When I work on the optimization of CUDA kernels, I sometimes see a discrepancy between Achieved and Theoretical Occupancies. The Theoretical Occupancy is the ratio between the number of threads which may run on each multiprocessor (SM) and the maximum number of executable threads per SM (2048 on the Kepler architecture). This value is estimated from the size of the blocks and the amount of resources (registers and shared memory) used by those blocks for a particular GPU and is computed without running the kernel on the GPU. The Achieved Occupancy, on the other hand, is measured from the execution of the kernel (as the number of active warps divided by the number of active cycles compared to the maximum number of executable warps).
Recently, while working on a kernel for a finance benchmark, I could see an Achieved Occupancy of 41.52% whereas the Theoretical Occupancy was 50%. In NVIDIA Nsight Visual Studio Edition, the Instruction per Clock (IPC) showed a lot of load imbalance between the different SMs with respect to the number of executed instructions by the kernel (see the left graph in the figure below).
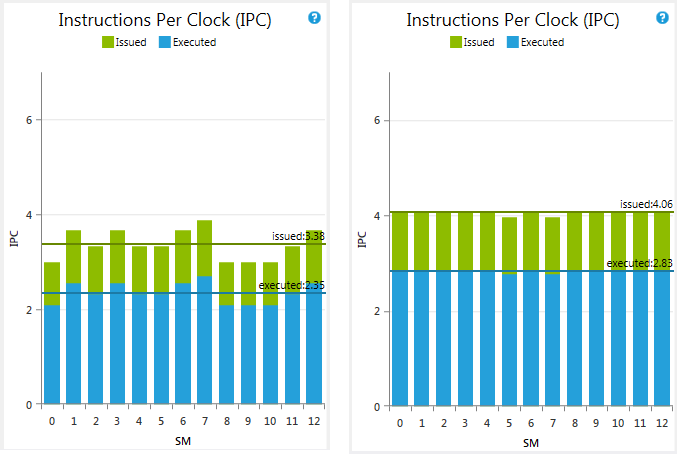
The reason for that imbalance is a Tail Effect. When the GPU launches a grid of threads for a kernel, that grid is divided into waves of thread blocks. The size of a wave depends on the number of SMs on the GPU and the Theoretical Occupancy of the kernel. On a NVIDIA Tesla K20 there are 13 SMs and the Theoretical Occupancy of my kernel was 4 blocks of 256 threads per SM (50%). Each full wave was composed by 13×4 = 52 blocks. Since the kernel was only launching a total of 128 blocks (a very low number), the code was executed in 2 full waves and a much smaller wave of 24 blocks. The last wave under-utilized the GPU but represented a significant fraction of the run time.
To improve the performance of the kernel, I used the __launch_bounds__ attribute to constrain the number of registers since it was the main occupancy limiter. As a result, the kernel is now able to run 5 blocks of 256 threads per SM instead of 4 blocks as before. The same computation is achieved in 1 full wave of 13×5 = 65 blocks and an almost-full wave of 63 blocks. The impact of the tail effect is much reduced (see the right graph in the figure above). The Theoretical and Achieved Occupancies have increased to 62.50% and 61.31%, respectively, and the performance has improved by 1.19x (from 4.535ms to 3.825ms).
Tail effect may play an important role when the number of blocks executed for a kernel is small. This is one of the reasons we recommend launching a large number of blocks per grid, when possible. With 100s or 1,000s of waves, the impact of a partial wave at the end is much reduced. When it is not possible to extract as much parallelism, keep the tail effect in mind. There are ways to work around it.