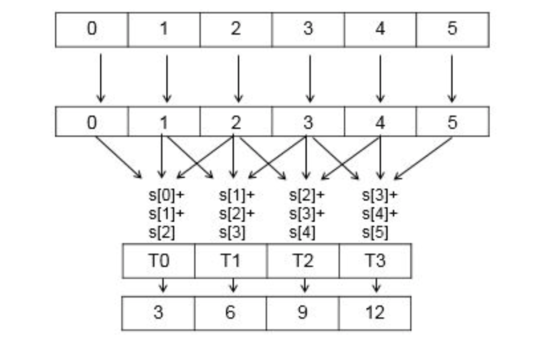
When writing parallel programs, you will often need to communicate values between parallel threads. The typical way to do this in CUDA programming is to use shared memory. But the NVIDIA Kepler GPU architecture introduced a way to directly share data between threads that are part of the same warp. On Kepler, threads of a warp can read each others’ registers by using a new instruction called SHFL, or “shuffle”.
In upcoming posts here on Parallel Forall we will demonstrate uses of shuffle. To prepare, I highly recommend watching the following recording of a GTC 2013 talk by Julien Demouth entitled “Kepler’s SHUFFLE (SHFL): Tips and Tricks”. In the talk, Julien covers many uses for shuffle, including reductions, scans, transpose, and sorting, demonstrating that shuffle is always faster than safe uses of shared memory, and never slower than unsafe uses of shared memory.
Earlier this year on the Acceleware blog, Kelly Goss wrote a detailed post about shuffle, including a detailed example. Like Julien, Kelly provided several reasons to use shuffle.
First, you can use the shuffle instruction to free up shared memory to be used for other data or to increase your occupancy. Secondly the shuffle instruction is faster than shared memory since it only requires one instruction versus three for shared memory (write, synchronize, read). Another potential performance advantage for shuffle is that relative to Fermi, shared memory bandwidth has doubled on Kepler devices but the number of compute cores has increased by 6x; therefore, the shuffle instruction provides another means to share data between threads and keep the CUDA cores busy with memory accesses that have low latency and high bandwidth. Finally, you might want to use the shuffle instruction instead of warp-synchronous optimizations (removing
__syncthreads()).
For more details on shuffle, check out the NVIDIA CUDA Programming Guide section on warp shuffle functions.