In finance, an option (or derivative) is the common name for a contract that, under certain conditions, gives a firm the right or obligation to receive or supply certain assets or cash flows. A financial firm uses options to hedge risks when it operates in the markets. It is critical for a firm to be able to accurately price those instruments and understand their dynamics to evaluate its positions, balance its portfolio and limit exposure to potential threats. The calculation of risk and prices for options is a computationally intensive task for which GPUs have a lot to offer. This post describes an efficient implementation of American Option Pricing using Monte Carlo Simulation with a GPU-optimized implementation of the Longstaff Schwarz algorithm.
NVIDIA recently partnered with IBM and STAC to implement the STAC-A2™ benchmark on two NVIDIA Tesla K20X GPUs. It is the first system that was able to calculate the risk and pricing of this particular complex option in less than a second. A system with two Tesla K20X GPUs is up to 6 times faster than a state-of-the-art configuration using only CPUs. Even more interestingly, adding one or two Tesla K20X GPUs to a system offers speedups of slightly more than 5x and 9x, respectively, compared to the same system without GPUs.

The STAC-A2 benchmark is a well-established suite of benchmarks and micro-benchmarks developed by banks to help compare the numerical quality, performance and scaling of different implementations of a standard method to price a complex American basket option and evaluate the Greeks. In a few words, an American option is a financial option which can be exercised at any moment before its expiry date. The Greeks are standard financial tools which measure the sensitivity of the price of the option to the variation of factors like the price of the underlying stock, the stock volatility or the risk free interest rate.
To price an option based on a basket of stocks, one has to be able to determine the price of the different stocks. Mathematically, the price of a stock can be modeled with complicated stochastic differential equations. In general, there exists no closed-form solution to those equations and their solution has to be evaluated numerically. Monte Carlo simulation is one such numerical technique to price stocks. It relies on the sampling of the stochastic differential equations for a large number of independent random input values. Our implementation uses cuRAND to generate those random values.
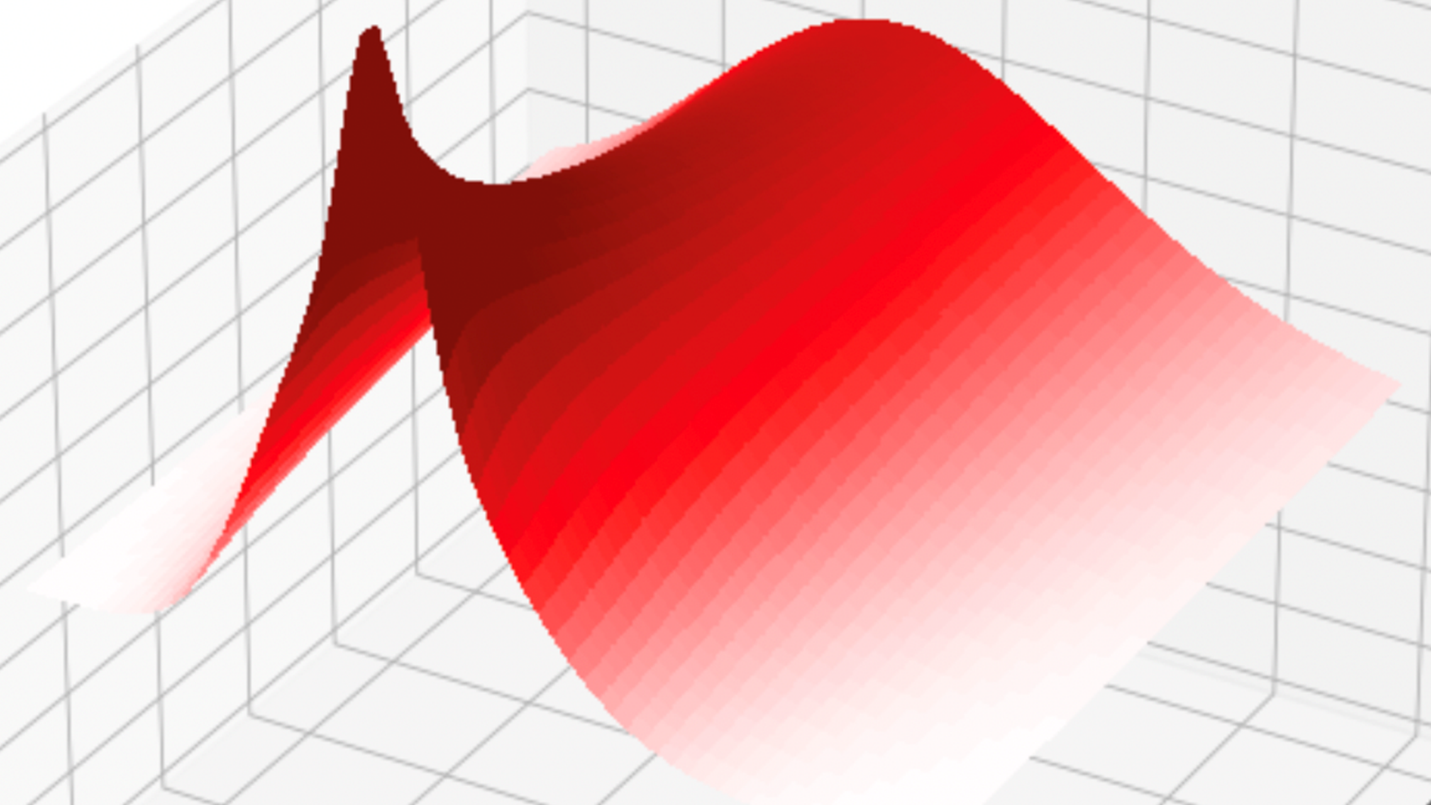
Path Discretization (Andersen-QE Scheme)
One popular mathematical model to describe the dynamics of a stock price is the Heston model, which captures the random nature of both the price of the stock and its volatility (i.e. its rate of change). Unfortunately, it is expensive to evaluate. We have developed an optimized implementation of the Andersen Quadratic Exponential (Andersen QE) scheme – one of the most robust discretizations of the Heston model for Monte Carlo simulation.
To reach a high level of performance, each CUDA thread generates a single Monte Carlo path of the Andersen QE scheme. This way all threads can work independently, which is the optimal configuration for parallelism. To further reduce the number of memory transactions to a minimum, the data structures (random samples, path storage, etc) are laid out to guarantee perfectly aligned and coalesced memory accesses.
However, Andersen QE presents a difficulty for efficient parallel implementations. Very roughly, the technique approximates a complex probabilistic distribution of the variance with simpler distributions. The choice of formulation depends on the values computed at the previous iteration and may differ from one path to another. This requires an if-then-else block at the heart of the main loop which consecutive threads may evaluate differently, resulting in costly branch divergence. Within a warp, the GPU multiprocessor has to execute each taken branch in sequence, so that the execution cost is the sum of the costs of the taken branches.
We have finely tuned each of the branches of this code and moved as much computation outside of the block as possible to improve the performance. The details of that code are available from STAC.
Option Pricing (Longstaff-Schwartz Algorithm)
Another key component of a Monte-Carlo simulation to price American options is the Longstaff-Schwartz algorithm. At each time step, this algorithm determines if one should exercise the option or hold it for later exercise. To perform such a task, the algorithm constructs a model to predict the expected gain or loss based on the current position. Fitting linear models to existing data is a common task in computer science and is known as linear regression. Our STAC-A2 implementation uses a hybrid method running a CPU-based Singular Value Decomposition (SVD) to perform the linear regression. The details are available from the STAC-A2 benchmark code.
In this blog post, we present a different implementation which runs entirely on the GPU. To maximize the performance of the linear regression we developed a technique which allows us to drastically reduce the amount of data transferred between the GPU memory and the compute cores. The algorithm starts by building a matrix decomposition for each of the time steps. Those precomputations are needed to perform the linear regression in the time-dependent loop. Since they are independent, we compute them in parallel and launch a block of GPU threads per time step, as shown in the following code excerpt.
// Prepare the decomposition. One CUDA block per timestep.
prepare_svd_kernel<<<num_timesteps, 256="">>>(...);
// Run the time-dependent loop.
for( int i = 0 ; i < num_timesteps ; ++i )
{
// Compute the coefficients beta which minimize ||Y - beta X||^2.
compute_partial_beta_kernel<<<>>>(...);
// Update the cashflow: Decide whether to early exercise or continue.
update_cashflow_kernel<<<>>>(...);
}
In order to explain the main idea to reduce memory transfers, we have to take a closer look at the SVD of a long-and-thin matrix—a matrix which has many more rows than columns. In our case, the matrix has 32,000 rows and 3 columns. The objective of the SVD is to extract three matrices such that their product is equal to the original matrix. Those three matrices have special properties which make them more suitable to efficient computations. Unfortunately, building the SVD of a long-and-thin matrix is rather costly.
However, there is a well-known method to reduce the cost of the SVD computation for long-and-thin matrices. It relies on a first factorization of the original matrix using another standard technique called the QR decomposition. That factorization produces two matrices Q and R such that R has very nice properties and is much smaller than the original matrix (in our case R has 3 rows and 3 columns). The SVD can be applied only to the R matrix and is much cheaper to compute. The SVD of the original matrix is then rebuilt from the SVD of R and the Q matrix. In our implementation, the SVD of R is computed by a single thread but requires no access to the GPU memory.
The challenging part of the algorithm is to build the QR decomposition with a limited number of memory transactions and to design the implementation in such a way that it can be performed by a single block of CUDA threads (and not exhaust all the multiprocessor resources). To achieve that objective we exploit the special structure of the original matrix to limit memory transfers. In more detail, the original matrix is a Vandermonde matrix; i.e. each of its rows is built from consecutive powers (0, 1 and 2) of a single value (the stock price on the path). A symbolic computation shows that the R matrix of the QR decomposition can be expressed in terms of 5 sums of different powers and 3 additional terms (so a total of 8 terms). These terms can easily be computed using a simple parallel reduction. The following code fragments shows how the sums are evaluated (for simplicity we exclude the detection of the three additional terms):
// Sums.
int m = 0; double4 sums = { 0.0, 0.0, 0.0, 0.0 };
// Iterate over the paths. Each thread computes its own set of sums.
for(int path = threadIdx.x; path < num_paths; path += THREADS_PER_BLOCK)
{
// Load the asset price and determine if it pays off.
double S = 0.0;
if( path < num_paths )
S = paths[offset + path];
// Update the number of paths which are in the money or nullify S.
if( payoff.is_in_the_money(S) )
++m;
else
S = 0.0;
double S2 = S*S;
// Update the sums.
sums.x += S;
sums.y += S2;
sums.z += S2*S;
sums.w += S2*S2;
}
// Number of elements in the money (S^0).
m = cub::BlockReduce<...>(smem_storage.for_reduce1).Sum(m);
// Sums of powers (sum S^1, sum S^2, sum S^3 and sum S^4).
sums = cub::BlockReduce<...>(smem_storage.for_reduce4).Sum(sums);
As shown in that code fragment, our implementation makes an extensive use of the CUB library which offers very fast implementations of GPU primitives.
Once we have computed those 8 terms, we are able to build the R matrix and compute its SVD on the multiprocessor without any further communication with the GPU memory. In total, each SVD can be built by reading the asset prices only once. The matrix Q (of the QR decomposition) is not computed at this step. It is actually rebuilt on the multiprocessor during the time dependent loop at almost no cost (the cost of a simple 3×3 triangular solve). This way, we spare a lot of memory resources by not storing Q explicitly and by saving transfers from the GPU memory to the compute core.
On a Tesla K40 running at 3004MHz (memory) and 875MHz (SM), our implementation of the Longstaff-Schwartz algorithm prices an American option on 32,000 paths and 100 time steps in less than 3ms. The complete time, including the paths generation (using a simple discretization and assuming a constant volatility), is less than 5.5ms.
Conclusion
Our STAC-A2 benchmark code and this implementation of the Longstaff-Schwartz algorithm both illustrate how NVIDIA GPUs can make option pricing and risk analysis much faster. To learn more about GPUs and how accelerate financial applications, join us during the finance sessions at GTC 2014. I will give a presentation about this work and experts in finance will present their latest accomplishments.
The source code of this implementation of the Longstaff-Schwartz algorithm is available here.
Image by Luis Villa del Campo from Madrid, Spain (Times Square – NASDAQ), via Wikimedia Commons.