
Digital signal processing (DSP) applications commonly transform input data before performing an FFT, or transform output data afterwards. For example, if the input data is supplied as low-resolution samples from an 8-bit analog-to-digital (A/D) converter, the samples may first have to be expanded into 32-bit floating point numbers before the FFT and the rest of the processing pipeline can start.
The cuFFT library included with CUDA 6.5 introduces device callbacks to improve performance of this sort of transforms. Callback routines are user-supplied device functions that cuFFT calls when loading or storing data. You can use callbacks to implement many pre- or post-processing operations that required launching separate CUDA kernels before CUDA 6.5.
Example DSP Pipeline
In this blog post we will implement the first stages of a typical DSP pipeline as depicted in Figure 1. We will first discuss a solution without callbacks using multiple custom kernels which we then use as a stepping stone towards a solution based on cuFFT device callbacks. The source code for both versions is available on github.
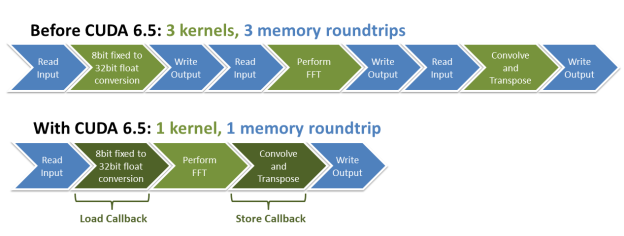
Batches of 8-bit fixed-point samples are input to the DSP pipline from an A/D converter. Each sample consists of 1024 data points. For more efficient processing, we group samples into batches of 1000 samples each. Therefore, you can think of this input as a 1000×1024 matrix of 8-bit fixed-point values.
After converting the 8-bit fixed-point elements to 32-bit floating point the application performs row-wise one-dimensional real-to-complex (R2C) FFTs on the input. The output of an 

For the code examples, we define the following constants.
#define INPUT_SIGNAL_SIZE 1024 #define BATCH_SIZE 1000 #define COMPLEX_SIGNAL_SIZE (INPUT_SIGNAL_SIZE/2 + 1)
The DSP pipeline without cuFFT Callbacks
In this section we describe a solution requiring two custom kernels in addition to the batched R2C FFT provided by cuCFFT. The first kernel ConvertInputR performs the data conversion from 8-bit fixed-point to 32-bit floating point numbers, as shown in the following code.
__global__ void ConvertInputR(
const char * __restrict__ dataIn,
cufftReal * __restrict__ dataOut)
{
const int numThreads = blockDim.x * gridDim.x;
const int threadId = blockIdx.x * blockDim.x + threadIdx.x;
for(size_t offset = threadId;
offset < INPUT_SIGNAL_SIZE * BATCH_SIZE;
offset += numThreads)
{
char element = dataIn[offset];
dataOut[offset] = (cufftReal)((float)element/127.0f);
}
}
ConvertInputR takes as input a pointer to an 8-bit char buffer for the input data and a pointer to a 32-bit output buffer of type cufftReal to store the expanded elements. The 8-bit input is stored as Q0.7 fixed-point values (1 sign bit, 0 integer bits, 7 fractional bits), which we convert to floating point by dividing the integer value by 127.0f. (Note that we use a grid-stride loop in this kernel.)
The second custom kernel ConvolveAndStoreTransposedC_Basic runs after the FFT. It performs the convolution, an element-wise complex multiplication between each element and the corresponding filter element, and—at the same time—transposes the 1000×513 matrix into a 513×1000 matrix.
__device__ __host__ inline
cufftComplex ComplexMul(cufftComplex a, cufftComplex b)
{
cufftComplex c;
c.x = a.x * b.x - a.y * b.y;
c.y = a.x * b.y + a.y * b.x;
return c;
}
__global__
void ConvolveAndStoreTransposedC_Basic(
const cufftComplex * __restrict__ dataIn,
cufftComplex * __restrict__ dataOut,
const cufftComplex * __restrict__ filter)
{
int x = blockIdx.x * TILE_DIM + threadIdx.x;
int yBase = blockIdx.y * TILE_DIM + threadIdx.y;
if(x < COMPLEX_SIGNAL_SIZE) {
for(int j = 0; j < TILE_DIM; j+= BLOCK_ROWS) {
int y = yBase + j;
if(y >= BATCH_SIZE) break;
cufftComplex element = dataIn[y * COMPLEX_SIGNAL_SIZE + x];
cufftComplex value = ComplexMul(element, filter[x]);
dataOut[x*BATCH_SIZE + y] = value;
}
}
}
ConvolveAndStoreTransposedC_Basic takes pointers to the complex input and output matrices as well as the filter of length COMPLEX_SIGNAL_SIZE. It implements a straightforward transpose with coalesced reads of dataIn but non-coalesced writes to dataOut. We launch this kernel with a grid of blocks of size TILE_DIMxTILE_DIM on the row-major sample matrix. An earlier blog post discussed optimized matrix transpose and we implement it in the ConvolveAndStoreTransposedC_Optimized function in the sample code.
The main routine sets up the data buffers and the cuFFT-related data structures before implementing our DSP pipeline. In this example we are using Unified Memory to simplify memory management and reduce the code size.
char *_8bit_signal;
cufftReal *tmp_result1;
cufftComplex *tmp_result2, *result, *filter;
checkCudaErrors(cudaMallocManaged(
&_8bit_signal,
sizeof(char) * INPUT_SIGNAL_SIZE * BATCH_SIZE,
cudaMemAttachGlobal));
checkCudaErrors(cudaMallocManaged(
&tmp_result1,
sizeof(cufftReal) * INPUT_SIGNAL_SIZE * BATCH_SIZE,
cudaMemAttachGlobal));
checkCudaErrors(cudaMallocManaged(
&tmp_result2,
sizeof(cufftComplex) * COMPLEX_SIGNAL_SIZE * BATCH_SIZE,
cudaMemAttachGlobal));
checkCudaErrors(cudaMallocManaged(
&result,
sizeof(cufftComplex) * COMPLEX_SIGNAL_SIZE * BATCH_SIZE,
cudaMemAttachGlobal));
checkCudaErrors(cudaMallocManaged(
&filter,
sizeof(cufftComplex) * COMPLEX_SIGNAL_SIZE,
cudaMemAttachGlobal));
loadInputData(_8bit_signal, filter);
Unified memory allows us to pass the _8bit_signal and the filter buffers to a standard C routine to load the data, without the need of manually managing explicit memory transfers between dedicated host and device buffers. Having created the buffers we continue with setting up a cuFFT plan object for a one-dimensional INPUT_SIGNAL_SIZE x BATCH_SIZE batched real-to-complex FFT.
cufftHandle fftPlan;
size_t workSize;
checkCudaErrors(cufftCreate(&fftPlan));
int signalSize = INPUT_SIGNAL_SIZE;
checkCudaErrors(cufftMakePlanMany(
fftPlan,
1, &signalSize, //1-D INPUT_SIGNAL_SIZE samples
0,0,0,0,0,0,
CUFFT_R2C,
BATCH_SIZE,
&workSize));
Finally, we can implement our DSP pipeline in a relatively straight-forward fashion (along with some timing code).
cudaEvent_t start, end;
cudaEventCreate(&start);
cudaEventCreate(&end);
float elapsedTime;
checkCudaErrors(cudaEventRecord(start, 0));
//Step 1
ConvertInputR<<<32,128>>>(_8bit_signal, tmp_result1);
checkCudaErrors(cudaGetLastError());
//Step 2
checkCudaErrors(cufftExecR2C(fftPlan, tmp_result1, tmp_result2));
//Step 3
dim3 block(TILE_DIM, BLOCK_ROWS);
dim3 grid((COMPLEX_SIGNAL_SIZE + block.x-1)/block.x,
(BATCH_SIZE + block.y-1)/block.y);
ConvolveAndStoreTransposedC_Basic<<<grid,block>>>(
tmp_result2,
result,
filter);
checkCudaErrors(cudaGetLastError());
checkCudaErrors(cudaEventRecord(end, 0));
checkCudaErrors(cudaDeviceSynchronize());
checkCudaErrors(cudaEventSynchronize(end));
checkCudaErrors(cudaEventElapsedTime(&elapsedTime, start, end));
printf("Time for the FFT: %fms\n", elapsedTime);
...
Time for the FFT: 4.199070ms
CUDA 6.5: Introducing Callbacks
The cuFFT callback feature is a set of APIs that allow the user to provide device functions to redirect or manipulate data as it is loaded before processing the FFT, or as it is stored after the FFT. The signatures of the callback routines are distinguished by the data type of the transform (single real, double real, single complex, double complex) and their direction (load, store). For the load callback, cuFFT passes the callback routine the address of the input data and the offset to the value to be loaded from device memory, and the callback routine returns the value it wishes cuFFT to use instead. For the store callback, cuFFT passes the callback routine the value it has computed, along with the address of the output data and the offset to the value to be written to device memory, and the callback routine modifies the value and stores the modified result.
For the real-to-complex FFT in our example we define a cufftReal load callback and a cufftComplex store callback. Note how the load and store callbacks resemble the core of the custom kernels developed in the previous section.
__device__ cufftReal CB_ConvertInputR(
void *dataIn,
size_t offset,
void *callerInfo,
void *sharedPtr)
{
char element = ((char*)dataIn)[offset];
return (cufftReal)((float)element/127.0f);
}
__device__ void CB_ConvolveAndStoreTransposedC(
void *dataOut,
size_t offset,
cufftComplex element,
void *callerInfo,
void *sharedPtr)
{
cufftComplex *filter = (cufftComplex*)callerInfo;
size_t row = offset / COMPLEX_SIGNAL_SIZE;
size_t col = offset % COMPLEX_SIGNAL_SIZE;
cufftComplex value = ComplexMul(element, filter[col]);
((cufftComplex*)dataOut)[col * BATCH_SIZE + row] = value;
}
Callbacks are called on a per-element basis. The dataIn pointer (respectively dataOut pointer) is set to the input (respectively output) buffer passed to the corresponding cuFFT exec call. The element offset is the index of the element for which the callback has been called. The callerInfo object can be used to pass additional parameters to the callback. In our example, we only need to pass the filter for the convolution. However, for more complex callback functions you may want to define a dedicated struct for passing multiple parameters to the callback. If the callback requires shared memory, you can call cufftXtSetCallbackSharedSize with the amount of shared memory and cuFFT will pass a pointer to the shared memory through the sharedPtr parameter.
To register the callbacks with the cuFFT plan, the first step is to get the device function pointers from the device onto the host. We do this by defining device variables that point to the callback functions:
__device__ cufftCallbackLoadR d_loadCallbackPtr = CB_ConvertInputR; __device__ cufftCallbackStoreC d_storeCallbackPtr = CB_ConvolveAndStoreTransposedC;
To get the two function pointers from the device onto the host, we use the cudaMemcpyFromSymbol function from the CUDA libary.
cufftCallbackLoadR h_loadCallbackPtr;
checkCudaErrors(cudaMemcpyFromSymbol(
&h_loadCallbackPtr,
d_loadCallbackPtr,
sizeof(h_loadCallbackPtr)));
cufftCallbackStoreC h_storeCallbackPtr;
checkCudaErrors(cudaMemcpyFromSymbol(
&h_storeCallbackPtr,
d_storeCallbackPtr,
sizeof(h_storeCallbackPtr)));
Note that if you have a device with compute capability of 3.0 or higher, you could simply declare the device pointers as __managed__ and let unified memory take care of copying the pointers to the host. In this case, cudaMemcpyFromSymbol is not needed.
Having successfully copied the function pointers from the device to the host we can finally add the callbacks to the cuFFT plan. Creating and setting up the plan is done exactly as in the previous section using cufftCreate and cufftMakePlanMany. But the initialized plan allows us to call cufftXtSetCallback for each callback we want to register, passing the function pointers and a flag describing the type (signature) of the callback. For the store callback, we also pass the device pointer to the custom caller info object, in our case the filter buffer:
checkCuFFTErrors(cufftXtSetCallback(fftPlan,
(void **)&h_loadCallbackPtr,
CUFFT_CB_LD_REAL,
0));
checkCuFFTErrors(cufftXtSetCallback(fftPlan,
(void **)&h_storeCallbackPtr,
CUFFT_CB_ST_COMPLEX,
(void **)&filter));
Once the setup is finished, our FFT is ready to perform the complex processing pipeline from Figure 1 in a single call (again adding timing code):
cudaEvent_t start, end;
cudaEventCreate(&start);
cudaEventCreate(&end);
float elapsedTime;
checkCudaErrors(cudaEventRecord(start, 0));
checkCudaErrors(cufftExecR2C(
fftPlan,
(cufftReal*)_8bit_signal,
tmp_result2));
checkCudaErrors(cudaEventRecord(end, 0));
checkCudaErrors(cudaEventSynchronize(end));
checkCudaErrors(cudaEventElapsedTime(&elapsedTime, start, end));
printf("Time for the FFT: %fms\n", elapsedTime);
...
Time for the FFT: 3.480549ms
Compiling and Running cuFFT Callbacks
The cuFFT callback feature is available in the statically linked cuFFT library only, currently only on 64-bit Linux operating systems. Callbacks therefore require us to compile the code as relocatable device code using the --device-c (or short -dc) compile flag and to link it against the static cuFFT library with -lcufft_static. Important: If you forget to compile as relocatable device code your application may quietly ignore callbacks and produce wrong results!
nvcc -ccbin g++ -dc -m64 -o cufft_callbacks.o -c cufft_callbacks.cu nvcc -ccbin g++ -m64 -o cufft_callbacks cufft_callbacks.o -lcufft_static -lculibos
Performance
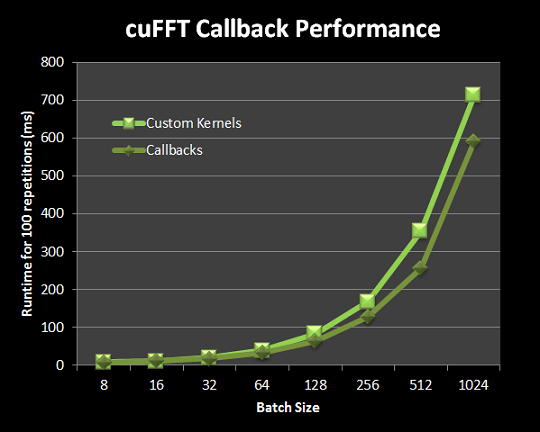
Figure 2 plots the runtime of 100 repetitions of the custom kernels version and the callback-based version across different batch sizes. The batch sizes grow exponentially, which explains the exponential increase in runtime. From Figure 2 we can see that for samples of size 1024 and batch sizes of around 128 elements and above the callback-based version is roughly 20% faster than the version using custom kernels.
Conclusion
cuFFT 6.5 callback functions redirect or manipulate data as it is loaded before processing an FFT, and/or before it is stored after the FFT. This means cuFFT can transform input and output data without extra bandwidth usage above what the FFT itself uses. For our example, callbacks provide a significant performance benefit of 20% over the version with the custom conversion and basic transpose kernels.
Download the CUDA Toolkit version 6.5 today!





