Posts by Mark Harris

Data Science
Feb 10, 2022
Implementing High-Precision Decimal Arithmetic with CUDA int128
“Truth is much too complicated to allow anything but approximations.” -- John von Neumann The history of computing has demonstrated that there is no limit...
19 MIN READ
Simulation / Modeling / Design
Dec 08, 2020
Fast, Flexible Allocation for NVIDIA CUDA with RAPIDS Memory Manager
When I joined the RAPIDS team in 2018, NVIDIA CUDA device memory allocation was a performance problem. RAPIDS cuDF allocates and deallocates memory at high...
24 MIN READ

Data Science
Aug 20, 2019
CUDA Pro Tip: The Fast Way to Query Device Properties
CUDA applications often need to know the maximum available shared memory per block or to query the number of multiprocessors in the active GPU. One way to do...
3 MIN READ
Simulation / Modeling / Design
Oct 15, 2018
RAPIDS Accelerates Data Science End-to-End
Today's data science problems demand a dramatic increase in the scale of data as well as the computational power required to process it. Unfortunately, the...
10 MIN READ
Simulation / Modeling / Design
Oct 04, 2017
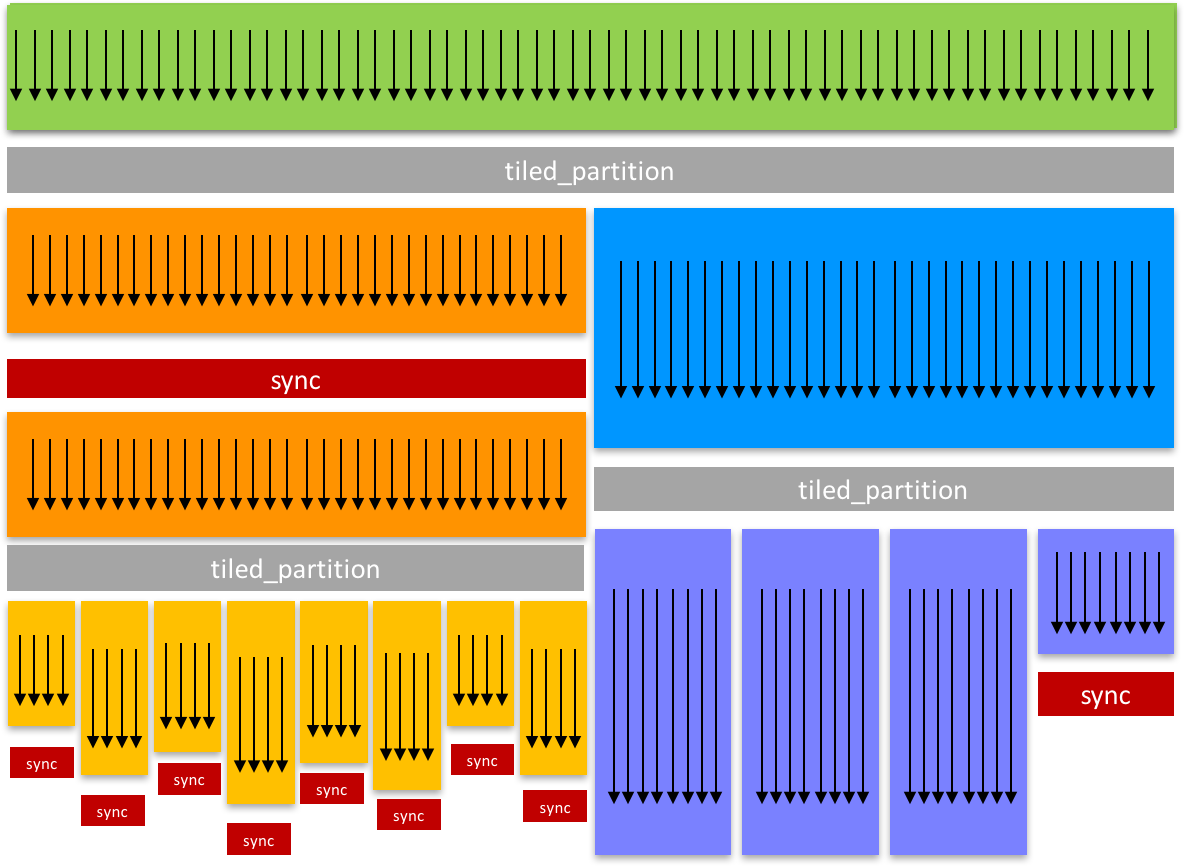
Cooperative Groups: Flexible CUDA Thread Programming
In efficient parallel algorithms, threads cooperate and share data to perform collective computations. To share data, the threads must synchronize. The...
16 MIN READ

Simulation / Modeling / Design
Jun 19, 2017
Unified Memory for CUDA Beginners
My previous introductory post, "An Even Easier Introduction to CUDA C++", introduced the basics of CUDA programming by showing how to write a simple program...
16 MIN READ