This week’s Spotlight is on Dr. Ian Lane of Carnegie Mellon University. Ian is an Assistant Research Professor and leads a speech and language processing research group based in Silicon Valley. He co-directs the CUDA Center of Excellence at CMU with Dr. Kayvon Fatahalian.
This week’s Spotlight is on Dr. Ian Lane of Carnegie Mellon University. Ian is an Assistant Research Professor and leads a speech and language processing research group based in Silicon Valley. He co-directs the CUDA Center of Excellence at CMU with Dr. Kayvon Fatahalian.
NVIDIA: Ian, what is Speech Recognition?
Ian: Speech Recognition refers to the technology that converts an audio signal into the sequence of words that the user spoke. By analyzing the frequencies within a snippet of audio, we can determine what sounds within spoken language a snippet most closely matches, and by observing sequences of these snippets we can determine what words or phrases the user most likely uttered.
Speech Recognition spans many research fields, including signal processing, computational linguistics, machine learning and core problems in computer science, such as efficient algorithms for large-scale graph traversal. Speech Recognition also is one of the core technologies required to realize natural Human Computer Interaction (HCI). It is becoming a prevalent technology in interactive systems being developed today.
NVIDIA: What are examples of real-world applications?
Ian: In recent years, speech-based interfaces have become much more prevalent, including applications such as virtual personal assistants, which include systems such as Siri from Apple or Google Voice Search, as well as speech interfaces for smart TVs and in-vehicle systems. Speech Recognition technologies are also applied to many other tasks including speech transcription for document generation, call center analytics and multi-media archive search.
NVIDIA: Why accelerate Speech Recognition? What kinds of new applications could be enabled?
Ian: To obtain accurate Speech Recognition we need to use large models that cover many different acoustic environments, as well as very broad vocabularies to cover, hopefully, any possible word that a user may speak.
In the past, we would often build one system optimized for accuracy (that could be up to 10x slower than real-time), and a separate system optimized for real-time Speech Recognition. The real-time Speech Recognition would generally have lower accuracy in order to perform recognition at a faster speed. With recent GPU technologies, however, we have demonstrated that this tradeoff no longer has to be made.
By leveraging both the CPU and GPU processors during the Speech Recognition process, we can perform recognition using large, and in some cases multiple models, obtaining high accuracy even on embedded and mobile systems.
Additionally, pre-recorded speech or multimedia content can be transcribed much more quickly. Compared to a single-thread CPU implementation, which is the standard architecture used in Speech Recognition today, we are able to perform recognition up to 33x faster. For some content this allows us to transcribe 30 minutes of audio in less than one minute. It is very exciting to see how GPUs are opening up new possibilities because of the speed they enable.
NVIDIA: Tell us about the HYDRA project.
Ian: HYDRA is an ongoing research project at Carnegie Mellon University in which we are exploring new highly-parallel compute platforms for the Speech Recognition task. Over the past two years we have specifically been focusing on heterogeneous CPU-GPU platforms.
With colleagues Dr. Jike Chong and Jungsuk Kim, we developed a new architecture for Speech Recognition specifically optimized for CUDA-enabled GPUs. Our proposed architecture efficiently leverages both GPU and CPUs to achieve very large vocabulary Speech Recognition (over one million words) at up to 30x faster than CPU-only approaches.
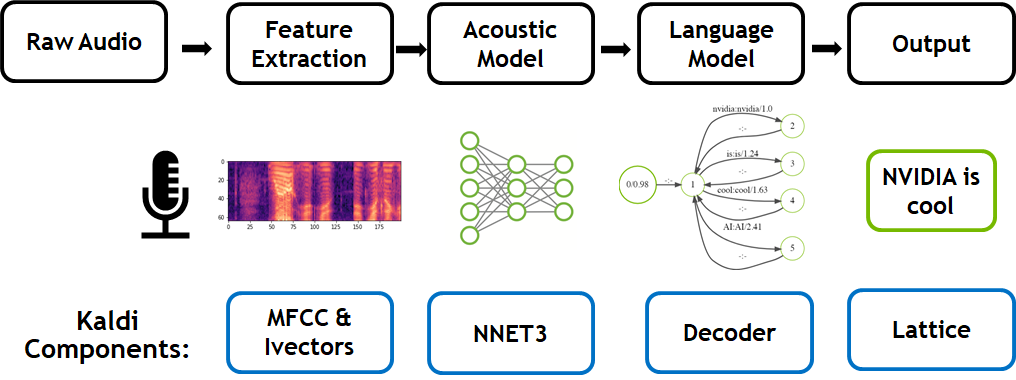
The HYDRA project involves exposing the fine-grained concurrency across all components of Speech Recognition and efficiently mapping them onto the parallelism available on the latest multi-code CPU and GPU architectures. Each sub-component of the process, which includes feature extraction, acoustic model computation, language model lookup and graph search, was mapped to the appropriate compute architecture to allow for efficient execution.
One of the breakthroughs in this project was the execution of the core Speech Recognition search and language model lookup steps in parallel on the GPU and CPU cores respectively. This allowed us to perform Speech Recognition with extremely large language models (over one billion parameters), with little degradation to the speed in which Speech Recognition was performed on the GPU. An overview of this architecture is shown below.

NVIDIA: How does HYDRA leverage GPU computing?
Ian: Speech Recognition involves two main computations: acoustic model computation, which estimates how well the acoustic signal matches to specific phonetic units, and graph-search, which matches sequences of phonetic states against word sequences producing the most likely recognition hypothesis for a series of acoustic observations.
The acoustic model computation can be performed with a deep neural network, which computes the likelihood of phonetic units based on an acoustic observation. This computation involves performing multiple large matrix-multiply operations. The GPU performs extremely well for this task due to its high level of parallelism and fast block memory access.
The second computation involves performing a time-synchronous Viterbi search over a weighted-Finite-State-Transducer (wFST). In Speech Recognition, this wFST network combines models for both word pronunciations and word sequences into a single search graph. The search process generates the most likely word sequence for the acoustic observations up until this point. The graphs used in Speech Recognition often contain tens of millions of states and hundreds of millions of arcs.
Compared to the acoustic model computation, the time-synchronous Viterbi search is very communication-intensive. At any point during the search, hundreds of thousands of competing arcs are evaluated, requiring extremely diverse memory access.
NVIDIA: What challenges did you face in parallelizing the algorithms?
Ian: The most important parallelization challenge was implementation of a parallel version of n-best Viterbi search specifically optimized for many-core GPU architectures. During Viterbi search there can be hundreds of arcs, each with n-best lists consisting of tens of entries.
On re-convergent paths, multiple lists are must be merged into a single list of the most likely hypothesis candidates. This list must be sorted to retain the top n-best candidates to pass forward during search.
Performing a list merge followed by sort as blocking functions is very inefficient on the GPU, especially as this process is performed tens of thousands of times per second. To overcome this challenge we developed a novel method based on an “Atomic Merge-and-Sort” operation, which enabled n-best lists to be merged atomically on GPU platforms. Our method heavily uses the 64-bit atomic Compare-And-Swap (atomicCAS) operation, which is implemented in hardware on modern CUDA-enabled GPUs. An overview of our proposed algorithm for “Atomic Merge-and-Sort” is shown below:

NVIDIA: Which CUDA features and GPU libraries do you use?
Ian: For the acoustic model computation stage we heavily leveraged the cuBLAS libraries from NVIDIA. For the graph search step we found the 64-bit atomic operations to be highly effective. During Speech Recognition, millions of fine-grained synchronizations are performed every second so efficient synchronization via atomic operations is critical for the performance of the application.
NVIDIA: What other applications are you using GPUs for in your research?
Ian: Apart from the Speech Recognition task itself we heavily leverage GPUs for model training. We leverage deep neural network models for many tasks in multimodal interaction, including acoustic and language models in Speech Recognition, parsing models for natural language understanding and audio-visual models for multimodal understanding.
We are able to train these models much more efficiently using a handful of GPUs rather than our traditional CPU clusters. For example, an acoustic model that would typically take more than 1000 CPU-hours to train on a CPU cluster can be trained in under ten hours on a single GPU.
NVIDIA: What are you most excited about, in terms of near-term advancements?
Ian: In order to perform Speech Recognition accurately in very noisy conditions, such as in a vehicle moving at a speed, a single microphone input is often insufficient. By leveraging multiple microphones and additional sensors such as cameras, Speech Recognition performance can be improved dramatically. However, it is not practical to transmit all this data over a network for server-based Speech Recognition so better embedded solutions will be required.
While these solutions are not possible today, GPU performance on mobile and embedded platforms is improving dramatically. In a few years the compute power on these platforms will match what we have on desktop PCs today. This will allow us to do much more processing on a local, embedded platform and enable us to explore new methods for robust Speech Recognition.
______________________________________________________________________________
[Editor’s Note: Learn more about GPU-accelerated speech recognition at the GPU Technology Conference. Carnegie Mellon Ph.D. candidate Wonkyum Lee will speak on GPU Accelerated Model Combination for Robust Speech Recognition and Keyword Search, on Wed., March 26.]
______________________________________________________________________________
Read more GPU Computing Spotlights.