NVIDIA Nsight Eclipse Edition (NSEE) is a full-featured unified CPU+GPU integrated development environment(IDE) that lets you easily develop CUDA applications for either your local (x86_64) system or a remote (x86_64 or ARM) target system. In my last post on remote development of CUDA applications, I covered NSEE’s cross compilation mode. In this post I will focus on the using NSEE’s synchronized project mode.
For remote development of CUDA applications using synchronized-project mode, you can edit code on the host system and synchronize it with the target system. In this scenario, the code is compiled natively on the target system as Figure 1 shows.
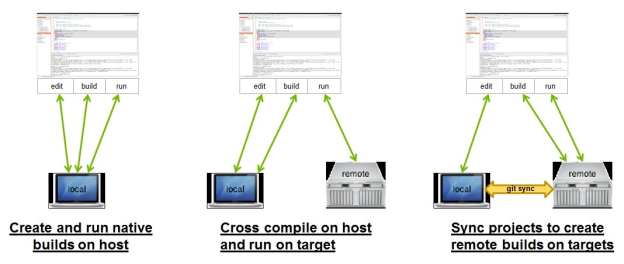
In synchronized project mode the host system does not need an ARM cross-compilation tool chain, so you have the flexibility to use Mac OS X or any of the CUDA supported x86_64 Linux platforms as the host system. The remote target system can be a CUDA-supported x86_64 Linux target or an ARM-based platform like the Jetson TK1 system. I am using Mac OS X 10.8.5 on my host system (with Xcode 5.1.1 installed) and 64-bit Ubuntu 12.04 on my target system.
CUDA Toolkit Setup
To install the CUDA toolkit on the Mac OS X host system, first please make sure you have “Xcode command line tools” installed on your system. Then download the latest 64-bit CUDA 6.5 package for Mac (I’m using cuda_6.5.14_mac_64.pkg ) and double-click to install the package.
On the 64-bit Ubuntu12.04 host system download the latest 64-bit CUDA 6.5 installer for your Linux distribution (I’m using cuda-repo-ubuntu1204_6.5-14_amd64.deb). After downloading, update the repo and install the CUDA6.5 toolkit as follows:
> sudo dpkg –i cuda-repo-ubuntu1204_6.5-14_amd64.deb > sudo apt-get update > sudo apt-get install cuda
To synchronize CUDA projects between host and target systems, you need to configure git on both the host and the target systems using these commands.
> git config –global user.name <your_name> > git config –global user.email <your_email>
That’s all for the setup. Please note that if you have a Jetson TK1 as your target system, the current Jetson TK1 OS image for L4T (Linux for Tegra) does not contain the latest CUDA 6.5 toolkit. This support will be available in a future release (Rel21.2), but in the meantime you can use the CUDA 6.0 toolkit archive. You can check the L4T version with the following command.
> head -1 /etc/nv_tegra_release.
Importing a CUDA Sample
Let’s launch Nsight Eclipse Edition on the Mac OS X host system. You can find Nsight in the Finder if the system has indexed it, You can also use the Finder to navigate to the /Developer/NVIDIA/CUDA-6.5/libnsight folder or open a Terminal Application window and launch ./nsight from the /usr/local/cuda/bin folder. Click on File->New->CUDA C/C++ Project to launch the project creation wizard. Enter project name “particles”, select “Import CUDA Sample”, as the project type and select “CUDA Toolkit 6.5” from the available tool chains.
Next, select the CUDA sample by applying “Simulations” as the samples filter type, which will populate a short list of available simulations samples. Select “Particles” and click next. The remaining options in the wizard let you choose which GPU and CPU architectures to generate code for. First, we will choose the GPU code that the nvcc compiler should generate. Nsight will default to the GPU architecture that it detects on the host system. On my Mac OS X system I have a Geforce GT 650M, so Nsight defaults PTX (virtual ISA) and GPU SASS code generation to SM3.0. My target Linux system also has a kepler GPU so SM3.0 is the correct architecture for Nsight to target. But if your target system has an older GPU, then check the SM1.1 or SM2.0 PTX check box to generate PTX code that the CUDA driver will JIT (just-in-time) compile to the architecture on the target system.
Next, enter your host architecture. Since my target is an x86_64 system, I can leave it as native or select “x86 (64-bit)” in the CPU architecture drop-down menu. Note if you have an ARM target you can also select ARM as the target CPU architecture. Click “Finish” and you should see the particles sample opened in Nsight and ready to use. Nsight will index all the headers when it opens the project for the first time, so let it complete this operation before creating a remote build on the target system.
Creating A Remote Synchronized-Project Build
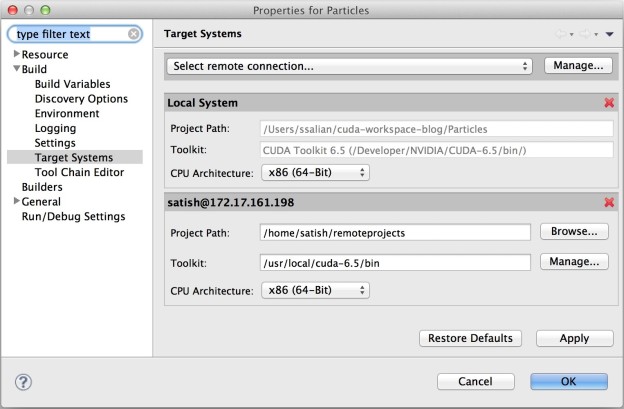
In the Nsight project explorer select “particles”, then click on “File->Properties” to bring up the project settings on the particles project. In the properties UI click on “Build->Target Systems” which shows the UI for selecting the remote connection settings. Click on “Manage…” and then click “Add” to enter the host IP address and user name of the target system. When you click “Finish” you will see the entry for the new target system that you just added. Next, click on “Browse…” to choose a project path on the target system and click on “Manage…” to choose the toolkit path from the target system. In the dialog that pops up you can click on “Detect” to let Nsight auto-detect the installed toolkit path for you. Choose the target CPU architecture “x86 (64-bit)” and click “Apply” so you can also update the libraries next. The remote target system setup should look like Figure 2.
Based on your remote target architecture and remote OS, a couple of library settings need to be adjusted. First select [All configurations] to update library settings for all build targets. For a 64-bit Linux target, in the project properties click on “Settings->ToolSettings->NVCC Linker->Miscellaneous”, delete GLUT and -framework from the -Xlinker option, and change the libGLEW.a path in “other objects” to point to the Linux 64b samples/common lib: /usr/local/cuda-6.5/samples/common/lib/linux/x86_64/libGLEW.a (see Figure 3) shows.
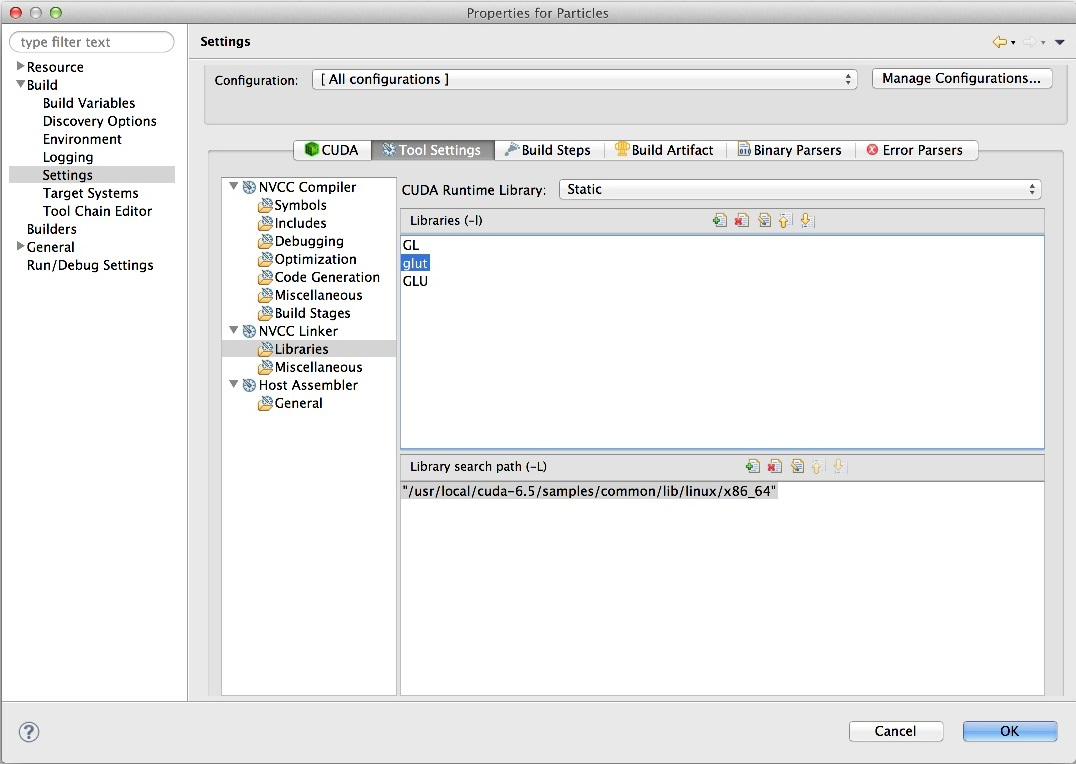
Next, click on “Settings->ToolSettings->NVCC Linker->Libraries”, add glut in the Libraries section and change the “Library search path” to the target Linux toolkit path: /usr/local/cuda-6.5/samples/lib/linux/x86_64 (see Figure 4).

That’s it for the target library path updates. Next click OK to save the project settings then click on the build “hammer” icon in the toolbar to drop down the build menu. You will see the target system entry there for debug and release builds. Choose debug build; this will create a native build on the Linux target system from Nsight running on your Mac OS X host system.
Running Your Remote Application
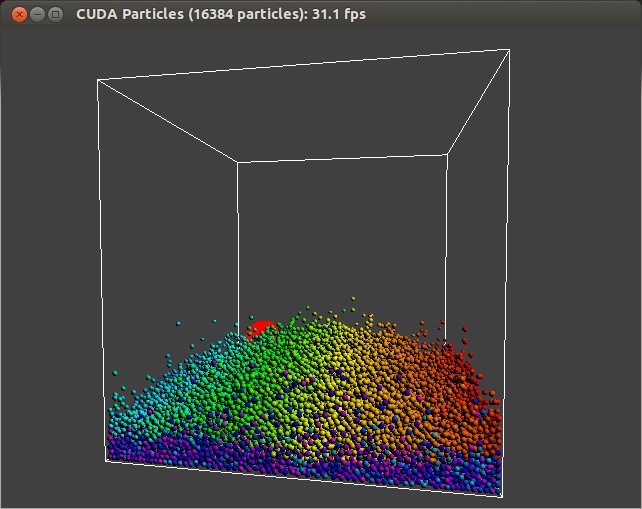
Since your target system settings are already in place with remote build creation, running your application remotely is straightforward. In the Nsight project explorer left pane, click on the top-level Particles project. Then click on the Run icon in the toolbar to pull down the Run menu and select “Run As->Remote C/C++ Application”. Enter the password for the remote system if Nsight prompts for one. Nsight will launch the remote binary that it created on the target system and you will see the Particles application running on the target system’s display, as in Figure 5.
Debugging Your Remote Application
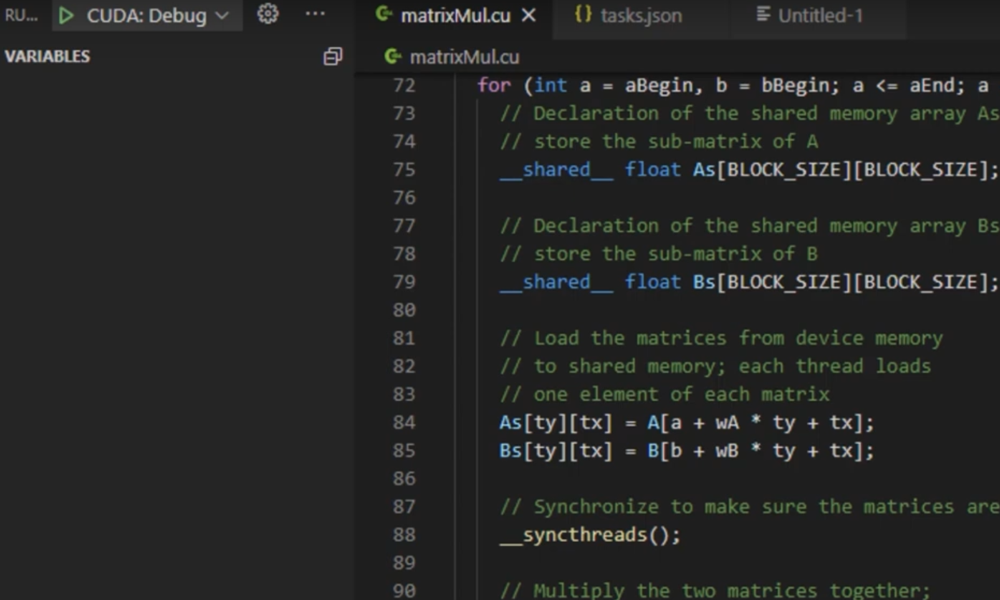
The particles CUDA sample uses the C++ Thrust library. To avoid hitting breakpoints in the Thrust library, let’s open the file particleSystem_cuda.cu file in the editor view and search for the collideD kernel. Press Function-F3 to open the kernel declaration in file particles_kernel_impl.cuh and double-click on line #308 to set your first breakpoint.
__global__
void collideD(float4 *newVel, // output: new velocity
float4 *oldPos, // input: sorted positions
float4 *oldVel, // input: sorted velocities
uint *gridParticleIndex, // input: sorted particle indices
uint *cellStart,
uint *cellEnd,
uint numParticles)
{
uint index = __mul24(blockIdx.x,blockDim.x) + threadIdx.x;
if (index >= numParticles) return;
// read particle data from sorted arrays
float3 pos = make_float3(FETCH(oldPos, index));
float3 vel = make_float3(FETCH(oldVel, index));
To debug the application, click on the “Debug” icon to the left of the “Run” icon to select “Debug As->Remote C/C++ Application”. When Nsight asks if it’s okay to switch to the “Debug Perspective”, select “Yes” and check the box to remember that choice. Because Nsight Eclipse Edition allows seamless debugging of both CPU and GPU code, it will stop at the first instruction executing on the CPU which is the first line in the main function of particles.cpp. You can single-step a bit there to see the execution on the CPU and watch the variables and registers as they get updated. In the breakpoint tab on the top right, you can see the breakpoint set at line #308 of particles_kernel_impl.cuh.
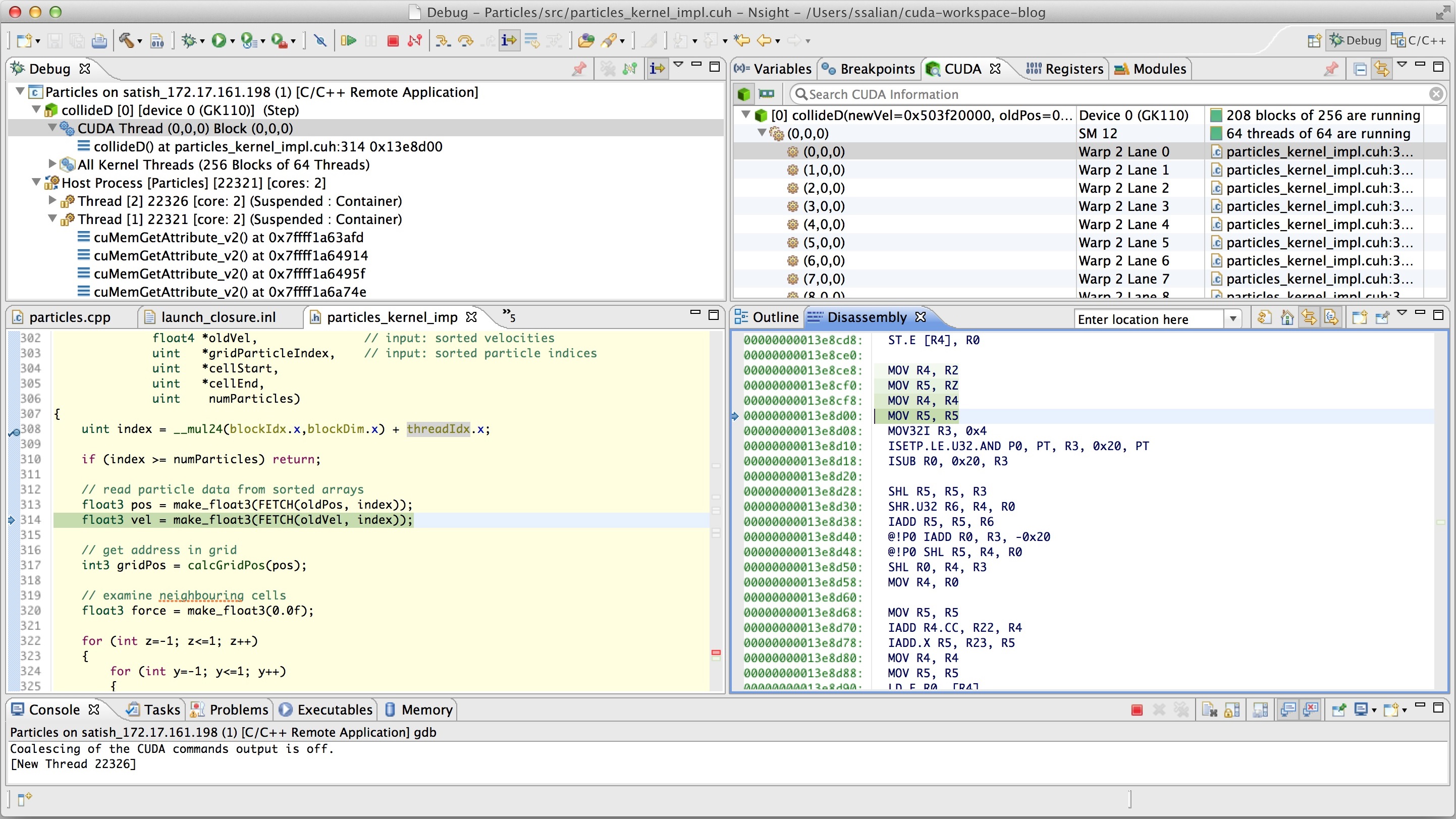
You can now resume the application, which will run until it hits the breakpoint we set in the collideD kernel. Once at the first breakpoint, you can browse the CPU and GPU call stack in the top-left pane. You can also view the variables, registers and hardware state in the top-right pane. You will see that the target GK110 GPU is executing 208 blocks of 256 total blocks occupying all the 13 SMs of the GK110 GPU.
You can also switch to disassembly view and watch the register values being updated by clicking on the “i->” icon to do GPU instruction-level single-stepping, as Figure 6 shows.
Please note that when debugging a remote application that uses OpenGL-CUDA interop like this one, do not use the remote desktop keyboard or mouse, because it will not be interactive unless you have multiple GPUs. If you have a GK110 (SM35) and higher GPU then interacting with a single GPU is possible by enabling software preëmption when Nsight prompts you to switch to the debugger perspective. When you finish exploring the debug view, click on the red icon to stop the debugging session. Next, click on the C/C++ perspective icon on the right-hand side of the toolbar to switch back to the editor mode.
Profiling Your Remote Application
We need to create a release build before we launch the profiler. You can enable the -lineinfo option in the compile options to generate information on source-to-SASS instruction correlation. To do this, first go to the project settings by right-clicking on the project in the left pane. Then navigate to Properties->Build->Settings->Tool Settings->Debugging and check the box that says “Generate line-number…” and click Apply. Back in the main window, click on the build hammer drop-down menu to create a release build. Once the build is ready, profile your remote application by clicking on the “Profile” icon on the right of the Run icon. In the drop-down menu select “Profile AS->Remote C/C++ Application”, Nsight will prompt you to select the binaries; choose the release binary so it runs on the target system.
Unlike the debugger runs (with GPU compute capability 3.5 and lower), during profiler runs you can use your keyboard or mouse to interact with the active desktop on the target system. So use the mouse to close the particles application on the target. Once the application terminates, within seconds Nsight on the host system will process all the gathered records from the run and display the timeline in the “Profiler Perspective” view as in Figure 7.

You can roll the mouse over the timeline to see all the properties of the API calls and the CUDA kernels in the property panel to the right. There are many kernels launched by this application, so we will continue to focus on the collideD kernel. In the lower pane you will see the Analysis tab buttons to “Examine GPU usage” and “Examine individual kernels”. Click on the latter, which will cause the application to run again. Close the application on the target system again and you will see all the performance critical kernels in the right pane ranked in the order of importance (see Figure 7). The higher the rank, the better bang for the buck you will get for tuning kernel performance.
Let’s select the collideD kernel and then click on the “unguided analysis” icon under the “Analysis” tab. Then scroll down to click on “Kernel Profile”, which will analyze the source code of the collideD kernel and map it to the executed instructions. Once the analysis finishes, the pane on the right shows the kernel name. Double click on collideD and Nsight will bring up the source-to-SASS assembly instructions view which shows all the hot spots at instruction level. The kernel profile, shown in , as shown in Figure 8, provides the execution count, inactive threads, and predicated threads for each source and assembly line of the kernel. Using this information you can pinpoint portions of your kernel that inefficiently use compute resources due to divergence or predication.

As you can see, using NVIDIA Nsight Eclipse Edition for remote development using “synchronized-project” mode is as simple as doing remote development using the “cross compilation” mode described in my earlier post. Download the recently announced CUDA 6.5 toolkit.
- Use cross compilation mode if you have an ARM target and want faster compilation on your x86 Ubuntu host system.
- Use the remote synchronized-project mode if you want to use other Linux distributions or Mac OS X as the host system.
Check out the CUDA documentation for more information on Getting Started Guides on CUDA toolkit Installation and Nsight, or read more about CUDA 6.5.