As a CUDA developer, you will often need to control which devices your application uses. In a short-but-sweet post on the Acceleware blog, Chris Mason writes:
Does your CUDA application need to target a specific GPU? If you are writing GPU enabled code, you would typically use a device query to select the desired GPUs. However, a quick and easy solution for testing is to use the environment variable
CUDA_VISIBLE_DEVICESto restrict the devices that your CUDA application sees. This can be useful if you are attempting to share resources on a node or you want your GPU enabled executable to target a specific GPU
As Chris points out, robust applications should use the CUDA API to enumerate and select devices with appropriate capabilities at run time. To learn how, read the section on Device Enumeration in the CUDA Programming Guide. But the CUDA_VISIBLE_DEVICES environment variable is handy for restricting execution to a specific device or set of devices for debugging and testing. You can also use it to control execution of applications for which you don’t have source code, or to launch multiple instances of a program on a single machine, each with its own environment and set of visible devices.
To use it, set CUDA_VISIBLE_DEVICES to a comma-separated list of device IDs to make only those devices visible to the application. Note that you can use this technique both to mask out devices or to change the visibility order of devices so that the CUDA runtime enumerates them in a specific order.
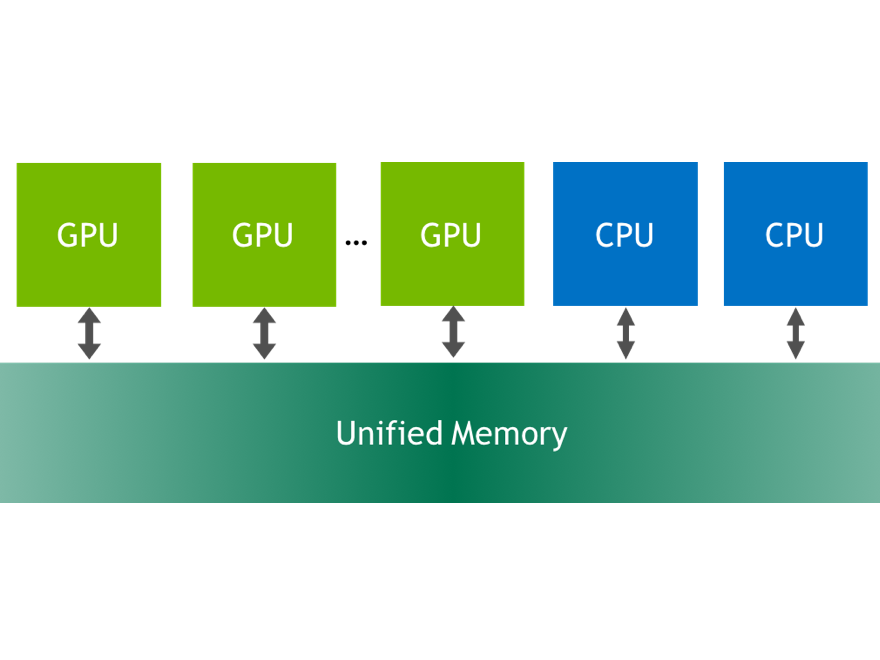
There is a specific case where CUDA_VISIBLE_DEVICES is useful in our upcoming CUDA 6 release with Unified Memory (see my post on Unified Memory). Unified Memory enables multiple GPUs and CPUs to share a single, managed memory space. Unified Memory between GPUs requires that the GPUs all support peer-to-peer memory access, but this is not the case in some systems where the GPUs are different models, or they connect to different I/O controller hubs on the PCI-express bus. If the GPUs are not all P2P compatible, then allocations with cudaMallocManaged() fall back to device-mapped host memory (also known as “zero copy” memory). Access to this memory is via PCI-express and has much lower bandwidth and higher latency. To avoid this fallback, you can use CUDA_VISIBLE_DEVICES to limit your application to run on a single device or on a set of devices that are P2P compatible.