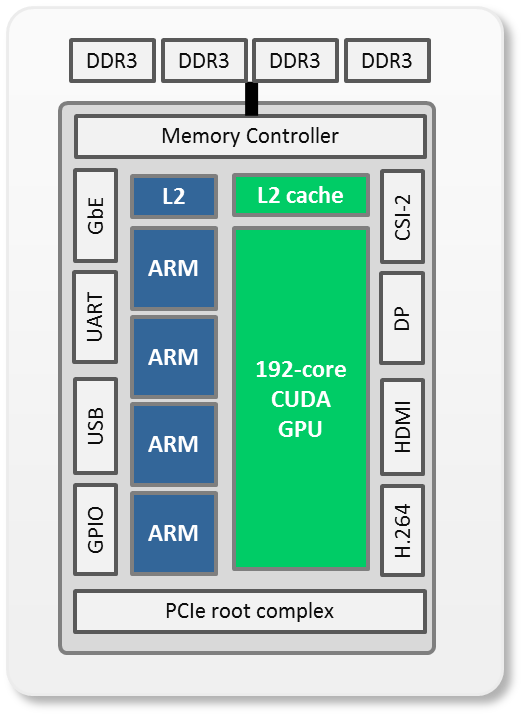
NVIDIA’s Tegra K1 (TK1) is the first Arm system-on-chip (SoC) with integrated CUDA. With 192 Kepler GPU cores and four Arm Cortex-A15 cores delivering a total of 327 GFLOPS of compute performance, TK1 has the capacity to process lots of data with CUDA while typically drawing less than 6W of power (including the SoC and DRAM). This brings game-changing performance to low-SWaP (Size, Weight and Power) and small form factor (SFF) applications in the sub-10W domain, all the while supporting a developer-friendly Ubuntu Linux software environment delivering an experience more like that of a desktop rather than an embedded SoC.
Tegra K1 is plug-and-play and can stream high-bandwidth peripherals, sensors, and network interfaces via built-in USB 3.0 and PCIe gen2 x4/x1 ports. TK1 is geared for sensor processing and offers additional hardware-accelerated functionality asynchronous to CUDA, like H.264 encoding and decoding engines and dual MIPI CSI-2 camera interfaces and image service processors (ISP). There are many exciting embedded applications for TK1 which leverage its natural ability as a media processor and low-power platform for quickly integrating devices and sensors.
As GPU acceleration is particularly well-suited for data-parallel tasks like imaging, signal processing, autonomy and machine learning, Tegra K1 extends these capabilities into the sub-10W domain. Code portability is now maintained from NVIDIA’s high-end Tesla HPC accelerators and the GeForce and Quadro discrete GPUs, all the way down through the low-power TK1. A full build of the CUDA 6 toolkit is available for TK1, including samples, math libraries such as cuFFT, cuBLAS, and NPP, and NVIDIA’s NVCC compiler. Developers can compile CUDA code natively on TK1 or cross-compile from a Linux development machine. Availability of the CUDA libraries and development tools ensures seamless and effortless scalability between deploying CUDA applications on discrete GPUs and on Tegra. There’s also OpenCV4Tegra available as well as NVIDIA’s VisionWorks toolkit. Additionally the Ubuntu 14.04 repository is rich in pre-built packages for the Arm architecture, minimizing time spent tracking down and building dependencies. In many instances applications can be simply recompiled for Arm with little modification, as long as source is available and doesn’t explicitly call out x86-specific instructions like SSE, AVX, or x86-ASM. NEON is Arm’s version of SIMD extensions for Cortex-A series CPUs.
Tegra Tip:
For more information about availability of Jetson TK1 devkits, visit this link: https://developer.nvidia.com/jetson-tk1
See this page for information about rugged SFF modules and other 3rd-party embedded products powered by Tegra.
With NVIDIA’s Jetson TK1 devkit, TK1 is accessible to everyone. Supporting the same desktop-like user environment, the Jetson TK1 is used as an effective development platform for embedded applications deploying rugged, extended-temperature SFF modules. Via PCIe x4 gen2, modules can be integrated with a variety of I/O mezzanines providing many possible interfaces for Tegra. Additionally, there’s native onboard Gigabit Ethernet for streaming networked sensors or interconnecting multiple Tegras. Let’s consider a case study which highlights TK1’s ability to easily integrate sensors and support high-bandwidth streaming.
Case Study #1: Robotics/Unmanned Vehicle Platform
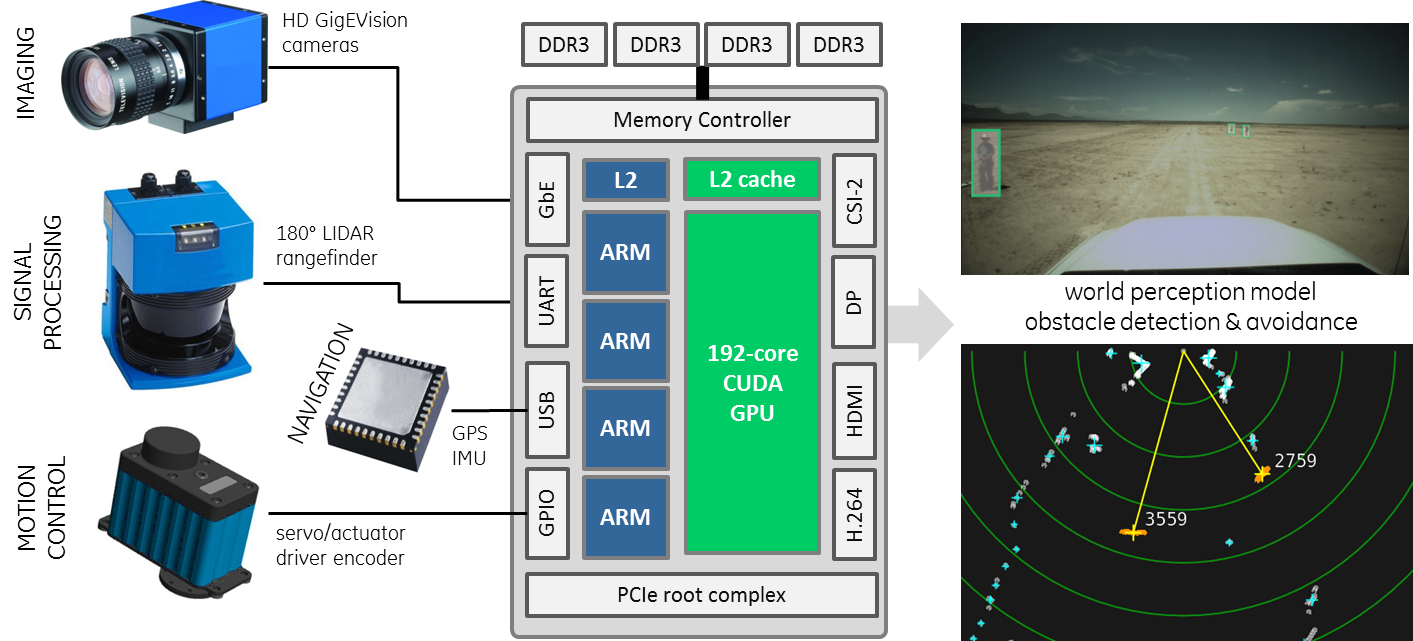
Embedded applications commonly require elements of video processing, digital signal processing (DSP), command and control, and so on. In this example architecture with Tegra K1, we use CUDA to process imagery from high-definition GigEVision gigabit cameras and simultaneously perform world-mapping and obstacle detection operations on a 180° Light Detection and Ranging (LIDAR) scanning rangefinder. Additionally we integrate devices such as GPS receivers, inertial measurement unit (IMU), motor controllers, and other sensors to demonstrate using TK1 for autonomous navigation and motion control of a mobile platform (such as a robot or UAV). Teleoperation capability is provided by applying Tegra’s hardware-accelerated H.264 compression to the video and streaming over WiFi, 3G/4G, or satellite downlink to a remote ground station or other networked robot. This architecture provides an example framework for perception modeling and unmanned autonomy using TK1 as the system’s central processor and sensor interface.
Tegra Tip:
By default, the Jetson TK1’s serial port is configured as a debug console, providing kernel output and login shell. To enable the serial port for general-purpose use, execute this command as root:
mv /etc/init/ttyS0.conf /etc/init/ttyS0.conf.DISABLED
Then reflash the Jetson TK1’s kernel and reassign the console parameter:
./flash.sh –k 6 –C ‘console=tty1’ jetson-tk1 mmcblk0p1
The scanning LIDAR we used produces range samples every 0.5° over 180 degrees, which are grouped into clusters using mean shift and tracked when motion is detected. CUDA was used to process all range samples simultaneously and perform change detection versus the octree-partitioned 3D point cloud built from previous georeferenced LIDAR scans, producing a list of static and moving obstacles refreshed in realtime for collision detection and avoidance. A radar-like Plan Position Indicator (PPI) is then rendered on the OpenGL side. This particular LIDAR was connected via RS232 to the Jetson TK1’s serial port; other LIDARs support Gigabit Ethernet as well. We used the open-source SICK Toolbox library for connecting to the sensor, which compiles and runs out of the box on TK1. Having easy access to LIDAR sensors provides TK1 with sub-millimeter accurate readings to exploit with CUDA for realtime 3D environment mapping and parallel path planning.
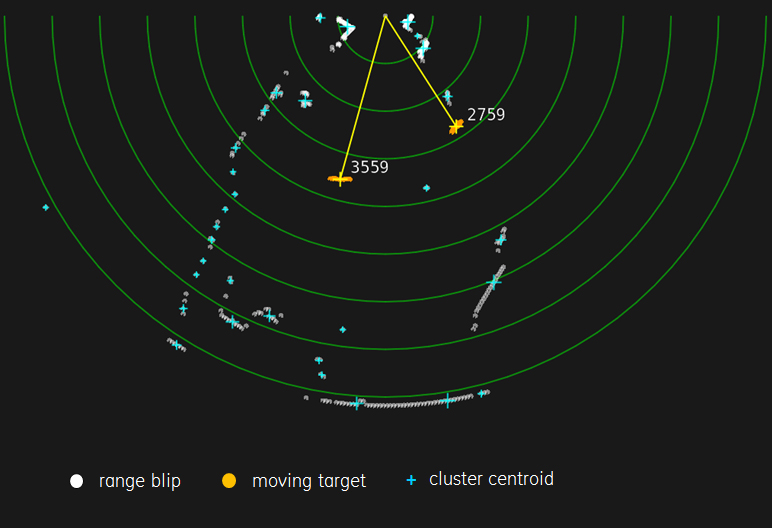
Tegra Tip:
To increase networking performance, increase the socket buffer sizes (in this case to 32MB, performed at boot):
sysctl –w net.core.rmem_max=33554432
sysctl –w net.core.wmem_max=33554432
sysctl –w net.core.rmem_default=33554432
sysctl –w net.core.wmem_default=33554432
On the imaging side, Tegra K1 has a number of interfaces for streaming high-definition video, such as CSI-2, USB 3.0, and Gigabit Ethernet. Framegrabbers for other mediums like HD-SDI, CameraLink, LVDS, and others can be integrated with TK1 via its PCIe gen2 x4 port. For this case study, we tested with multiple Gigabit Ethernet cameras from GigEVision-compliant vendors, with resolutions ranging from 1920×1080 up to 2448×2048, and found an individual Arm CPU core sufficient per Gigabit Ethernet port for handling network protocols and packetization using the sockets API. Using the cudaMallocManaged() Unified Memory feature new to CUDA 6, the video stream is depacketized by the CPU into a buffer shared with the GPU, requiring zero copies to get the video “into GPU memory” (in the case of TK1, it’s physically all the same memory).
Using freely-available libraries like OpenCV, NVIDIA NPP, and VisionWorks, users have the ability to run a myriad of CUDA-accelerated video filters on-the-go including optical flow, SLAM, stereo disparity, robust feature extraction and matching, mosaicking, and multiple moving target indicator (MMTI).

Trainable pedestrian and vehicle detectors can run in realtime on TK1 using available Histogram of Oriented Gradients (HoG) implementations. There are many existing CUDA codes available which previously ran on discrete GPUs and are now able to be deployed on Tegra.
Tegra Tip:
Developer support for USB and GPS devices can easily be installed from the Ubuntu repository:
sudo apt-get install libgps-dev libusb-0.1-dev
Most Linux USB/serial drivers are architecture-independent and transition easily to an Arm-hosted environment.
In addition to LIDAR devices and cameras, TK1 supports navigational sensors such as GPS and IMU for improved autonomy. These are commonly available as USB or serial devices and can easily be integrated with TK1. One quick way to make a GPS-enabled application is to use libgps/gpsd, which provides a common software interface and GPS datagram for a wide class of NMEA-compliant devices. Meanwhile IMU sensors are integrated to provide accelerometer, gyro, and magnetometer readings at refresh rates of up to 100Hz or more. TK1 fuses the rapid IMU and GPS data using high-quality Kalman filtering to deliver realtime interpolated platform positions in 3-space, and then uses these interpolations to further refine visual odometry from optical flow. While less standardized than the NMEA-abiding GPS units, IMU devices commonly ship with vendor-supplied C/C++ code intended to link with libusb, a standard userspace driver interface for accessing USB devices on Linux. Such userspace drivers leveraging libusb require little effort to migrate from x86 to Arm and enable developers to quickly integrate various devices with TK1 like MOSFET or PWM motor controllers for driving servos and actuators, voltage and current sensors for monitoring battery life, gas/atmospheric sensors, ADCs /DACs, and so on depending on the application at hand. Also Tegra K1 features six GPIO ports for driving discrete signals, useful for connecting switches, buttons, relays, and LEDs.
This case study accounts for common sensory and computing aspects typically found in robotics, machine vision, remote sensing, and so on. TK1 provides a developer-friendly environment which takes the legwork out of integration and makes deploying embedded CUDA applications easy while delivering superior performance.
Case Study #2: Tiled Tegra
Some applications may require multiple Tegras working in tandem to meet their requirements. Clusters of Tegra K1 SoCs can be tiled and interconnected with PCIe or ethernet. The size, weight, and power advantages gained from implementing such a tiled architecture are substantial and extend the applicability of TK1 into the datacenter and high-performance computing (HPC). Densely distributed topologies with 4, 6, 8 or more K1 SoCs tiled per board are possible and provide scalability beneficial for embedded applications and HPC alike. Consider this example based on an existing embedded system, employing six Tegra K1s:
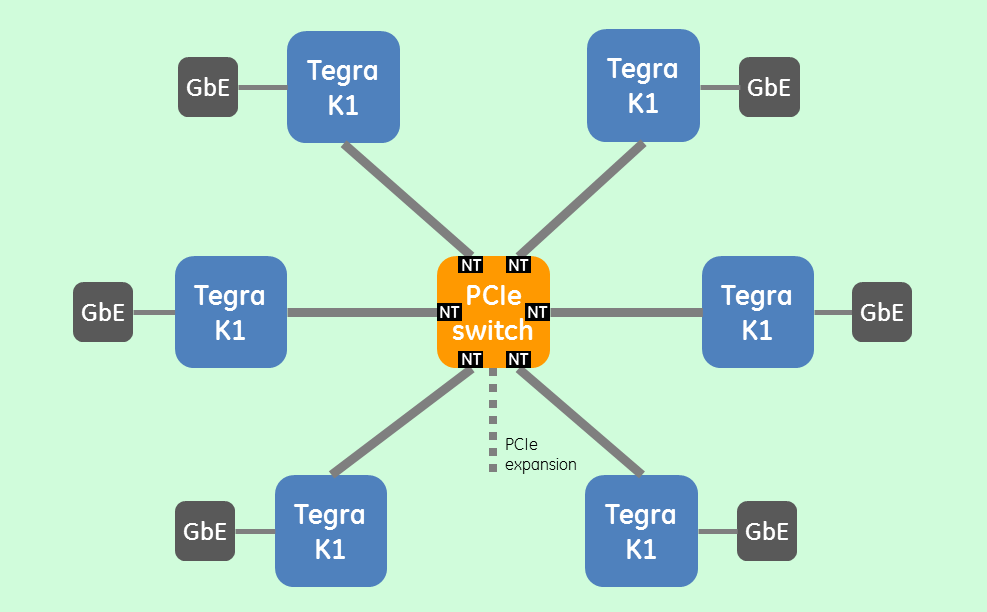
The six TK1s are interconnected via PCIe gen2 x4 and a 32-lane PCIe switch with nontransparent (NT) bridging and DMA offload engines. This along with a lightweight userspace RDMA library provides low-overhead inter-processor communication between TK1s. Meanwhile sensor interfaces are provided by a Gigabit Ethernet NIC/PHY connected to each Tegra’s PCIe gen2 x1 port. There’s also a spare PCIe x8 expansion brought out from the PCIe switch for up to 4GB/s of off-board connectivity to user-determined I/O interfaces.
| Power Typ. (W) | Power Ext. (W) | ||
| 6x | Tegra K1 SoC | 5.8 | 34.8 |
| 6x | gigabit NIC/PHY | 1.2 | 7.2 |
| 1x | 32-lane PCIe switch w/ DMA | 6.8 | 6.8 |
| Total power | 48.8W | ||
| Total compute | 1.938 TFLOPS |
A tiled solution like this is capable of nearly 2 TFLOPS of compute performance while drawing less than 50W, and represents a large increase in the efficiency of low-power clustered SoCs over architectures that utilize higher-power discrete components. The decrease in power enables us to place and route all components onboard, resulting in connector-less intercommunication and improved signal integrity and ruggedization. Useful for big data analytics, multi-channel video and signal processing, and machine learning, distributed architectures with TK1 offer substantial performance gains for those truly resource-intensive applications requiring computational density while minimizing SWAP.
Impossibly Advanced
The ground-breaking computational performance of Tegra K1, driven by NVIDIA’s low-power optimizations and the introduction of integrated CUDA, leads a new generation of embedded devices and platforms that leverage TK1’s SWaP density to deliver advanced features and capabilities. NVIDIA and GE have partnered to bring rugged SFF modules and systems powered by TK1 to the embedded space. Applications in robotics, medical and man-wearable devices, software-defined radio, security, surveillance, and others are prime candidates for acceleration with Tegra K1. What’s more is that TK1’s ease-of-use promotes scalable, portable embedded systems with shortened development cycles, only furthered by the wealth of existing CUDA libraries and software that now run on Tegra. What will you build today with TK1?