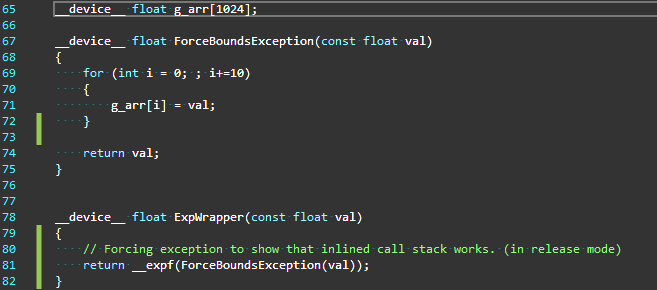
![]() Software development is as much about writing code fast as it is about writing fast code, and central to rapid development is software reuse and portability. When building heterogeneous applications, developers must be able to share code between projects, platforms, compilers, and target architectures. Ideally, libraries of domain-specific code should be easily retargetable.
Software development is as much about writing code fast as it is about writing fast code, and central to rapid development is software reuse and portability. When building heterogeneous applications, developers must be able to share code between projects, platforms, compilers, and target architectures. Ideally, libraries of domain-specific code should be easily retargetable.
In this post I’ll talk about Hemi, a simple open-source C++ header library that simplifies writing portable CUDA C/C++ code. In the screenshot below, both columns show a simple Black-Scholes code written to be compilable with either NVCC or a standard C++ host compiler, and also runnable on either the CPU or a CUDA GPU. The right column is written using Hemi’s macros and smart heterogeneous Array container class, hemi::Array. Using Hemi, the length and complexity of this code is reduced by half.
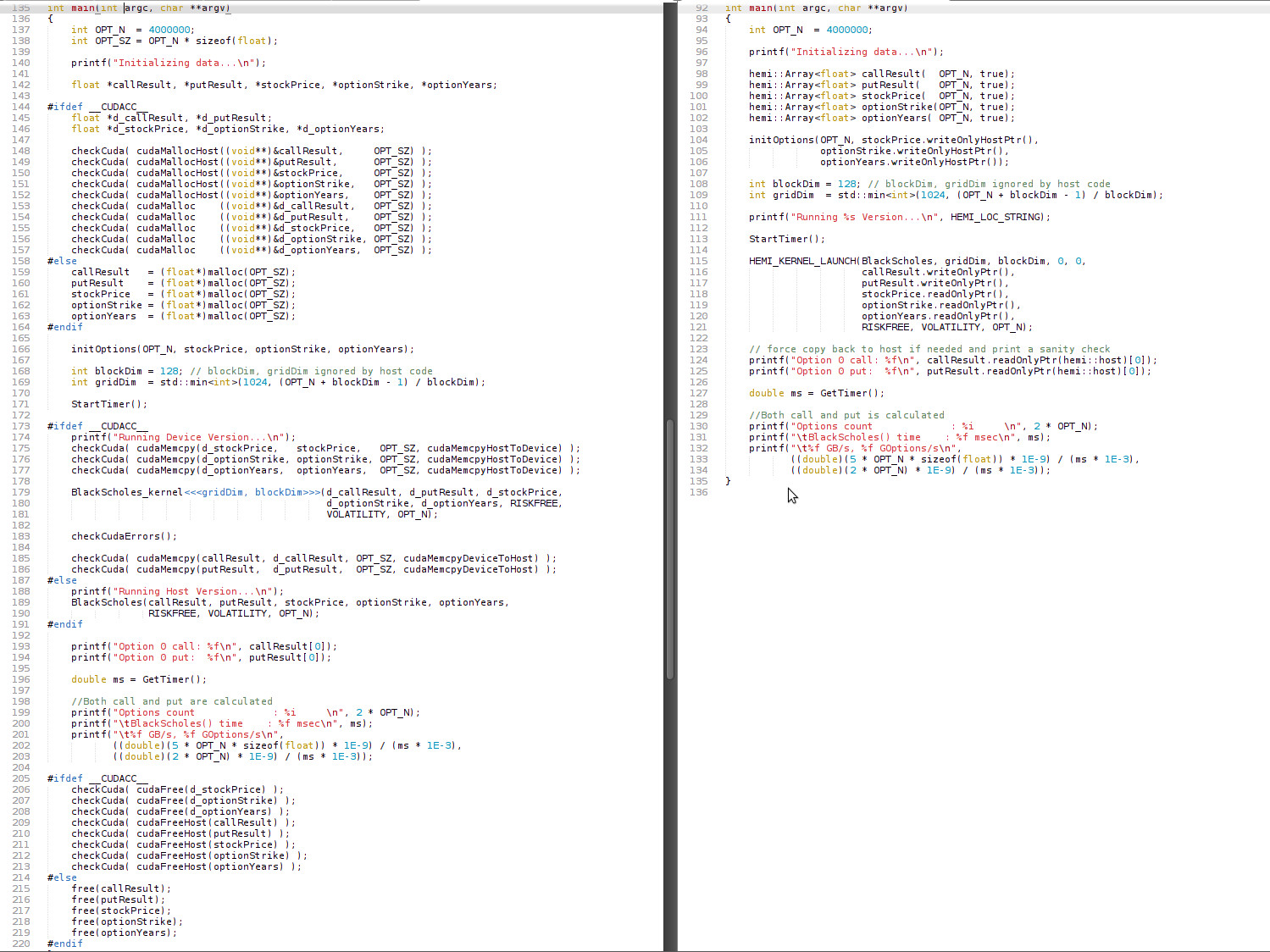
CUDA C++ and the NVIDIA NVCC compiler tool chain provide a number of features designed to make it easier to write portable code, including language-level integration of host and device code and data, declaration specifiers (e.g. __host__ and __device__) and preprocessor definitions (e.g. __CUDACC__). Together, these features enable developers to write code that can be compiled and run on either the host, the device, or both. But as the left column above shows, using them directly can result in complicated code. One cause of this is the code duplication that is required to support multiple target platforms, and another cause is the verbose memory management incurred by heterogeneous memory spaces. Hemi aims to tackle both problems.
Hemi is inspired by real-world CUDA software projects like PhysX and OptiX, which use custom libraries of preprocessor macros and container classes that enable the definition of portable application-specific libraries, classes, and kernels. PhysX, for example, has a comprehensive 3D vector math library that is portable across multiple platforms, including CUDA GPUs, Intel and other CPUs, and game consoles. To make CUDA memory management and transfers robust and simple to implement, PhysX uses a smart generic array class that automatically copies data between the device and host only when necessary. The result is much like the right-hand side of the screenshot above, with a minimum of memory management code and no explicit memory copies.
In this post I’ll describe Hemi in depth, but first I want to cover the CUDA C/C++ language and compiler features on which Hemi is built.
CUDA C++ Language Integration and Portability Features
Host / Device Functions
If you are already programming in CUDA C/C++ then you are familiar with __device__, the declaration specifier that indicates a function that is callable from other device functions and kernel (__global__) functions. CUDA also provides the __host__ declaration specifier for host (CPU) functions, which is the default in the absence of a specifier. Often we need to execute exactly the same code on the CPU and GPU, and in those cases we need to write functions that are callable from either the host or the device. In that case, __host__ and __device__ can be combined, as shown in the following inline function that averages two floats.
__host__ __device__ inline float avgf(float x, float y) { return (x+y)/2.0f; }
When NVCC sees this function, it generates two versions of the code, one for the host and one for the device. Any calls to the function from device code will execute the device version, and any calls from host code will execute the host version. This __host__ __device__ combination is very powerful because it enables large utility code bases to be used across heterogeneous applications, minimizing the work required to port applications. However, other compilers (obviously) don’t recognize these declaration specifiers, so to really write portable code, we need to use the C preprocessor.
CUDA Preprocessor Definitions
At compile time NVCC defines several macros that can be used to selectively enable and disable code based on whether it is being compiled by NVCC, whether it is device code or host code, and based on the architecture version (also called compute capability) it is being compiled for.
- __NVCC__
- Can be used in C/C++/CUDA source files to test whether they are currently being compiled by
nvcc. - __CUDACC__
- Can be used in source files to test whether they are being treated as CUDA source files by
nvcc. - __CUDA_ARCH__
- This architecture identification macro is assigned a three-digit value string
xy0(ending in a literal0) when compiling device codecompute_xy. For example, when compiling device code forcompute_20(orsm_20), __CUDA_ARCH__ will be defined bynvccto the value200. This macro can be used in the implementation of device and kernel functions to determine the virtual architecture for which it is currently being compiled. Host code must not depend on this macro, but note that it is not defined when host code is being compiled, which means that it can be used to detect compilation of device code.
The following example combines declaration specifiers and preprocessor macros to write a portable routine for counting the number of bits that are set in a 32-bit word.
#ifdef __CUDACC__
__host__ __device__
#endif
int countLeadingZeros(unsigned int a)
{
#if defined(__CUDA_ARCH__)
return __popc(a);
#else
// Source: http://graphics.stanford.edu/~seander/bithacks.html
a = a - ((a >> 1) & 0x55555555);
a = (a & 0x33333333) + ((a >> 2) & 0x33333333);
return ((a + (a >> 4) & 0xF0F0F0F) * 0x1010101) >> 24;
#endif
}
Here I have defined a function countLeadingZeros that is callable from either host or device code and due to the check for CUDACC wrapping “host device“, it is compilable using NVCC or other C/C++ compilers. Whether or not it is compiled with NVCC, it uses arithmetic on the CPU to count the 1 bits. On the device, it uses CUDA’s built-in __popc() intrinsic. If you look in CUDA’s device_functions.h header file, you’ll see that the value of __CUDA_ARCH__ is used to further differentiate; on Fermi and later GPUs (sm20, __CUDA_ARCH__ == 200) __popc() generates a single hardware population count instruction, while on earlier architectures it uses code similar to the host code.
Hemi: Easier Portable Code
As you can see, CUDA makes writing portable code feasible and flexible, but doing so is not particularly simple. Hemi, available on Github, provides just two simple header files (and a few examples) that make the task much easier, with much clearer code. The hemi.h header provides simple macros that are useful for reusing code between CUDA C/C++ and C/C++ written for other platforms (e.g. CPUs). The macros are used to decorate function prototypes and variable declarations so that they can be compiled by either NVCC or a host compiler (for example gcc or cl.exe, the MS Visual Studio compiler). The macros can be used within .cu, .cuh, .cpp, .h, and .inl files to define code that can be compiled either for the host or the device.
Before diving into the features of Hemi, let me draw your attention to the Hemi examples.
-
blackscholes: This is a simple example that performs a Black-Scholes options pricing calculation using code that is entirely shared between host code compiled with any C/C++ compiler (including NVCC) and device code that is compiled with NVCC. When compiled with “nvcc -x cu” (to force CUDA compilation on the .cpp file), this runs on the GPU. When compiled with “nvcc” or “g++” it runs on the host.
- blackscholes_nohemi: Just like the above, except it doesn’t use Hemi. This is just to demonstrate the complexity that Hemi eliminates.
- blackscholes_hostdevice: This example demonstrates how to write portable code that can be compiled to run the same code on both the host and device, in a single compile & run. This increase in run-time flexibility has a slight complexity cost, but all of the core computational code is reused.
- blackscholes_hemiarray: This example is the same as the “blackscholes” example, except that it uses hemi::Array to encapsulate CUDA-specific memory management code, and eliminate all explicit host-device memory copy code.
- nbody_vec4: This example brings all of Hemi’s features together. It implements a simple all-pairs n-body gravitational force calculation using a 4D vector class called Vec4f, which uses Hemi macros to enable all of the code for the class to be shared between host code compiled by the host compiler and device or host code compiled with NVCC. nbody_vec4 also shares most of the all-pairs gravitational force calculation code between device and host, and demonstrates how optimized device implementations (e.g. using shared memory) can be substituted as needed. Finally, this sample also uses hemi::Array to simplify memory management and data transfers.
Hemi Portable Functions
A typical use for host-device code sharing is commonly used utility functions. For example, here is a portable version of our earlier example function that averages two floats.
HEMI_DEV_CALLABLE_INLINE float avgf(float x, float y) { return (x+y)/2.0f; }
This function can be called either from host code or device code, and can be compiled by either the host compiler or NVCC. The macro definition ensures that when compiled by NVCC, both a host and device version of the function are generated, and a normal inline function is generated when compiled by the host compiler. For another example use, see the CND() function defined in the “blackscholes” example included with Hemi, as well as several other functions used in the examples.
Hemi Portable Classes
The HEMI_DEV_CALLABLE_MEMBER and HEMI_DEV_CALLABLE_INLINE_MEMBER macros can be used to create classes that are reusable between host and device code, by decorating any member function prototype that will be used by both device and host code. Here is an example excerpt of a portable class (a 4D vector type used in the “nbody_vec4” example).
struct HEMI_ALIGN(16) Vec4f
{
float x, y, z, w;
HEMI_DEV_CALLABLE_INLINE_MEMBER
Vec4f() {};
HEMI_DEV_CALLABLE_INLINE_MEMBER
Vec4f(float xx, float yy, float zz, float ww) : x(xx), y(yy), z(zz), w(ww) {}
HEMI_DEV_CALLABLE_INLINE_MEMBER
Vec4f(const Vec4f& v) : x(v.x), y(v.y), z(v.z), w(v.w) {}
HEMI_DEV_CALLABLE_INLINE_MEMBER
Vec4f& operator=(const Vec4f& v) {
x = v.x; y = v.y; z = v.z; w = v.w;
return *this;
}
HEMI_DEV_CALLABLE_INLINE_MEMBER
Vec4f operator+(const Vec4f& v) const {
return Vec4f(x+v.x, y+v.y, z+v.z, w+v.w);
}
...
};
The HEMI_ALIGN macro is used on types that will be passed in arrays or pointers as arguments to CUDA device kernel functions, to ensure proper alignment. HEMI_ALIGN generates correct alignment specifiers for host compilers, too. For details on alignment, see the NVIDIA CUDA C Programming Guide (Section 5.3 in v5.0).
NOTE: DEVICE-SPECIFIC CODE
Code in functions declared with HEMI_DEV_CALLABLE_* must be portable. In other words it must compile and run correctly for both the host and the device. If it does not, within the function you can use HEMI_DEV_CODE (which reduces to __CUDA_ARCH__) to define separate code for host and device, as in the following example.
HEMI_DEV_CALLABLE_INLINE_MEMBER
float inverseLength(float softening = 0.0f) const {
#ifdef HEMI_DEV_CODE
return rsqrtf(lengthSqr() + softening); // use fast GPU intrinsic
#else
return 1.0f / sqrtf(lengthSqr() + softening);
#endif
}
If you need to write a function only for the device, use the CUDA C __device__ specifier directly.
Note: Non-inline functions and methods
Take care when using the non-inline versions of the declaration specifier macros (HEMI_DEV_CALLABLE and HEMI_DEV_CALLABLE_MEMBER) to avoid multiple definition linker errors due to using these in headers that are included into multiple compilation units. The best way to use HEMI_DEV_CALLABLE is to declare functions using this macro in a header, and define their implementation in a .cu file, and compile it with NVCC. This will generate code for both host and device. The host code will be linked into your library or application and callable from other host code compilation units (.c and .cpp files). Likewise, for HEMI_DEV_CALLABLE_MEMBER, put the class and function declaration in a header, and the member function implementations in a .cu file, compiled by NVCC.
Hemi Portable Kernels
Use HEMI_KERNEL to declare functions that are launchable as CUDA kernels when compiled with NVCC, or callable as C/C++ (host) functions when compiled with the host compiler. HEMI_KERNEL_LAUNCH is a convenience macro that launches a kernel function on the device when compiled with NVCC, or calls the host function when compiled with the host compiler. For example, here is an excerpt from the “blackscholes” example, which is a single .cpp file that can be either compiled with NVCC to run on the GPU, or compiled with the host compiler to run on the CPU.
// Black-Scholes formula for both call and put
HEMI_KERNEL(BlackScholes)
(float *callResult, float *putResult, const float *stockPrice,
const float *optionStrike, const float *optionYears, float Riskfree,
float Volatility, int optN)
{
...
}
// ... in main() ...
HEMI_KERNEL_LAUNCH(BlackScholes, gridDim, blockDim, 0, 0,
d_callResult, d_putResult, d_stockPrice, d_optionStrike,
d_optionYears, RISKFREE, VOLATILITY, OPT_N);
HEMI_KERNEL_LAUNCH requires grid and block dimensions to be passed to it, but these parameters are ignored when compiled for the host. When DEBUG is defined, HEMI_KERNEL_LAUNCH checks for CUDA launch and run-time errors. You can use HEMI_KERNEL_NAME to access the generated name of the kernel function, for example to pass a function pointer to CUDA API functions like cudaFuncGetAttributes().
Iteration
For kernel functions with simple independent element-wise parallelism, Hemi provides two functions to enable iterating over elements sequentially in host code or in parallel in device code.
hemiGetElementOffset()returns the offset of the current thread within the 1D grid, or zero for host code. In device code, it resolves toblockDim.x * blockIdx.x + threadIdx.x.hemiGetElementStride()returns the size of the 1D grid in threads, or one in host code. In device code, it resolves togridDim.x * blockDim.x.
The “blackscholes” example demonstrates iteration in the following function, which can be compiled and run as a sequential function on the host or as a CUDA kernel on the device.
// Black-Scholes formula for both call and put
HEMI_KERNEL(BlackScholes)
(float *callResult, float *putResult, const float *stockPrice,
const float *optionStrike, const float *optionYears, float Riskfree,
float Volatility, int optN)
{
int offset = hemiGetElementOffset();
int stride = hemiGetElementStride();
for(int opt = offset; opt < optN; opt += stride)
{
// ... compute call and put value based on Black-Scholes formula
}
}
Note: the hemiGetElement*() functions are specialized to simple (but common) element-wise parallelism. As such, they may not be useful for arbitrary strides, data sharing, or other more complex parallelism arrangements; but they may serve as examples for creating your own.
Hemi Portable Constants
Global constant values can be defined using the HEMI_DEFINE_CONSTANT macro, which takes a name and an initial value. When compiled with NVCC as CUDA code, this declares two versions of the constant, one __constant__ variable for the device, and one normal host variable. When compiled with a host compiler, only the host variable is defined. For static or external linkage, use the HEMI_DEFINE_STATIC_CONSTANT and HEMI_DEFINE_EXTERN_CONSTANT versions of the macro, respectively. To access variables defined using HEMI_DEFINE_*_CONSTANT macros, use the HEMI_CONSTANT macro which automatically resolves to either the device or host constant depending on whether it is called from device or host code. This means that the proper variable will be chosen when the constant is accessed within functions declared with HEMI_DEV_CALLABLE_* and HEMI_KERNEL macros.
To explicitly access the device version of a constant, use HEMI_DEV_CONSTANT. This is useful when the constant is an argument to a CUDA API function such as cudaMemcpyToSymbol, as shown in the following code from the “nbody_vec4” example.
cudaMemcpyToSymbol(HEMI_DEV_CONSTANT(softeningSquared),
&ss, sizeof(float), 0, cudaMemcpyHostToDevice)
Hemi Portable Data: hemi::Array
One of the biggest challenges in writing portable CUDA code is memory management. Hemi provides the hemi::Array C++ template class (defined in hemi/array.h), a simple data management container which allows arrays of arbitrary type to be created and used with both host and device code. hemi::Array maintains a host and a device pointer for each array. It lazily transfers data between the host and device as needed when the user requests a pointer to the host or device memory. Pointer requests specify read-only, read/write, or write-only options to keep the valid location of data up-to-date and only copy data when the requested pointer is invalid. hemi::Array supports pinned host memory for efficient PCI-express transfers, and handles CUDA error checking internally.
Here is an excerpt from the nbody_vec4 example.
hemi::Array<Vec4f> bodies(N, true);
hemi::Array<Vec4f> forceVectors(N, true);
randomizeBodies(bodies.writeOnlyHostPtr(), N);
// Call host function defined in a .cpp compilation unit
allPairsForcesHost(forceVectors.writeOnlyHostPtr(), bodies.readOnlyHostPtr(), N);
printf("CPU: Force vector 0: (%0.3f, %0.3f, %0.3f)n",
forceVectors.readOnlyHostPtr()[0].x,
forceVectors.readOnlyHostPtr()[0].y,
forceVectors.readOnlyHostPtr()[0].z);
...
// Call device function defined in a .cu compilation unit
// that uses host/device shared functions and class member functions
allPairsForcesCuda(forceVectors.writeOnlyDevicePtr(),
bodies.readOnlyDevicePtr(), N, false);
printf("GPU: Force vector 0: (%0.3f, %0.3f, %0.3f)n",
forceVectors.readOnlyHostPtr()[0].x,
forceVectors.readOnlyHostPtr()[0].y,
forceVectors.readOnlyHostPtr()[0].z);
Typical CUDA code requires explicit duplication of host allocations on the device, and explicit copy calls between them, along with error checking for all allocations and transfers. The “blackscholes_hemiarray” example demonstrates how much hemi::Array simplifies CUDA C code, doing with 136 lines of code what the “blackscholes” example does in 180 lines.
Hemi CUDA Error Checking
hemi.h provides two convenience functions for checking CUDA errors. checkCuda verifies that its single argument has the value cudaSuccess, and otherwise prints an error message and asserts if #DEBUG is defined. This function is typically wrapped around CUDA API calls, as in the following.
checkCuda( cudaMemcpy(d_stockPrice, stockPrice, OPT_SZ, cudaMemcpyHostToDevice) );
checkCudaErrors takes no arguments and checks the current state of the CUDA context for errors. This function synchronizes the CUDA device (cudaDeviceSynchronize()) to ensure asynchronous launch errors are caught. Both checkCuda and checkCudaErrors act as No-ops when DEBUG is not defined (release builds).
Summary: Mix and Match
I designed Hemi to provide a loosely-coupled set of utilities and examples for creating reusable, portable CUDA C/C++ code. Feel free to use the parts that you need and ignore others, or modify and replace portions to suit the needs of your projects. Or just use it as an example and develop your own utilities for writing flexible and portable CUDA code. If you make changes that you feel would be generally useful, please fork the project on github, commit your changes, and submit a pull request! If you would like to give feedback about Hemi, please leave a comment below or file an issue on Github.