of the Tesla Accelerated Computing Platform that are available to application developers. Here’s what you need to know about the Tesla Platform.
1. Tesla is Available on All Server Platforms: x86, ARM & POWER
Tesla is the only platform for accelerated computing on systems based on all major CPU architectures: x86, ARM64, and POWER. But you don’t need to install your own HPC facilities to run on Tesla GPUs; cloud-based applications can use CUDA for acceleration on the thousands of Tesla GPUs available in the Amazon cloud.
2. Develop on GeForce, Deploy on Tesla
The CUDA parallel computing platform is supported by all NVIDIA GPUs, from our mobile Tegra K1 GPU to the fastest GeForce desktop GPU, to our high-end Quadro and Tesla GPUs. This means that you can develop high-performance applications that use CUDA on your GeForce laptop, or on an Apple iMac or Macbook Pro, and deploy them on the fastest Tesla GPUs running in high-end workstations or even on clusters and supercomputers.
3. The Tesla Platform Provides Powerful System Management Features
The Tesla platform includes comprehensive system management tools to simplify GPU administration, monitor health and other metrics, and improve resource utilization and efficiencies. Many of the HPC industry’s most popular and powerful cluster and infrastructure management tools use NVIDIA system management APIs to support GPUs, including IBM Platform HPC, PBS Works, Bright Cluster Manager, Ganglia, Adaptive Computing Moab HPC Suite and TORQUE Resource Manager.
NVIDIA Management Library (NVML) is a GPU state monitoring and management API with C and Python interfaces. Developers and system administrators can use NVML to monitor temperature, fan speeds, board power draw, resource utilization, ECC error counts, clock speeds, and other metrics, and manage GPU states such as ECC, compute process exclusivity, driver persistence, and power capping.
nvidia-smi is a cross-platform command-line tool with capabilities similar to NVML that provides GPU monitoring and management at a node level.
NVIDIA-Healthmon is a diagnostic tool for system administrators to detect and troubleshoot common GPU problems, including hardware, software, system configuration and other issues.
The NVIDIA Documentation Portal provides comprehensive API references and user guides.
4. Tesla and Quadro Provide Accelerated Communication Technology
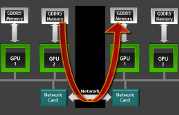 The Tesla platform supports high-bandwidth, low-latency communication for GPU-accelerated clusters and workstations. Using GPUDirect, 3rd party network adapters, solid-state drives (SSDs) and other devices can directly read and write CUDA host and device memory. GPUDirect eliminates unnecessary system memory copies, dramatically lowers CPU overhead, and reduces latency, resulting in significant performance improvements in data transfer times for applications running on NVIDIA Tesla™ and Quadro™ products. CUDA-aware MPI implementations such as MVAPICH and OpenMPI provide accelerated message passing that supports efficient transfers between GPU memory across cluster nodes.
The Tesla platform supports high-bandwidth, low-latency communication for GPU-accelerated clusters and workstations. Using GPUDirect, 3rd party network adapters, solid-state drives (SSDs) and other devices can directly read and write CUDA host and device memory. GPUDirect eliminates unnecessary system memory copies, dramatically lowers CPU overhead, and reduces latency, resulting in significant performance improvements in data transfer times for applications running on NVIDIA Tesla™ and Quadro™ products. CUDA-aware MPI implementations such as MVAPICH and OpenMPI provide accelerated message passing that supports efficient transfers between GPU memory across cluster nodes.
Earlier this year NVIDIA announced NVLink, a next-generation, high-bandwidth interconnect for CPUs and GPUs. Learn more about NVLink in this Parallel Forall post.
5. The Tesla Platform is Powered by CUDA
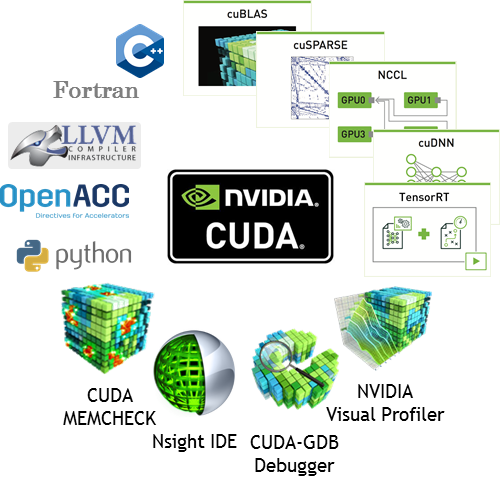
The foundation for developing software applications that leverage the Tesla platform is CUDA, NVIDIA’s parallel computing platform and parallel programming model. CUDA provides developers with a flexible path to application acceleration, supporting multiple development approaches. The easiest approach is usually to use GPU-accelerated libraries to get drop-in acceleration for linear algebra, Fast Fourier Transforms, linear equation solvers, and a variety of other computations. To accelerate existing C, C++ and Fortran code, programmers can use OpenACC compiler directives to automatically parallelize loops. And for the highest performance on the widest range of code, developers can design their own parallel algorithms and implement them in programming languages they already know.
6. GPU-Accelerated Libraries Offer Drop-in Acceleration
Adding GPU-acceleration to your application can be as easy as calling a library function, and several even have interfaces compatible with the CPU-only libraries you already use, for drop-in acceleration. There is an extensive list of GPU-accelerated libraries from NVIDIA as well as other providers. Libraries from NVIDIA include the following.
 AmgX is an Algebraic Multigrid (AMG) solver that provides up to 10x acceleration to the computationally intense linear solver portion of simulations, and is especially well suited for implicit unstructured methods.
AmgX is an Algebraic Multigrid (AMG) solver that provides up to 10x acceleration to the computationally intense linear solver portion of simulations, and is especially well suited for implicit unstructured methods.- cuDNN is a GPU-accelerated library of primitives for deep neural networks, designed for integration into higher-level machine learning frameworks.

- cuBLAS, cuBLAS-XT, and nvBLAS are GPU implementations of the Basic Linear Algebra Subroutines interface. cuBLAS-XT provides multi-GPU scaling of level 3 BLAS routines, and nvBLAS provides a drop-in replacement for CPU-only BLAS libraries.
- cuFFT provides a simple interface for computing Fast Fourier Transforms up to 10x faster than the CPU
- cuSPARSE provides a collection of basic linear algebra subroutines for sparse matrix algebra that delivers over 8x performance boost compared to CPU-only implementations.
- cuRAND performs high-quality GPU-accelerated random number generation (RNG) over 8x faster than typical CPU only code.
- Thrust is an expressive, high-level open source C++ template library of parallel algorithms and data structures that resembles the C++ Standard Template Library. Thrust lets you easily design complex collection-oriented parallel algorithms based on primitives such as sort, scan, transform, and parallel reduction.

- NVIDIA Performance Primitives is a GPU accelerated library with a very large collection of 1000’s of image processing primitives and signal processing primitives.
- NVBIO is a GPU-accelerated C++ framework for High-Throughput Genetic Sequence Analysis for both short and long read alignment.
There are also many powerful libraries available from third parties, including general-purpose libraries like ArrayFire (an easy-to-use array-based library available for multiple languages), optimized linear algebra libraries like MAGMA (provides GPU-accelerated LAPACK and BLAS routines), and domain-specific libraries such as the machine learning frameworks Caffe and Torch7.
7. GPU-Accelerated Programming Languages offer Maximum Flexibility
You don’t have to learn a new programming language to develop applications for the Tesla platform, because GPU programming and CUDA are accessible from the most popular programming languages.
OpenACC offers a simple, high-level, portable, and non-invasive approach to application acceleration. OpenACC provides compiler directives to specify loops and regions of code in standard C, C++ and Fortran to be offloaded from a host CPU to an attached accelerator. OpenACC is designed for portability across operating systems, host CPUs, and a range of accelerators, including APUs, GPUs, and many-core coprocessors. The directives and programming model of OpenACC allow programmers to create high-level host+accelerator programs without the need to explicitly initialize the accelerator or manage data or program transfers between the host and accelerator. OpenACC is available today in compilers from The Portland Group and Cray, and there is work in progress to add OpenACC support to GCC.
The CUDA programming model can be accessed directly through programming language extensions, enabling you to design and implement your own parallel algorithms in C, C++, Fortran, Python, MATLAB, and other popular programming languages.
You can develop C and C++ software that uses the CUDA programming model with the CUDA Toolkit, available free from NVIDIA. The CUDA Toolkit is available on Windows, Linux, and Mac OS for x86, ARM, and POWER based systems. It includes the nvcc compiler tool chain, NVIDIA libraries, comprehensive developer tools, documentation, and code examples.
Fortran users can program using PGI CUDA Fortran. Python users can program CUDA in Python syntax using the Numba open source Python compiler or the Numba Pro compiler from Continuum Analytics. MATLAB users can program GPUs using the MATLAB Parallel Computing Toolbox™.
In a recent Parallel Forall blog post, IBM presented three ways they are working to provide CUDA acceleration to Java applications: CUDA4J, a CUDA API interface for Java; built-in GPU acceleration of Java SE library APIs such as sorting; and just-in-time compilation of arbitrary Java code for GPUs.
8. Powerful Development Tools Help You Optimize and Debug
Understanding how your application is using the GPU is crucial to identifying opportunities for performance optimization. Debugging tools are crucial to pinpointing the cause of program failures and issues. Performance analysis tools are important for profiling applications to understand GPU performance limiters, and also for identifying performance bottlenecks in your CPU code that can be eliminated by moving computationally intensive algorithms to the GPU. NVIDIA provides a growing suite of developer tools as part of the CUDA Toolkit, and there are a number of professional debugging and profiling tools available from other vendors.
NVIDIA® Nsight™ provides powerful debugging and profiling tools integrated into a powerful, CUDA-aware integrated development environments (IDE). NVIDIA® Nsight™ Visual Studio Edition for Windows integrates with Microsoft Visual Studio, and Nsight™ Eclipse Edition is a standalone IDE for Linux and Mac OS.
provides powerful debugging and profiling tools integrated into a powerful, CUDA-aware integrated development environments (IDE). NVIDIA® Nsight™ Visual Studio Edition for Windows integrates with Microsoft Visual Studio, and Nsight™ Eclipse Edition is a standalone IDE for Linux and Mac OS.
The NVIDIA Visual Profiler (nvvp) is a cross-platform performance profiling tool that delivers developers vital feedback for optimizing CUDA C/C++, and Fortran applications. Nvvp provides automated performance analysis, a unified CPU/GPU timeline, CUDA API Trace tools, ability to drill down to raw execution data, the ability to compare across multiple sessions, and much more.
Nvprof is a command-line profiler available for Linux, Windows, and OS X which provides many of the features of the NVIDIA Visual Profiler in a handy command-line application.
CUDA-GDB delivers a seamless debugging experience that allows you to debug both the CPU and GPU portions of your application simultaneously on Linux or Mac OS X. CUDA-GDB provides a console-based debugging interface you can use from the command line and it is compatible with multiple GDB GUI frontends.
CUDA-MEMCHECK detects illegal memory accesses, parallel race conditions, and runtime execution errors in your GPU code and allows you to locate them quickly.
The CUDA Toolkit also includes tools for manipulating and inspecting compiled GPU program and library binary files. cuobjdump extracts information (such as assembly language, string tables, and headers) from CUDA binary files (both standalone and those embedded in host binaries) and presents them in human readable format. nvdisasm extracts the same information from standalone CUDA binary files, but can display richer information about it, such as control flow analysis. nvprune prunes host object files and libraries to only contain device code for the specified architecture targets.
In addition to the NVIDIA developer tools suite, there are also a number of third-party developer tools that integrate GPU support into popular debugging and profiling tools.
Allinea DDT provides application developers with a single tool that can debug hybrid MPI, OpenMP and CUDA applications on a single workstation or GPU cluster.
TotalView is a GUI-based tool that allows you to debug one or many processes/threads with complete control over program execution, from basic debugging operations like stepping through code to concurrent programs that take advantage of threads, OpenMP, MPI, or GPUs.
TAU Performance System® is a profiling and tracing toolkit for performance analysis of hybrid parallel programs written in CUDA C/C++ and OpenACC.
VampirTrace performance monitor gives detailed insight into the runtime behavior of accelerators, enabling extensive performance analysis and optimization of hybrid programs written in CUDA C/C++ and PyCUDA.
The PAPI CUDA Component provides a hardware performance counter measurement access to the hardware counters inside the GPU, integrating detailed performance counter information regarding the execution of GPU kernels into the Performance Application Programming Interface.
9. The Tesla Platform Provides APIs for Language and Tools Developers
The Tesla platform provides APIs for targeting GPUs from general-purpose or domain-specific programming languages, and for adding GPU support to software tools.
NVIDIA’s CUDA Compiler (NVCC) is based on the widely used LLVM open-source compiler infrastructure. Developers can create or extend programming languages with support for GPU acceleration using the NVIDIA Compiler SDK. NVIDIA has worked with the LLVM organization to contribute the CUDA compiler source code changes to the LLVM core and parallel thread execution backend, enabling full support of NVIDIA GPUs.
The NVIDIA CUDA Profiling Tools Interface (CUPTI) provides performance analysis tools with hardware performance counters and detailed information about how applications are using the GPUs in a system.
The CUDA Debugger API enables debugging tools to provide detailed debugging support of CUDA-based applications.
10. Learn How to Develop GPU-Accelerated Applications
Comprehensive documentation for the CUDA APIs and programming model, as well as all the other developer tools, system management tools and APIs supporting the Tesla Platform, is available at docs.nvidia.com. 
If you are new to parallel computing, I highly recommend the free interactive online course Introduction to Parallel Programming: Using CUDA to Harness the Power of GPUs available from Udacity, taught by David Luebke from NVIDIA, and Professor John Owens from the University of California Davis.
A variety of short, hands-on training labs for CUDA, OpenACC, MATLAB, GPU-accelerated libraries, and other topics are available at nvidia.qwiklab.com. Since these labs are hosted in the cloud, no GPU or special software is required—all you need is a supported web browser.
If you have questions, there is a great community of GPU programmers and NVIDIA employees who ask and answer questions on the NVIDIA DevTalk forums as well as on StackOverflow.
11. Here’s Where to Find Consulting & Training Services
A growing list of international authorized NVIDIA partners offer consulting and training services related to GPU computing on the NVIDIA Tesla platform.
12. Get Enterprise-Class Support and Maintenance for Tesla
NVIDIA Enterprise Support delivers enterprise-class support and maintenance for the Tesla Platform. Enterprise Support is for those who require a higher level of support than the community-supported DevTalk forums, or who need issues resolved in the software version they are already using through regular maintenance releases and, when needed, escalated hotfix releases.
Get Started Today
Joining the CUDA registered developer program is your first step in establishing a working relationship with NVIDIA Engineering. Membership gives you access to the latest software releases and tools, notifications about special developer events and webinars, and access to report bugs and request new features.
Visit the Tesla Accelerated Computing Platform page for the latest information, and visit our getting started page to learn about all the ways to get started developing software for GPUs.