Often cited as the main reason that naïve C/C++ code cannot match FORTRAN performance, pointer aliasing is an important topic to understand when considering optimizations for your C/C++ code. In this tip I will describe what pointer aliasing is and a simple way to alter your code so that it does not harm your application performance.
What is pointer aliasing?
Two pointers alias if the memory to which they point overlaps. When a compiler can’t determine whether pointers alias, it has to assume that they do. The following simple function shows why this is potentially harmful to performance:
void example1(float *a, float *b, float *c, int i) {
a[i] = a[i] + c[i];
b[i] = b[i] + c[i];
}
At first glance it might seem that this function needs to perform three load operations from memory: one for a[i], one for b[i] and one for c[i]. This is incorrect because it assumes that c[i] can be reused once it is loaded. Consider the case where a and c point to the same address. In this case the first line modifies the value c[i] when writing to a[i]. Therefore the compiler must generate code to reload c[i] on the second line, in case it has been modified.
Because the compiler must conservatively assume the pointers alias, it will compile the above code inefficiently, even if the programmer knows that the pointers never alias.
What can I do about aliasing?
Fortunately almost all C/C++ compilers offer a way for the programmer to give the compiler information about pointer aliasing. The C99 standard includes the keyword restrict for use in C. In C++ there is no standard keyword, but most compilers allow the keywords __restrict__ or __restrict to be used for the same purpose as restrict in C.
By giving a pointer the restrict property, the programmer is promising the compiler that any data written to through that pointer is not read by any other pointer with the restrict property. In other words, the compiler doesn’t have to worry that a write to a restrict pointer will cause a value read from another restrict pointer to change. This greatly helps the compiler optimize code.
To show the performance benefits of restrict-decorated pointers, consider the following function:
void example2a(float *a, float *b, float *c) {
for (int i = 0; i < 1024; i++) {
a[i] = 0.0f;
b[i] = 0.0f;
for (int j = 0; j < 1024; j++) {
a[i] = a[i] + c[i*1024 + j];
b[i] = b[i] + c[i*1024 + j] * c[i*1024 + j];
}
}
}
This function is similar to our original example and, as before, the compiler generates sub-optimal code to ensure that it works with aliased pointers. Because the compiler must assume that a[i] and b[i] overlap, it must both read and write them every iteration of the inner loop.
If we know at compile time that our three pointers are not used to access overlapping regions, we can add __restrict__ to our pointers. Now the compiler knows that a[i] and b[i] cannot overlap, so it can optimize the inner loop by storing the running sum in a local variable and only writing it once at the end.
void example2b(float * __restrict__ a, float * __restrict__ b, float * __restrict__ c) {
for (int i = 0; i < 1024; i++) {
a[i] = 0.0f;
b[i] = 0.0f;
for (int j = 0; j < 1024; j++) {
a[i] = a[i] + c[i*1024 + j];
b[i] = b[i] + c[i*1024 + j] * c[i*1024 + j];
}
}
}
Timing these two functions:
Original (example2a): |
3.13ms |
Restrict (example2b): |
1.05ms |
Just adding __restrict__ in this case produces 3x faster code! I could have achieved the same result by introducing local summation variables myself, but in real-world situations allowing the compiler to do this optimization is often easier.
Wait, where’s the CUDA?
I haven’t talked about GPUs or CUDA at all so far. This is because pointer aliasing is something developers of high-performance code need to be aware of on both the GPU and the CPU and, as demonstrated above, proper use can significantly improve performance.
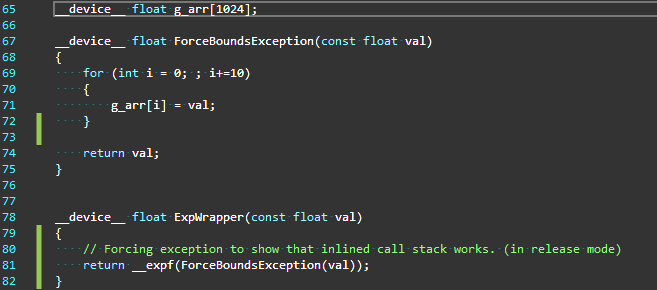
There is, however, one potential GPU-specific benefit to __restrict__. Compute Capability 3.5 NVIDIA GPUs (e.g. Kepler) have a cache designed for read-only data which can, for some codes, improve data access performance. This cache can only be used for data that is read-only for the lifetime of the kernel. To use the read-only data cache, the compiler must determine that data is never written. Due to potential aliasing, the compiler can’t be sure a pointer references read-only data unless the pointer is marked with both const and __restrict__. Also, as the Kepler Tuning Guide points out, “adding these qualifiers where applicable can improve code generation quality via other mechanisms on earlier GPUs as well.”
In the following code I copy elements of array a into array b. These elements are chosen by reading an index in array c, which is initialized with random integers between 0 and the array length.
__global__ void example3a(float* a, float* b, int* c) {
int index = blockIdx.x * blockDim.x + threadIdx.x;
b[index] = a[c[index]];
}
Note that in this case there are no redundant memory accesses due to potential pointer aliasing. Each thread reads one element of c and a and writes one element of b. However, because both a and c are read-only, and I know that the data does not overlap, I can add const and __restrict__ to the above code.
__global__ void example3b(const float* __restrict__ a, float* __restrict__ b, const int* __restrict__ c) {
int index = blockIdx.x * blockDim.x + threadIdx.x;
b[index] = a[c[index]];
}
This extra information allows the CUDA compiler to use the read-only data cache and improves performance by more than 2x.
Original (example3a): |
47.6μs |
Restrict (example3b): |
22.5μs |
Conclusion
It’s important to understand pointer aliasing when writing code where every clock cycle counts. While you can sometimes explicitly write around performance problems caused by potential aliasing, using the __restrict__ keyword allows the compiler to do much of the work for you. It also allows the use of the GPU read-only data cache, potentially accelerating data movement to your kernel.
As with most code-level optimizations, your mileage may vary. Always profile your code and try to determine the bottlenecks and how far it is from hardware performance limits before spending too much time trying to optimize.