Back in January I wrote a post about the public beta availability of AmgX, a linear solver library for large-scale industrial applications. Since then, AmgX has grown up! Now we can solve problems that were impossible for us before, due to the addition of “classical” Algebraic Multi-Grid (often called Ruge-Stueben AMG). V1.0 comes complete with classical AMG multi-GPU support, greatly improved scalability, and we have some nice performance numbers to back it up.
Models of Flow


One specific class of problem has eluded us, until now. In the oil and gas industry, reservoir simulation is used to predict the behavior of wells producing from large hydrocarbon deposits, and more recently from shale gas or shale oil fields. These problems are models of flow through porous media, coupled with flow through networks of fractures, piping and processing equipment, but it is the media that makes all the difference. Oil and gas deposits aren’t like big caves with lakes of oil, they are more like complex, many-layered sponges, each with different pore sizes, stiffness and hydrocarbon content.
The flow is dominated by the interaction of pressure forces with the local and global characteristics of the media, and worst of all, we really don’t even know the exact configuration. There is no way to measure the properties of the rocks except by drilling cores, and bringing samples back to the surface. This sampling process gives some isolated data points on huge expanses of rock, and we have to interpolate or guess as to what lies between those ‘good’ data points by interpreting seismic data.

Detailed models are built with great care to honor the data we do have, and they quickly generate large numerical workloads that really test solvers. For mostly historical reasons the models tend to be roughly rectangular in shape, with curved boundaries and highly variable properties, which is rich ground for visualization. For years NVIDIA has been involved in producing great images of reservoirs. Now we can be involved in solving these numerical models as well. That makes me happy.
SPE10 Benchmark

As in other fields, there is a need for standard benchmarks for reservoir simulations, and the one that has stood out over the years is the Society of Petroleum Engineers 10th comparative simulation model (SPE10 for short). Until recently, AmgX was stumped by SPE10. The aggregation AMG approach just was not strong enough to produce good answers in a reasonable amount of time. All that has changed with our classical AMG efforts. Now we can show some great performance on this challenging benchmark, and start to engage with the reservoir simulation community, hydrology and water resources, and anyone interested in high fidelity geological models and flow through reservoirs.
The existing gold standard for classical AMG on multi-core CPUs and clusters is the open-source package HYPRE. The BoomerAMG implementation of classical AMG it contains is the first package everyone wants to compare against. We are no different, so here are some speedup charts:
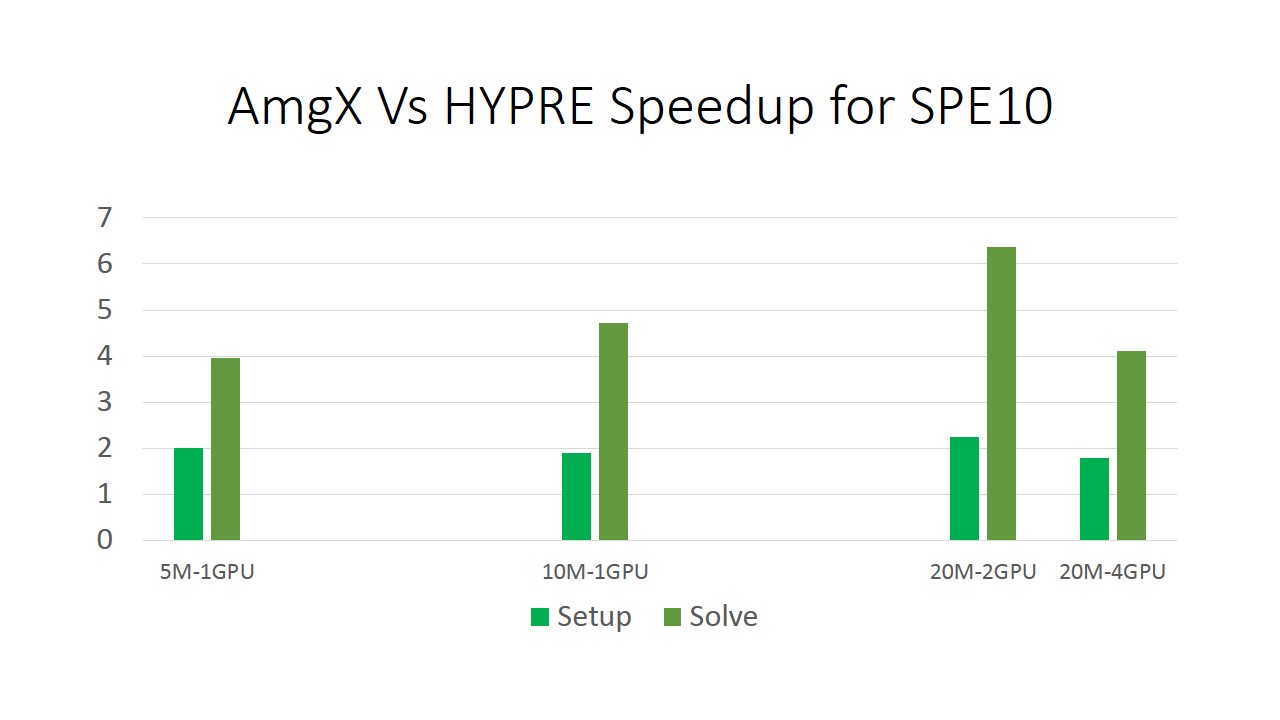 We are comparing a 5 million cell version of SPE10 on a single K40 GPU versus 2×10 core Intel Ivy Bridge CPUs (E5-2690 CPUs to be precise). Then we tried 10 million cells on a single GPU, and moved to multi-GPU tests by keeping the number of cells per GPU at least 5 Million. The results show a consistent 2x speedup on the expensive classical AMG setup phase, and an even better 4x to 6x speedup on the solve phase, where classical AMG really shines. The reason we want to keep the GPUs full is due to a unique feature of GPUs: as you make the problem larger, they can chew through the problem more efficiently, until you ‘fill up’ the GPU at which point efficiency hits a plateau. Starting with the top layer of the SPE10 dataset, we created a family of problems by adding layers to increase the problem size. Between 1 and 5 layers, ie 1 Million and 5 Million cells to solve, the throughput of AmgX more than doubles. This chart is a comparison of a single E5-2690 CPU socket to socket vs a K40 GPU, showing the ‘we get relatively faster as the problem gets larger’ effect.
We are comparing a 5 million cell version of SPE10 on a single K40 GPU versus 2×10 core Intel Ivy Bridge CPUs (E5-2690 CPUs to be precise). Then we tried 10 million cells on a single GPU, and moved to multi-GPU tests by keeping the number of cells per GPU at least 5 Million. The results show a consistent 2x speedup on the expensive classical AMG setup phase, and an even better 4x to 6x speedup on the solve phase, where classical AMG really shines. The reason we want to keep the GPUs full is due to a unique feature of GPUs: as you make the problem larger, they can chew through the problem more efficiently, until you ‘fill up’ the GPU at which point efficiency hits a plateau. Starting with the top layer of the SPE10 dataset, we created a family of problems by adding layers to increase the problem size. Between 1 and 5 layers, ie 1 Million and 5 Million cells to solve, the throughput of AmgX more than doubles. This chart is a comparison of a single E5-2690 CPU socket to socket vs a K40 GPU, showing the ‘we get relatively faster as the problem gets larger’ effect.

Better than ever
But we have more to offer for our existing users as well:
- we have added a JSON configuration option, so understanding complex configurations is easier,
- we have fixed some bugs (of course) and dramatically improved our parallel efficiency,
- we can reuse most of the setup phase when we solve a sequence of related matrices, and this speeds up simulations by avoiding wasted effort.
Our performance has improved across the whole Florida matrix collection even on a single GPU.

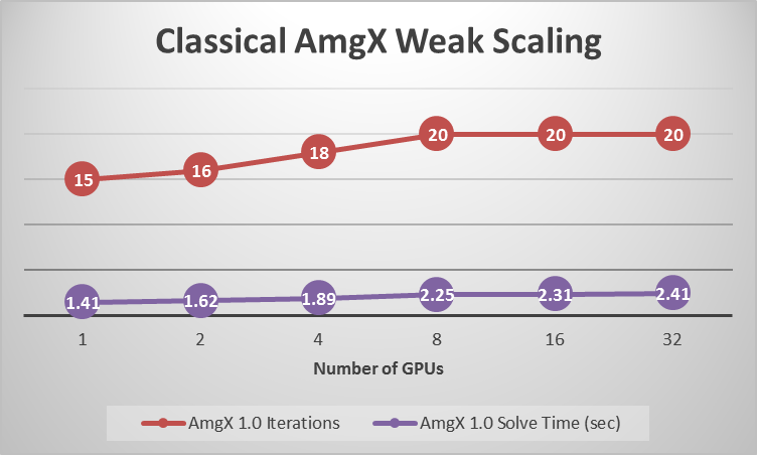
For large clusters, we can show weak scaling (keeping each GPU ‘full’) out to 32 GPUs for a benchmark Poisson problem.
Try us out
If you are solving large matrices coming from implicit PDE time stepping, with finite volume or unstructured finite element models, there is a good chance AmgX can accelerate your solution. We will be offering AmgX as a commercial library, with support for Linux, Windows 7 and all GPUs architectures Fermi and newer starting this month. Licensing is done via a FlexNet floating or node-locked license, and we will create a 15-day trial license so you can evaluate AmgX yourself. To get started, read our page on the CUDA developer site, become a CUDA registered developer and download the binaries. If you think AmgX is a good fit for your project, contact us directly and we will create a license for you to get started on your 15-day evaluation.