The cuDNN library team is excited to announce the second version of cuDNN, NVIDIA’s library of GPU-accelerated primitives for deep neural networks (DNNs). We are proud that the cuDNN library has seen broad adoption by the deep learning research community and is now integrated into major deep learning toolkits such as CAFFE, Theano and Torch. While cuDNN was conceived with developers of deep learning toolkits and systems in mind, this release is all about features and performance for the deep learning practitioner. Before we get into those details though, let’s provide some context.
Deep Learning for Big Data
Data science and machine learning have been growing rapidly in importance in recent years, along with the volume of “big data”. Machine learning provides techniques for developing systems that can automatically recognize, categorize, locate or filter the torrent of big data that flows endlessly into corporate servers (and our email inboxes). Deep neural networks (DNNs) have become an especially successful and popular technique, because DNNs are relatively straightforward to implement and scale well—the more data you throw at them the better they perform. Most importantly, DNNs are now established as the most accurate technique across a range of problems, including image classification, object detection, and text and speech recognition. In fact, research teams from Microsoft, Google and Baidu have recently shown DNNs that perform better on an image recognition task than a trained human observer!
Deep learning and machine learning have been popular topics on Parallel Forall recently, so here are some pointers to excellent recent posts for more information. The original cuDNN announcement post provides an introduction to machine learning, deep learning and cuDNN. There are excellent posts on using cuDNN with Caffe for computer vision, with Torch for natural language understanding, on how Baidu uses cuDNN for speech recognition, and on embedded deep learning on Jetson TK1. There is also a recent post about BIDMach, an accelerated framework for machine learning techniques that are not neural network-based (SVMs, K-means, linear regression and so on).
cuDNN v2: Performance for Deep Learning Practioners
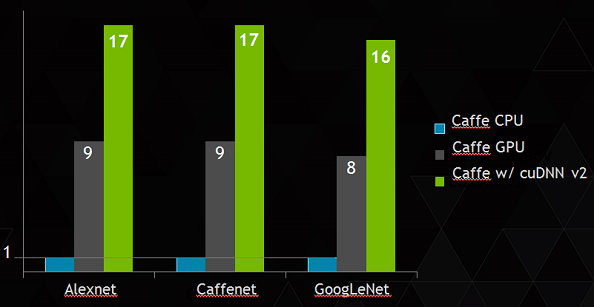
The primary goal of cuDNN v2 is to improve performance and provide the fastest possible routines for training (and deploying) deep neural networks for practitioners. This release significantly improves the performance of many routines, especially convolutions. In Figure 1, you can see that cuDNN v2 is nearly 20 times faster than a modern CPU at training large deep neural networks! Figure 1 compares speedup (relative to Caffe running on a 16-core Intel Haswell CPU) on three well-known neural network architectures: Alexnet, Caffenet and GoogLeNet. The grey bar shows the speedup of the native (legacy) Caffe GPU implementation, and the green bar shows the speedup obtained with cuDNN v2. Note that the speedup obtained with cuDNN v2 is now 80% higher than with the legacy Caffe GPU implementation.
cuDNN v2 now allows precise control over the balance between performance and memory footprint. Specifically, cuDNN allows an application to explicitly select one of four algorithms for forward convolution, or to specify a strategy by which the library should automatically select the best algorithm. Available strategies include “prefer fastest” and “use no additional working space”. The four forward convolution algorithms are IMPLICIT_GEMM, IMPLICIT_PRECOMP_GEMM, GEMM and DIRECT.
IMPLICIT_GEMM is the algorithm used in cuDNN v1. It is the only algorithm that supports all input sizes and configurations while using no extra working space. If your goal is to fit the largest possible neural network model into the memory of your GPU this is the recommended option.
The IMPLICIT_PRECOMP_GEMM algorithm is a modification of the IMPLICIT_GEMM approach, which uses a small amount of working space (see the Release Notes for details on how much) to achieve significantly higher performance than the original IMPLICIT_GEMM for many use cases.
The GEMM algorithm is an “im2col” approach, which explicitly expands the input data in memory and then uses a pure matrix multiplication. This algorithm requires significant working space, but in some cases it is the fastest approach. If you tell cuDNN to “prefer fastest”, it will sometimes choose this approach. You can use the SPECIFY_WORKSPACE_LIMIT instead of PREFER_FASTEST to ensure that the algorithm cuDNN chooses will not require more than a given amount of working space.
The DIRECT option is currently not implemented, so it is really just a placeholder. In a future version of cuDNN this will specify the usage of a direct convolution implementation. We will have guidelines on how this approach compares to the others when it is made available.
More Features and Capabilities for Users
Besides performance, there are other new features and capabilities in cuDNN v2 aimed at helping deep learning practitioners get the most out of their systems as easily as possible.
The cuDNN interface has been generalized to support data sets with other than two spatial dimensions (for example, 1D and 3D data). In fact, cuDNN now allows arbitrary N-dimensional tensors. This is a forward-looking change; most routines remain limited to two spatial dimensions. As a beta feature in this release, there is now support for 3D datasets (see the Release Notes for details). The cuDNN team is looking for community feedback on the importance of higher dimensional support.
Other new features include OS X support, zero-padding of borders in pooling routines (similar to what was already provided for convolutions), parameter scaling and improved support for arbitrary strides. A number of issues identified in cuDNN v1 have been resolved. cuDNN v2 will support the forthcoming Tegra X1 processor via PTX JIT compilation as well. Please see the cuDNN Release Notes for full details on all of these important developments!
Important API Changes
Several of the improvements described above required changes to the cuDNN API. Therefore, cuDNN v2 is not a drop-in version upgrade. Applications previously using cuDNN v1 are likely to need minor changes for API compatibility with cuDNN v2. Note that the Im2Col function is exposed as a public function in cuDNN v2, but it is intended for internal use only, and it will likely be removed from the public API in the next version.
cuDNN is still less than one year old. We expect cuDNN to mature rapidly, making API changes rare in the future. The cuDNN library team genuinely appreciates all feedback from the deep learning community, and carefully considers any API change.
Try cuDNN yourself!
cuDNN is free for anyone to use for any purpose: academic, research or commercial. Just sign up for a registered CUDA developer account. Once your account is activated, log in and you will see a link to the cuDNN download page. You will likely want to start by reading the included User Guide. Get started with cuDNN today!