Today I’m excited to announce the release of CUDA 6, a new version of the CUDA Toolkit that includes some of the most significant new functionality in the history of CUDA. In this brief post I will share with you the most important new features in CUDA 6 and tell you where to get more information. You may also want to watch the recording of my talk “CUDA 6 and Beyond” from last month’s GPU Technology Conference, embedded below.
Without further ado, if you are ready to download the CUDA Toolkit version 6.0 now, by all means, go get it on CUDA Zone. The five most important new features of CUDA 6 are
- support for Unified Memory;
- CUDA on Tegra K1 mobile/embedded system-on-a-chip;
- XT and Drop-In library interfaces;
- remote development in NSight Eclipse Edition;
- many improvements to the CUDA developer tools.
Unified Memory
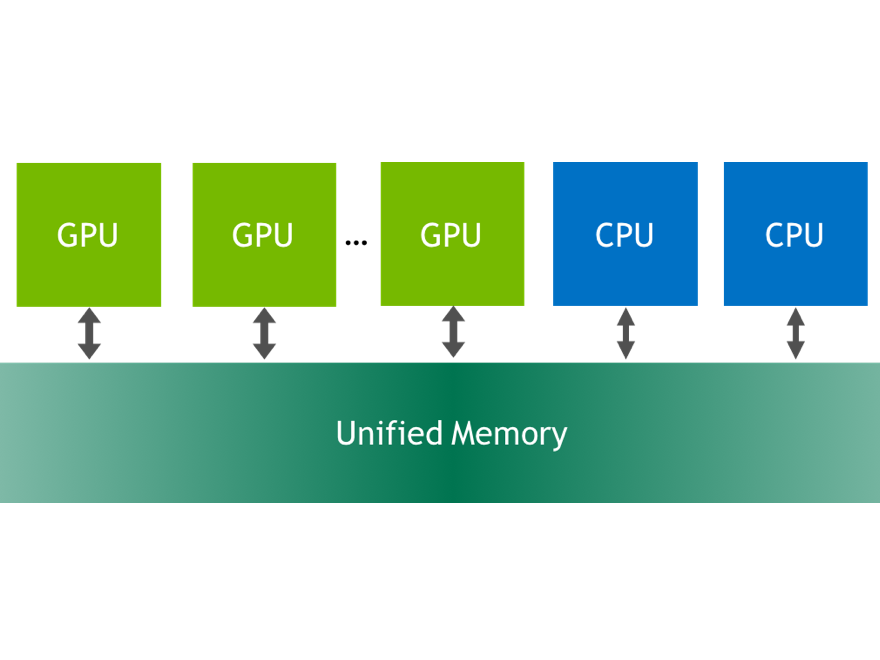
CUDA 6 introduces one of the most dramatic programming model improvements in the history of the CUDA platform, Unified Memory. In a typical PC or cluster node today, the memories of the CPU and GPU are physically distinct and separated by the PCI-Express bus. Before CUDA 6, that is exactly how the programmer has to view things. Data shared between the CPU and GPU must be allocated in both memories, and explicitly copied between them by the program. This can add a lot of complexity to CUDA programs.
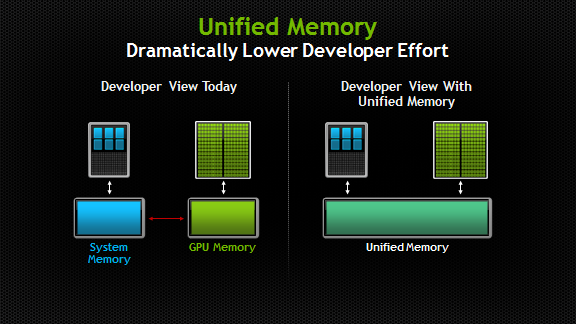
Unified Memory creates a pool of managed memory shared between the CPU and GPU, bridging the CPU-GPU divide. Managed memory is accessible to both the CPU and GPU using a single pointer. The key is that the system automatically migrates data allocated in Unified Memory between host and device so that it looks like CPU memory to code running on the CPU, and like GPU memory to code running on the GPU.
I wrote in detail about Unified Memory in the post Unified Memory in CUDA 6. Read the post for full details, or watch CUDACasts Episode 18: Unified Memory in CUDA 6.
CUDA on Tegra K1
Parallel computing on every NVIDIA GPU has been a goal since the first release of CUDA. CUDA 6 and the new Tegra K1 system on a chip (SoC) finally enable “CUDA Everywhere”, with CUDA capability top to bottom from the smallest mobile processor to the most powerful Tesla K40 accelerator.

Tegra K1 is NVIDIA’s latest mobile processor. It features a Kepler GPU with 192 cores, an NVIDIA 4-plus-1 quad-core ARM Cortex-A15 CPU, integrated video encoding and decoding support, image/signal processing, and many other system-level features. The Kepler GPU in Tegra K1 uses the same high-performance, energy-efficient Kepler GPU architecture that is found in our high-end GeForce, Quadro, and Tesla GPUs for graphics and computing. That makes it the only mobile processor today that supports CUDA 6 for computing and full desktop OpenGL 4.4 and DirectX 11 for graphics.
Introduced at GTC in March, Jetson TK1, is a tiny, full-featured computer designed for development of embedded and mobile applications. Jetson TK1 brings the capabilities of Tegra K1 to developers in a compact, low-power platform that makes development as simple as developing on a PC. For full details on Jetson TK1 and CUDA development on Tegra, see my post Jetson TK1: Mobile Embedded Supercomputer Takes CUDA Everywhere.
XT Libraries: Automatic Scaling to Multiple GPUs
CUDA 6 introduces XT Library interfaces which provide automatic scaling of cuBLAS level 3 and 2D/3D cuFFT routines to 2 or more GPUs. This means that if you have one or more dual-GPU accelerator cards in your workstation or cluster node, you can automatically take advantage of them for intensive FFTs and matrix-matrix multiplication. cuBLAS XT also enables multiplication of matrices that are too large to fit in the memory of a single GPU, because it operates directly on matrices allocated in CPU memory, tiling the matrix and overlapping computation with memory transfers. The result is linear scaling of very large GEMM operations to multiple GPUs, as the following figure shows.

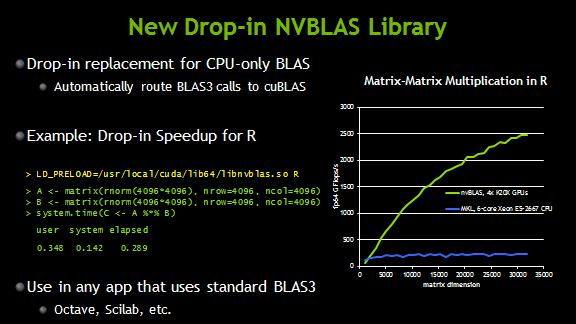
CUDA 6 introduces a new library called nvBLAS, which is a drop-in replacement for CPU-only BLAS libraries. nvBLAS automatically routes level-3 BLAS calls (e.g. DGEMM) to cuBLAS, and all other BLAS calls to the existing CPU-only BLAS library (e.g. Intel MKL). nvBLAS enables drop-in speed-up of existing applications. For example, you can use the LD_PRELOAD environment variable to preload nvBLAS and accelerate matrix-matrix multiplies in the R statistical computing package, as the following image shows.
Remote Development with NSight Eclipse Edition
A common use case for GPU developers is to develop HPC software that runs on a remote server or cluster, or on an embedded system such as Jetson TK1. The NSight Eclipse Edition Integrated Development Environment now supports a complete remote development workflow: edit source code in the IDE running on your local PC (e.g. a laptop), then build, run, debug, and profile the application remotely on a server with a CUDA-capable GPU. NSight takes care of syncing the source code to the remote machine, and you can use all the CUDA-aware debugging and profiling features of NSight in your local IDE. NSight also now supports cross-compilation to ARM for execution on a remote ARM-based system such as a Tegra K1.

Enhanced Profiling Features
The NVIDIA Visual Profiler and NSight Eclipse Edition profiler in CUDA 6 add a number of improvements to guided profiling. The profiler now collects detailed instruction mix statistics and can display a detailed breakdown of the instruction types executed by a kernel. This helps you see whether a kernel is spending time executing the type of code you expect.
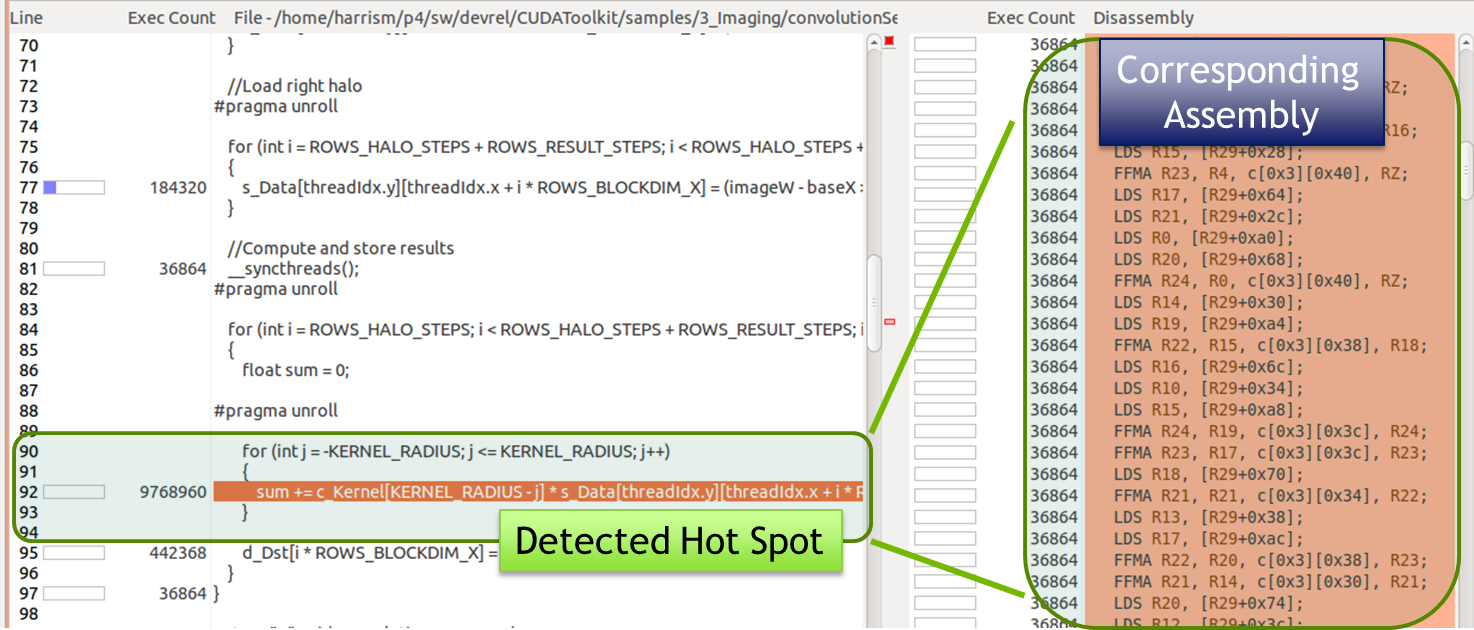
The profilers can also now count the number of times a kernel executes each instruction, and associate the instruction counts with specific lines of device code. This makes it possible to find the lines of code that execute the most instructions, which are likely to correspond to bottlenecks in your kernel. You can also see lines with execution divergence in this view. The profiler can also detect inefficient shared memory access patterns and their location in the code. CUDA 6 lets you not only detect performance problems using the profiler, but find the lines of code that cause them.
More New Features and Improvements
CUDA 6 includes much more than I can describe in one post, including many new features, improvements, and bug fixes in the CUDA APIs, libraries, and developer tools. For a complete overview of what’s new in CUDA 6, check out the Release Notes.
For more detail about Unified Memory and other CUDA 6 features, and a look at where CUDA will take you in the future, watch my talk “CUDA 6 and Beyond”, embedded above.