Posts by Justin Luitjens
Simulation / Modeling / Design
Feb 24, 2022
Speeding up Numerical Computing in C++ with a Python-like Syntax in NVIDIA MatX
Rob Smallshire once said, "You can write faster code in C++, but write code faster in Python." Since its release more than a decade ago, CUDA has given C and...
6 MIN READ

Simulation / Modeling / Design
Aug 20, 2020
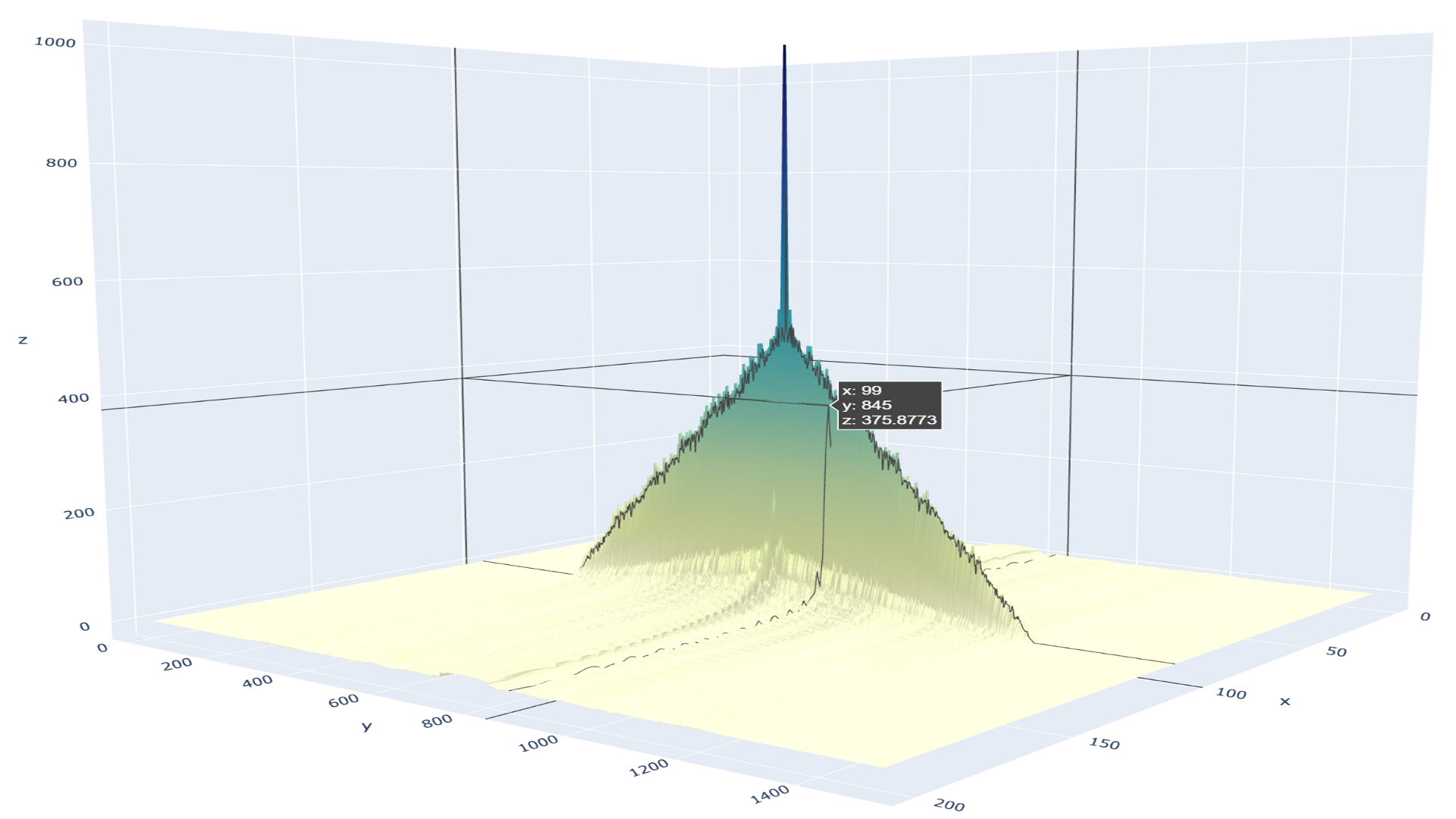
Extracting Features from Multiple Audio Channels with Kaldi
In automatic speech recognition (ASR), one widely used method combines traditional machine learning with deep learning. In ASR flows of this type, audio...
13 MIN READ
Simulation / Modeling / Design
Oct 17, 2019
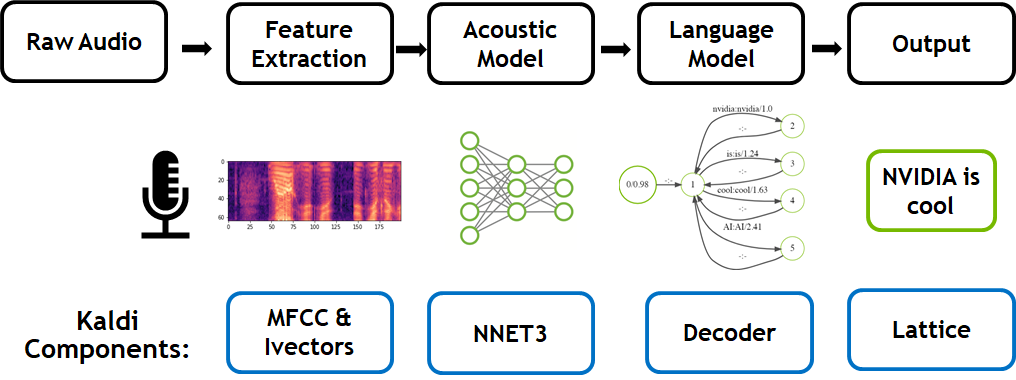
GPU-Accelerated Speech to Text with Kaldi: A Tutorial on Getting Started
Sign up for the latest Speech AI news from NVIDIA. Recently, NVIDIA achieved GPU-accelerated speech-to-text inference with exciting performance results. That...
12 MIN READ
Data Science
Mar 18, 2019
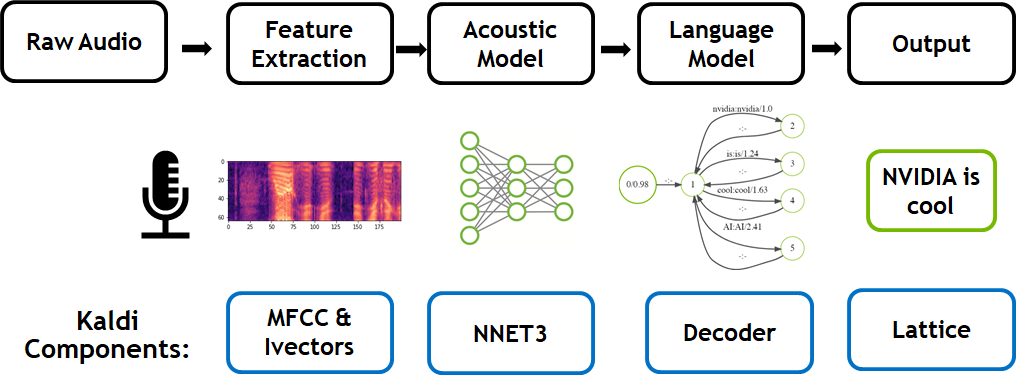
NVIDIA Accelerates Real Time Speech to Text Transcription 3500x with Kaldi
Think of a sentence and repeat it aloud three times. If someone recorded this speech and performed a point-by-point comparison, they would find that no single...
8 MIN READ

Simulation / Modeling / Design
Sep 04, 2014
CUDA Pro Tip: Always Set the Current Device to Avoid Multithreading Bugs
We often say that to reach high performance on GPUs you should expose as much parallelism in your code as possible, and we don't mean just parallelism...
3 MIN READ
Simulation / Modeling / Design
Feb 13, 2014
Faster Parallel Reductions on Kepler
Parallel reduction is a common building block for many parallel algorithms. A presentation from 2007 by Mark Harris provided a detailed strategy for...
12 MIN READ