Computational Fluid Dynamics (CFD) is a valuable tool to study the behavior of fluids. Today, many areas of engineering use CFD. For example, the automotive industry uses CFD to study airflow around cars, and to optimize the car body shapes to reduce drag and improve fuel efficiency. To get accurate results in fluid simulation it is necessary to capture complex phenomena such as turbulence, which requires very accurate models. These complex models result in very long computing times. In this post I describe how I used OpenACC to accelerate the ZFS C++ CFD solver with NVIDIA Tesla GPUs.
The ZFS flow solver
The C++ flow solver ZFS (Zonal Flow Solver) is developed at the Institute of Aerodynamics at RWTH Aachen, Germany. ZFS solves the unsteady Navier-Stokes equations for compressible flows on automatically generated hierarchical Cartesian grids with a fully-conservative second-order-accurate finite-volume method [1, 2, 3]. To integrate the flow equations in time ZFS uses a 5-step Runge-Kutta method with dual time stepping [2]. It imposes boundary conditions using a ghost-cell method [4] that can handle multiple ghost cells [5, 6]. ZFS supports complex moving boundaries which are sharply discretized using a cut-cell type immersed-boundary method [1, 2, 7].
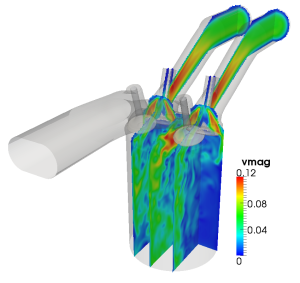
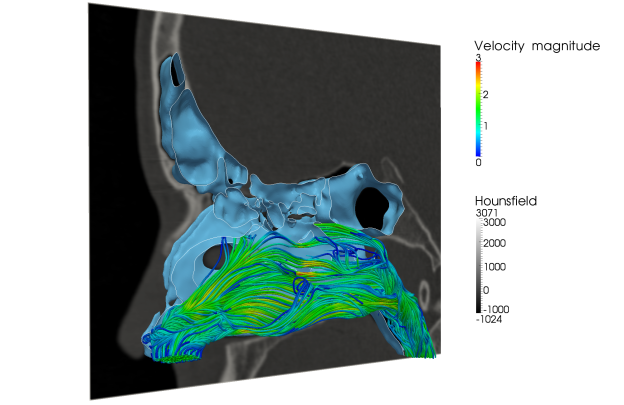
Among other topics, scientists have used ZFS to study the flow within an internal combustion engine with moving pistons and valves, as Figure 1 shows. Figure 2 shows how the Lattice-Boltzmann solver in ZFS was used to better understand airflow within the human nasal cavity.
Accelerating ZFS with OpenACC
To accelerate ZFS with OpenACC we applied the APOD process: Assess, Parallelize, Optimize, Deploy. For this process we focused on the test case 3D_Cube_MP, which uses finite volume methods to simulate the laminar flow in a 3D Cube. ZFS has a large code base (191800 lines of code excluding comments) so porting the entire application is a significant effort. However, a typical usage scenario executes many simulations on variants of a single input set, and these simulations often only exercise a small fraction of the code base. Therefore, accelerating the portions of the code relevant for a single case can be done with reasonable effort which often pays off quickly. For example, accelerating the relevant portions of the code for our 3D_Cube_MP test case took me about 2 weeks of work achieving a speedup of 2.78x on the main loop (comparing 8 3.0 GHz Intel Xeon E5-2690 v2 CPUs to 8 875 MHz NVIDIA Tesla K40 GPUs).
ZFS uses MPI to run in parallel on multiple CPU cores and nodes of a CPU cluster. The OpenACC version of ZFS starts one MPI rank per GPU and scales across multiple GPUs in a cluster. For brevity and clarity this post only describes the single-GPU case because the extra work for the multi-GPU case was minimal.
Assess
To understand the run-time behavior of ZFS and identify the most time-consuming parts, I started by profiling the CPU version, using Callgrind (but any CPU profiler will do). To create the profile I executed ZFS with callgrind, using following command line with the --fn-skip option to ignore initialization.
valgrind --tool=callgrind --fn-skip='*initMethods*' --fn-skip='*initSolutionStep*' zfs
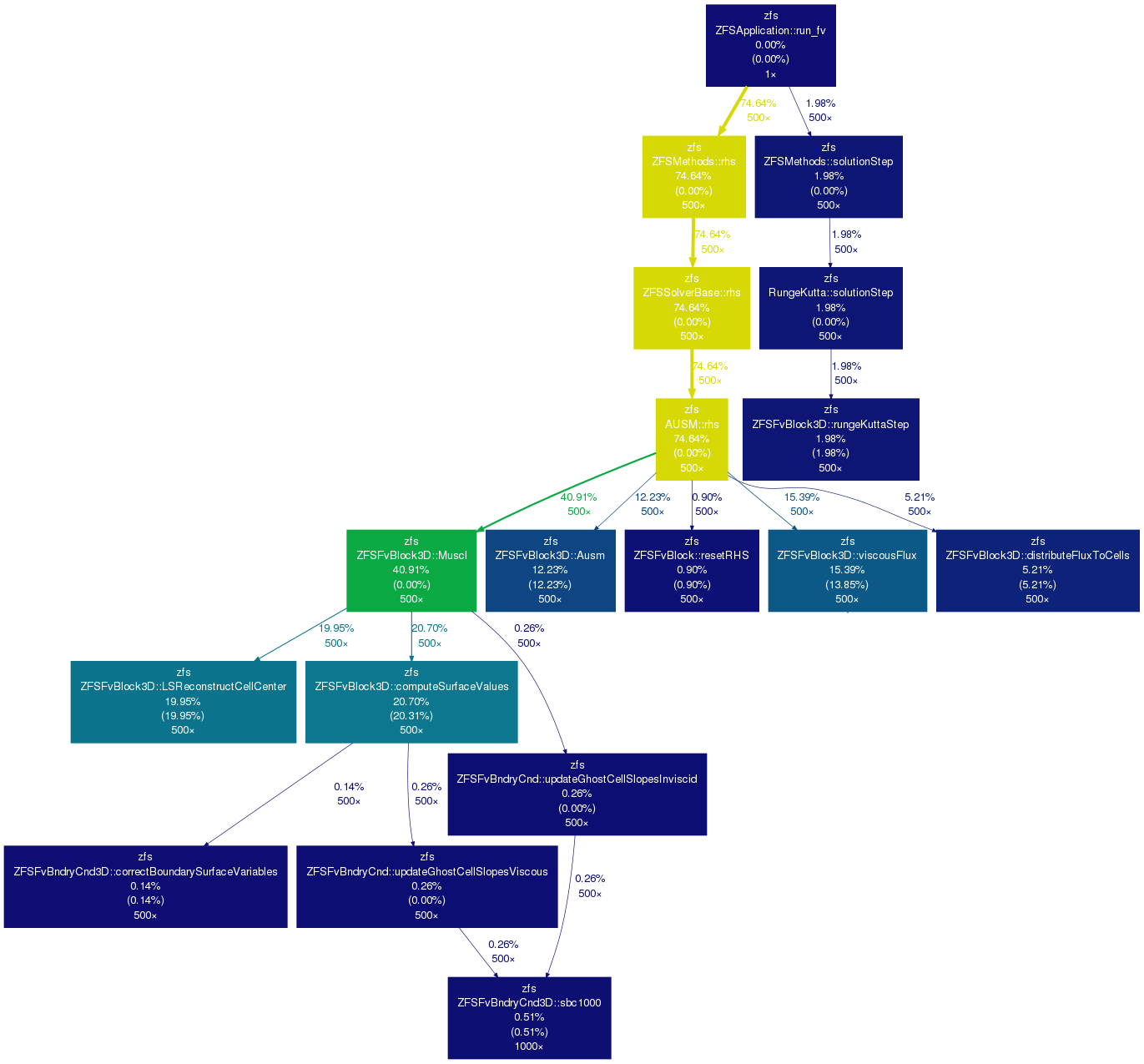
I used Gprof2Dot to visualize the call-grind profile, using the following command line. This created the call tree shown in Figure 3.
gprof2dot.py -f callgrind -s -n 0.0 -z "ZFSApplication::run_fv()" callgrind.out.12087 | dot -Tpng -o zfs_profile.png
Parallelize
To expose parallelism I applied the OpenACC #pragma acc parallel loop directive to incrementally accelerate the most time-consuming methods shown in the profile I obtained in the Assess step. The incremental approach allowed me to check the results frequently and identify introduced bugs early. However, the incremental approach has the drawback that all data that is either read or modified by a method must be copied to the accelerator at the beginning of the method and copied back to the host at the end.
These copies impact performance significantly, so I used a small input set until I had accelerated all methods. At that point, I introduced a #pragma acc data region surrounding all the accelerated methods to eliminate unnecessary data movement. To avoid changing all the previously introduced data directives on the individual methods, I used the present_or_copyin and present_or_copyout (note: I use the shorthand pcopy/pcopyout) clauses instead of the copyin/copyout clauses, as the following excerpt shows.
#pragma acc data pcopyin( surfaceVars[0:surfaceVarMemory*noSurfaces], orientations[0:noSurfaces], area[0:noSurfaces], factor[0:2*noSurfaces], nghbrCellIds[0:2*noSurfaces], slope[0:noCells*noSlopes] ) pcopyout( fluxes[0:noSurfaces*noVars] )
{
#pragma acc parallel loop
for( ZFSUint srfcId = 0; srfcId < noSurfaces; srfcId++ ) {
...
}
}
During porting, cuda-memcheck was very helpful in identifying incorrectly specified array slices in the copy clauses. An undersized array slice results in out of bounds access which cuda-memcheck can easily identify in code compiled with debug information.
Most of the methods I accelerated contained for loops with independent loop iterations so #pragma acc parallel loop was enough to accelerate them. But two of the methods required me to choose different strategies.
Avoiding Race Conditions
ZFSFvBlock3D::distributeFluxToCells adds the flux over the surfaces to the neighboring cells. The original version looped over all surfaces pushing the flux to the two adjacent cells. Since each cell has up to 6 surfaces, executing this in parallel would lead to invalid results.
for (ZFSUint srfcId = 0; srfcId < noSurfaces; ++srfcId ) {
const ZFSUint offset0 = nghbrCellIds[ srfcId*2 ] * noVars;
const ZFSUint offset1 = nghbrCellIds[ srfcId*2 + 1 ] * noVars;
const ZFSUint fluxOffset = srfcId * noVars;
const ZFSFloat *const __restrict flux = fluxes + fluxOffset;
ZFSFloat *const __restrict rhs0 = rhs + offset0;
ZFSFloat *const __restrict rhs1 = rhs + offset1;
for(ZFSUint var = 0; var < noVars; ++var) {
const ZFSFloat tmp = flux[var];
rhs0[var] += tmp;
rhs1[var] -= tmp;
}
}
To work around the potential race condition I reconstructured the loop to handle only one orientation and side of a surface at a time, resulting in the following code.
for(ZFSUint side = 0; side < 2; ++side) { // for each surface side one iteration
const ZFSFloat factor = (side == 0) ? 1.0 : -1.0;
for(ZFSId d = 0; d < m_spaceDimensions; ++d) { // for each orientation one iteration
#pragma acc parallel loop
for (ZFSUint srfcId = 0; srfcId < noSurfaces; ++srfcId ) {
if ( orientations[srfcId] == d ) { //this call only handles the orientation d
const ZFSUint offset = nghbrCellIds[ srfcId*2 + side ] * noVars;
const ZFSUint fluxOffset = srfcId * noVars;
const ZFSFloat *const __restrict flux = fluxes + fluxOffset;
ZFSFloat *const __restrict rhs_s = rhs + offset;
for(ZFSUint var = 0; var < noVars; ++var) {
const ZFSFloat tmp = flux[var];
rhs_s[var] += factor*tmp;
}
}
}
}
}
ZFSFvBlock3D::correctMasterCells gathers the values of so-called small cells to their master cell. A master cell has multiple associated small cells and a small cell knows its master cell but not the other way around; it is not possible to simply loop over the master cells and gather data from associated small cells. I solved this issue by using atomic memory operations, as in the following listing.
#pragma acc parallel loop collapse(2)
for( ZFSId s = 0; s < noSmallCells; s++ ) {
for( ZFSId varId = 0; varId < noVarIds; varId++ ) {
#pragma acc atomic
rhs[ masterCellIds[ s ] * noVarIds + varId ] += rhs[ smallCellIds[ s ] * noVarIds + varId ];
rhs[ smallCellIds[ s ] * noVarIds + varId ] = 0.0;
}
}
Later profiling revealed that the run time of this method is very small so the cost of colliding atomics does not affect the overall application performance.
Unstructured Data Regions
Once I had ported all methods to run on the GPU using OpenACC directives, data movements between the host and device became unnecessary. To avoid them, I introduced a data region around the time-stepping loop of ZFS. Because the C++ ZFS code encapsulates all data fields in objects, I could not express this with #pragma acc data directive available since the OpenACC 1.0. It required OpenACC 2.0 unstructured data regions: #pragma acc enter data and #pragma acc exit data.
Optimize
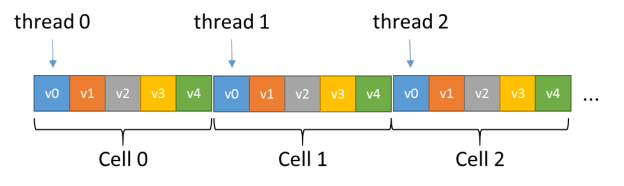
The guided analysis of the NVIDIA Visual Profiler revealed that memory access pattern affected performance of most kernels generated by the OpenACC compiler. ZFS uses a data layout optimized for architectures like CPUs with a large per-core private cache. Figure 4 shows the cell array organization.

This Array of Structures (AoS) layout leads to poor (large-stride) memory access patterns because for most loops OpenACC launches one GPU thread per cell as Figure 5 shows (See How to Access Global Memory Efficiently in CUDA C/C++ Kernels).
It is possible in principle to change the data layout to avoid strided access. For the most time-consuming method (ZFSFvBlock3D::computeSurfaceValues), I evaluated the performance effect of transposing the data to a Structure of Arrays (SoA) layout; this Kernel showed a 2.6x speed-up. Unfortunately, changing the data layout for the entire ZFS code base was not feasible in the scope of this project, so I chose an alternative approach. I significantly reduced the effect of strided memory accesses by using the texture cache and artificially reducing the occupancy.
Using the Texture Cache
The Kepler (GK110) architecture allows you to use the texture cache for read-only data without the need for texture references or texture objects. The instruction that enables this is LDG; it is exposed in CUDA C with the intrinsic __ldg. An OpenACC compiler may use this instruction if it knows that a pointer references read-only data and that the pointer cannot alias with other pointers to the same data. Declare a pointer const to tell the compiler that it references read-only data, and add the __restrict qualifier to guarantee that this is the only pointer to this data in the current scope. The following excerpt provides an example.
const ZFSFloat *const __restrict cells = ...
In ZFS, all pointers are already correctly decorated with const and __restrict qualifiers.
Reducing Occupancy
On Kepler up to 2048 Threads can run on a single SMX at full occupancy. ZFS optimizes its data layout for relatively large private caches, but these 2048 threads compete for only 12-48KB of texture cache, resulting in low cache hit rates. By artificially lowering the occupancy I increased the hit rate and the overall kernel performance. To lower the occupancy I made use of the fact that a Kepler SMX supports at most 16 simultaneously active blocks. Using only 32 threads per block limits the occupancy to 16*32/2048 = 25%. OpenACC allows you to control the block size using the vector clause, as shown in the following listing.
#pragma acc parallel loop gang vector(32)
for( ZFSUint srfcId = 0; srfcId < noSurfaces; srfcId++ ) {
...
}
gang vector(32) tells the OpenACC compiler to launch enough thread blocks (gang without argument) with 32 threads each (vector(32)) to cover the iteration space. I experimentally determined the optimal trade-off between occupancy and cache hit rate.
Final Results and conclusion
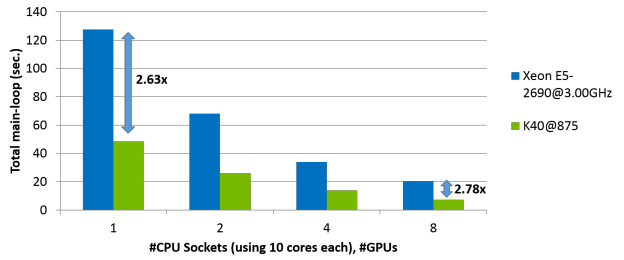
Figure 6 compares the run time of the CPU version of ZFS with the final OpenACC implementation, resulting in a speed-up of up to 2.78X (3D Cube MP 2.4M cells).
OpenACC allows significant acceleration of applications with a large code base with reasonable effort, and with further optimization work even more speed up is possible. This work has been carried out in the scope of the NVIDIA Application Lab @ Jülich in collaboration with the JARA-HPC SimLab Fluids & Solids Engineering and the Institute of Aerodynamics at RWTH Aachen.
Bibliography
[1] D. Hartmann, M. Meinke, and W. Schröder. A strictly conservative Cartesian cut-cell method for compressible viscous flows on adaptive grids. Computer Methods in Applied Mechanics and Engineering, 200:1038–1052, 2011.
[2] D. Hartmann, M. Meinke, and W. Schröder. An Adaptive Multilevel Multigrid Formulation for Cartesian Hierarchical Grid Methods. Computers & Fluids, 37:1103–1125, 2008.
[3] L. Schneiders, D. Hartmann, M. Meinke, and W. Schröder. An accurate moving boundary formulation in cut-cell methods. Journal of Computational Physics, 2012.
[4] D. Hartmann, M. Meinke, and W. Schröder. A General Formulation of Boundary Conditions on Cartesian Cut-Cells for Compressible Viscous Flow. In 19th AIAA Computational Fluid Dynamics, San Antonio, Texas, 22-25 June 2009. AIAA-2009-3878.
[5] C. Günther, D. Hartmann, M. Meinke, and W. Schröder. A level-set based cut-cell method for flows with complex moving boundaries. In ECCOMAS CFD Conference, Lisbon, Por- tugal, 14-17 June 2010.
[6] C. Günther, D. Hartmann, M. Meinke, and W. Schröder. A level-set based Cartesian grid method for the simulation of in-cylinder flow. In Notes on Numerical Fluid Mechanics and Multidisciplinary Design (NNFM): New Results in Numerical and Experimental Fluid Mechanics VIII, Springer, 2012.
[7] D. Hartmann, M. Meinke, and W. Schröder. A cartesian cut-cell solver for compressible flows. Computational Science and High Performance Computing IV, Note on Numerical Fluid Mechanics and Multidisciplinary Design, 115:363–376, 2011.