The Java ecosystem is the leading enterprise software development platform, with widespread industry support and deployment on platforms like the IBM WebSphere Application Server product family. Java provides a powerful object-oriented programming language with a large developer ecosystem and developer-friendly features like automated memory management, program safety, security and runtime portability, and high performance features like just-in-time (JIT) compilation.
Java application developers face increasingly complex challenges, with big data and analytics workloads that require next generation performance. Big data pushes the scale of the problem to a new level with multiple hundreds of gigabytes of information common in these applications, while analytics drive the need for higher computation speeds.
The Java platform has evolved by adding developer support for simpler parallel programming through the fork/join framework and concurrent collection APIs. Most recently, Java 8 adds support for lambda expressions, which can simplify the creation of highly parallel applications using Java.
IBM’s POWER group partnered with NVIDIA to make GPUs available on a high-performance server platform, promising the next generation of parallel performance for Java applications. We decided to bring GPU support to Java incrementally using three approaches.

IBM’s new Power S824L is a data processing powerhouse that integrates the NVIDIA Tesla Accelerated Computing Platform (Tesla GPUs and enabling software) with IBM’s POWER8 processor.
Enabling CUDA for Java developers
Our first step brings capabilities of the CUDA programming model into the Java programming environment. Java developers familiar with CUDA concepts can use the new IBM CUDA4J library, which provides a Java API for managing and accessing GPU devices, libraries, kernels, and memory. Using these new APIs it is possible to write Java programs that manage GPU device characteristics and offload work to the GPU with the convenience of the Java memory model, exceptions, and automatic resource management that Java developers expect.
Listing 1 shows a simple example that uses the CUDA4J APIs.
void add(int[] a, int[] b, int[] c) throws CudaException,IOException {
CudaDevice device = new CudaDevice(0);
CudaModule module = new CudaModule(device,
getClass().getResourceAsStream(“ArrayAdder”));
CudaKernel kernel =
new CudaKernel(module, “Cuda_cuda4j_samples_adder”);
CudaGrid grid = new CudaGrid(512, 512);
try (CudaBuffer aBuffer = new CudaBuffer(device, a.length * 4);
CudaBuffer bBuffer = new CudaBuffer(device, b.length * 4)) {
aBuffer.copyFrom(a, 0, a.length);
bBuffer.copyFrom(b, 0, b.length);
kernel.launch(grid,
new CudaKernel.Parameters(aBuffer, aBuffer, bBuffer, a.length));
aBuffer.copyTo(c, 0, a.length);
}
}
extern “C”
__global__
void Cuda_cuda4j_samples_adder(int * result,
int * a,
int * b,
int length)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < length) result[i] = a[i] + b[i];
}
The Java code shown in Listing 1 uses an existing kernel, ArrayAdder, to add two Java int arrays on the GPU. The code uses the CUDA4J APIs to get a reference to the GPU device, load the ArrayAdder kernel from a CUDA module and define the processing grid that will execute the kernel. The ArrayAdder kernel function is simple CUDA C++ code shown in Listing 2, and compiled with the NVIDIA CUDA compiler, nvcc. With the kernel defined, the code uses Java language features to safely copy the parameters to and from GPU memory using the CudaBuffer type, with the actual processing done during the kernel.launch() invocation.
CUDA4J API calls throw a Java exception if an error occurs, saving you from the burden of explicitly checking return codes. The host and device memory are automatically freed when they go out of scope.
However, CUDA4J is a toolkit. It requires Java developers to know when it makes sense to shift workloads to the GPU. These workloads need to be suitable for efficient processing using multiple parallel threads, and must perform sufficient work to offset the cost of transferring Java data to the GPU. Developers using CUDA4J make these decisions themselves.
Accelerating Core Java APIs
What about the core Java SE APIs? Which of these can effectively make use of GPU performance and capabilities, and can GPU acceleration be done transparently to the user’s application code?
There are obvious cases where existing GPU libraries and kernels closely match core Java APIs, so to begin with, we modified java.util.Arrays#sort with heuristics to determine when it should use the GPU for sorting.
When there is a GPU available and the problem is of sufficient size, our implementation of the standard Java API offloads the sorting task to the GPU. The semantics of the API call are unchanged, and with the GPU-enabled Java runtime the application enjoys an improvement in performance without having to modify any application code.
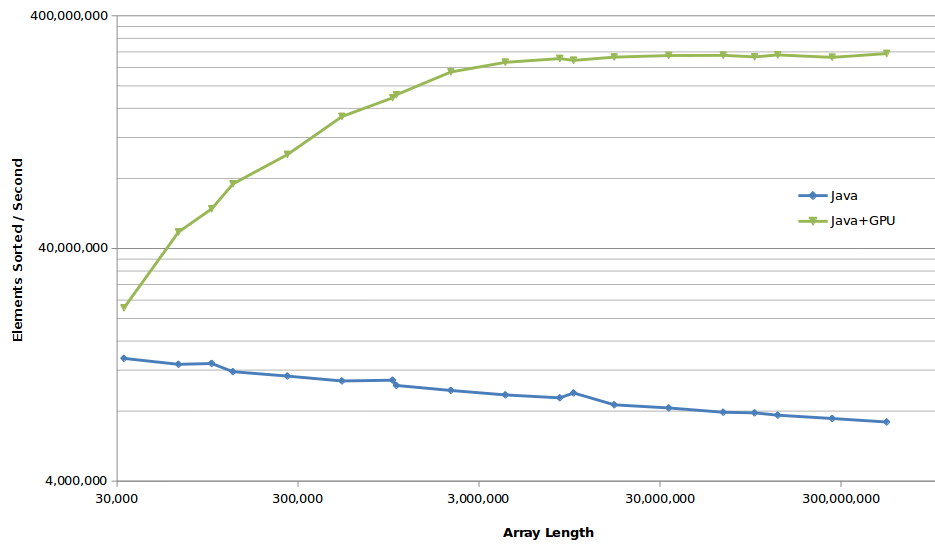
MARKDOWN_HASH1df11c01e2229c10958889f0fdb46ef4MARKDOWN_HASH on NVIDIA Tesla K40 GPU (ECC enabled) and IBM Power8 CPU.Figure 2 compares Java’s original sort performance to our GPU-enabled sort. You can see in this graph how Java’s dual pivot comparison quicksort algorithm on the CPU offers 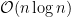
By comparison the GPU-based Thrust::sort rate continues to improve performance well above three million elements based on its 
int types. Furthermore, when we run large sorts on the GPU, the CPU is freed-up to work on other tasks.
We continue to seek opportunities to seamlessly exploit the power of the GPU in our Java implementation—using the characteristics of IBM Power processors and NVIDIA GPUs.
Programming GPUs with Pure Java
After we had demonstrated the benefit to core Java APIs, we started to look at enabling user code directly. New parallel programming concepts introduced in Java 8 help here, especially lambda expressions.
Lambda expressions are blocks of code that can be assigned to variables and passed as arguments to methods. Their use can greatly simplify many coding tasks in Java that previously required creating a lot of boilerplate code (for example, coordinating and synchronizing multiple threads). Moreover, Java’s lambda expressions enable you to succinctly encapsulate the operations to be performed on each element of a stream of data. You can indicate that such operations can be executed in parallel.
With this level of expressiveness the Java runtime’s just in time compiler (JIT) can decide whether the expression is better run on the CPU or GPU and generate native code appropriately. Again, this doesn’t require any modifications to the application code, and the effect of the operations is the same in both cases.
public static
int[] multiply(int[] left, int[] right, int cols) {
assert (left.length == right.length);
assert (left.length == cols * cols);
int[] result = new int[left.length];
IntStream.range(0, cols * cols).parallel().forEach(id -> {
int i = id / cols;
int j = id % cols;
int sum = 0;
for (int k = 0; k < cols; k++) {
sum += left[i * cols + k] * right[k * cols + j];
}
result[i * cols + j] = sum;
});
return result;
}
As an example of how Java code can be automatically compiled to the GPU, Listing 3 shows a simple lambda expression for square matrix multiplication. In the multiply() method the IntStream range of numbers executes a lambda expression in parallel.
In normal operation, the method executes on the CPU. When the JIT compiles this method, it can recognize the lambda as being suitable for optimization on the GPU. In this case, where the lambda contains simple mathematical operations, the JIT can compile the Java method straight to the GPU and enjoy a significant speed-up.
Executing lambdas in parallel streams should be managed carefully due to overheads. We noticed that there is a measurable overhead in executing the work in parallel on the CPU. When the number of elements in the stream is small, it is better to spend time on a single CPU thread than incur the overhead of splitting work across multiple CPU threads, joining the threads, and merging results together again.
We see a similar dip in performance when moving small arrays for sorting on the GPU, though different overheads are likely to blame (for example, data copying from host to device, kernel launch to GPU, and so on). We are currently investigating techniques to minimize these.

Figure 3 shows the relative performance of lambda optimizations. In this graph, we normalized all measurements relative to the corresponding serial lambda execution times to clearly show the impact of using parallel operations both on the CPU and GPU. The Y-axis represents the speed-up factor, that is, each data point shows how much faster or slower the operation was than a serial invocation of the same lambda expression.
In our configuration, we observed a significant penalty for executing small workloads in parallel on the CPU. The GPU is less prone to this parallelism overhead, but still required a workload of 128×128 matrix multiplication to get better performance than executing the lambda serially on the CPU. When the matrices reach 1024×1024, executing the lambda in parallel runs nearly 50x faster on the CPU and over 200x faster on the GPU than serially on the CPU, so the benefits are significant.
JIT compilation to GPUs is still in its early days. Currently, only a limited set of Java operations can be automatically offloaded to the GPU. However, as we continue to work in this area, we expect it to be possible to delegate complex Java code to GPUs.
A Bright Future for Java on GPUs
Runtime compilation and GPU offloading is a rich area for future Java enhancements as we look to provide closer integration of the GPU with the Java programming language and object model layout.
The close partnership between IBM and NVIDIA promises to deliver exciting opportunities for Java developers to experience the capabilities of the GPU. From the new Java GPU programming APIs, to runtime compilation of application code onto GPUs, users of IBM POWER systems and NVIDIA GPUs can enjoy world-class performance of their Java applications.