So far in the CUDA Python mini-series on CUDACasts, I introduced you to using the @vectorize decorator and CUDA libraries, two different methods for accelerating code using NVIDIA GPUs. In today’s CUDACast, I’ll be demonstrating how to use the NumbaPro compiler from Continuum Analytics to write CUDA Python code which runs on the GPU.
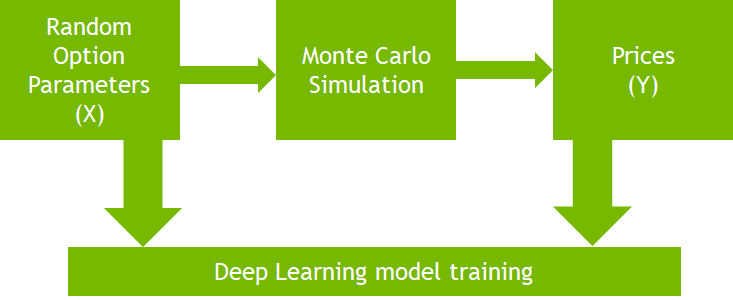
In CUDACast #12, we’ll continue using the Monte Carlo options pricing example, and I’ll show how to write the step function in CUDA Python rather than using the @vectorize decorator. In addition, by using the nvprof command-line profiler, we’ll be able to see the speed-up we’re able to achieve by writing the code explicitly in CUDA.
To request a topic for a future episode of CUDACasts, or if you have any other feedback, please leave a comment to let us know.