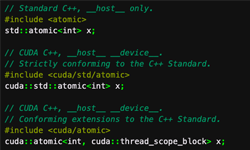
The last two releases of CUDA have added support for the powerful new features of C++. In the post The Power of C++11 in CUDA 7 I discussed the importance of C++11 for parallel programming on GPUs, and in the post New Features in CUDA 7.5 I introduced a new experimental feature in the NVCC CUDA C++ compiler: support for GPU Lambda expressions. Lambda expressions, introduced in C++11, provide concise syntax for anonymous functions (and closures) that can be defined in line with their use, can be passed as arguments, and can capture variables from surrounding scopes. GPU Lambdas bring that power and convenience to writing GPU functions, letting you launch parallel work on the GPU almost as easily as writing a for loop.
In this post, I want to show you how modern C++ features combine to enable a higher-level, more portable approach to parallel programming for GPUs. To do so, I’ll show you Hemi 2, the second release of a simple open-source C++ library that I developed to explore approaches to portable parallel C++ programming. I have written before about Hemi on Parallel Forall, but Hemi 2 is easier to use, more portable, and more powerful.
 Introducing Hemi 2
Introducing Hemi 2
Hemi simplifies writing portable CUDA C/C++ code. With Hemi,
- you can write parallel kernels like you write for loops—in line in your CPU code—and run them on your GPU;
- you can launch C++ Lambda functions as GPU kernels;
- you can easily write code that compiles and runs either on the CPU or GPU;
- kernel launch configuration is automatic: details like thread block size and grid size are optimization details, rather than requirements.
With Hemi, parallel code for the GPU can be as simple as the parallel_for loop in the following code, which can also be compiled and run on the CPU.
void saxpy(int n, float a, const float *x, float *y)
{
hemi::parallel_for(0, n, [=] HEMI_LAMBDA (int i) {
y[i] = a * x[i] + y[i];
});
}
Hemi is BSD-licensed, open-source software, available on Github.
GPU Lambdas and Parallel-For Programming
As I discussed in the post New Features in CUDA 7.5, GPU Lambdas let you define C++11 Lambda functions with a __device__ annotation which you can pass to and call from kernels running on the device. Hemi 2 leverages this feature to provide the hemi::parallel_for() function. When compiled for the GPU, parallel_for() launches a parallel kernel which executes the provided GPU lambda function as the body of a parallel loop. When compiled for the CPU, the lambda is executed as the body of a sequential CPU loop. This makes portable parallel functions nearly as easy to write as for loops, as in the following code.
parallel_for(0, 100, [] HEMI_LAMBDA (int i) {
printf("%d\n", i);
});
GPU Lambdas can also be launched directly on the GPU using hemi::launch():
launch([=] HEMI_LAMBDA () {
printf("Hello World from Lambda in thread %d of %d\n",
hemi::globalThreadIndex(),
hemi::globalThreadCount());
});
Portable Parallel Execution
You can use hemi::launch() to launch lambdas or function objects (functors) in a portable way. To define a functor that you can launch on the GPU, its class must define an operator() declared with the HEMI_DEV_CALLABLE_MEMBER annotation macro (see hemi/hemi.h). To make this easy, Hemi 2 provides macro HEMI_KERNEL_FUNCTION(). The simple example hello.cpp demonstrates its use:
// define a kernel functor
HEMI_KERNEL_FUNCTION(hello) {
printf("Hello World from thread %d of %d\n",
hemi::globalThreadIndex(),
hemi::globalThreadCount());
}
int main(void) {
hello hi; // instantiate the functor
hemi::launch(hi); // launch on the GPU
hemi::deviceSynchronize(); // make sure printf flushes before exit
hi(); // call on CPU
return 0;
}
As you can see, HEMI_KERNEL_FUNCTION() actually defines a function object which must be instantiated. Once instantiated, it can either be launched on the GPU or called from the CPU, so this is a way to define parallel functions with the capability of running on the CPU if there is no GPU present.
In fact, you can even compile the above code with a different compiler that knows nothing about CUDA. In this case, it will simply run sequentially on the CPU when passed to hemi::launch().
You can also define portable CUDA kernel functions using HEMI_LAUNCHABLE, which defines the function using CUDA __global__ when compiled using nvcc, or as a normal host function otherwise. Launch these functions in a portable way using hemi::cudaLaunch(). The example hello_global.cu demonstrates:
HEMI_LAUNCHABLE void hello() {
printf("Hello World from thread %d of %d\n",
hemi::globalThreadIndex(),
hemi::globalThreadCount());
}
int main(void) {
hemi::cudaLaunch(hello);
hemi::deviceSynchronize(); // make sure print flushes before exit
return 0;
}
Unlike HEMI_KERNEL_FUNCTION(), which can be either launched on the device or called on the host, calls to hemi::cudaLaunch() always target the device when compiled with nvcc targetting a GPU architecture. Note that you can also use hemi::cudaLaunch() on a traditionally defined CUDA __global__ kernel function (which is equivalent to HEMI_LAUNCHABLE). You may want to use hemi::cudaLaunch instead of CUDA’s <<< >>> triple-angle-bracket launch syntax because of its ability to automatically configure launches.
Automatic Execution Configuration
In both of the examples in the previous section, the execution configuration (the number of thread blocks and size of each block) is automatically decided by Hemi based on the GPU it is running on and the resources used by the kernel. In general, when compiled for the GPU, hemi::launch(), hemi::cudaLaunch() and hemi::parallel_for() will choose a grid configuration that occupies all multiprocessors (SMs) on the GPU. This makes it almost trivial to launch parallel work on the GPU! With Hemi, execution configuration is an optimization, rather than a requirement.
Automatic Execution Configuration is flexible, though. You can explicitly specify the entire execution configuration—grid size, thread block size, and dynamic shared memory allocation—or you can partially specify the execution configuration. For example, you might need to specify just the thread block size. Hemi makes it easy to take full control when you need it for performance tuning, but when you are getting started parallelizing your code, or for functions where ultimate performance is not crucial, you can just let Hemi configure the parallelism for you.
As an example, the nbody_vec4 example provides an optimized version of its main kernel that tiles data in CUDA shared memory. For this, it needs to specify the block size and shared memory allocation explicitly.
const int blockSize = 256; hemi::ExecutionPolicy ep; ep.setBlockSize(blockSize); ep.setSharedMemBytes(blockSize * sizeof(Vec4f)); hemi::cudaLaunch(ep, allPairsForcesShared, forceVectors, bodies, N);
However, note that the number of blocks in the grid is left to Hemi to choose at run time.
Simple Grid-Stride Loops
A common design pattern in writing scalable, portable parallel CUDA kernels is to use grid-stride loops. Grid-stride loops let you decouple the size of your CUDA grid from the data size it is processing, resulting in greater modularity between your host and device code. This has reusability, portability, and debugging benefits.
Hemi 2 includes a grid-stride range helper, hemi::grid_stride_range(), which makes it trivial to use C++11 range-based for loops to iterate in parallel. grid_stride_range() can be used in traditional CUDA kernels, such as the following saxpy kernel, or it can be combined with other Hemi portability features (in fact it is used in the implementation of hemi::parallel_for()).
__global__
void saxpy(int n, float a, float *x, float *y)
{
for (auto i : grid_stride_range(0, n)) {
y[i] = a * x[i] + y[i];
}
}
Note that hemi::grid_stride_range() can be compiled and used with range-based for loops on either the device or host. On the host, it uses a stride of 1.
Portable Functions
A common use for host-device code sharing is commonly used utility functions. For example, if we wish to define an inline function to compute the average of two floats that can be called either from host code or device code, and can be compiled by either the host compiler or NVCC, we define it like this:
HEMI_DEV_CALLABLE_INLINE float avgf(float x, float y) {
return (x+y)/2.0f;
}
The macro definition ensures that when compiled by NVCC, both a host and device version of the function are generated, and a normal inline function is generated when compiled by the host compiler.
For example use, see the CND() function in the “blackscholes” example, as well as several other functions used in the examples.
Portable Classes
The HEMI_DEV_CALLABLE_MEMBER and HEMI_DEV_CALLABLE_INLINE_MEMBER macros can be used to create classes that are reusable between host and device code, by decorating any member function that will be used by both device and host code. Here is an example excerpt of a portable class (a 4D vector type used in the “nbody_vec4” example).
struct HEMI_ALIGN(16) Vec4f
{
float x, y, z, w;
HEMI_DEV_CALLABLE_INLINE_MEMBER
Vec4f() {};
HEMI_DEV_CALLABLE_INLINE_MEMBER
Vec4f(float xx, float yy, float zz, float ww) : x(xx), y(yy), z(zz), w(ww) {}
HEMI_DEV_CALLABLE_INLINE_MEMBER
Vec4f(const Vec4f& v) : x(v.x), y(v.y), z(v.z), w(v.w) {}
HEMI_DEV_CALLABLE_INLINE_MEMBER
Vec4f& operator=(const Vec4f& v) {
x = v.x; y = v.y; z = v.z; w = v.w;
return *this;
}
HEMI_DEV_CALLABLE_INLINE_MEMBER
Vec4f operator+(const Vec4f& v) const {
return Vec4f(x+v.x, y+v.y, z+v.z, w+v.w);
}
...
};
The HEMI_ALIGN macro is used on types that will be passed in arrays or pointers as arguments to CUDA device kernel functions, to ensure proper alignment. HEMI_ALIGN generates correct alignment specifiers for the host compilers, too. For details on alignment, see the NVIDIA CUDA C Programming Guide Section 5.3.
Portable Device Code
The code used in Hemi portable functions (those defined with the macros discussed previously) must be portable, or the functions won’t compile for multiple architectures. In situations where you must use GPU-specific (or CPU-specific) code, you can use HEMI_DEV_CODE macro to define separate code for host and device. Example:
HEMI_DEV_CALLABLE_INLINE_MEMBER
float inverseLength(float softening = 0.0f) const {
#ifdef HEMI_DEV_CODE
return rsqrtf(lengthSqr() + softening); // use fast GPU intrinsic
#else
return 1.0f / sqrtf(lengthSqr() + softening);
#endif
}
Portable Iteration
For most situations where you need to portably iterate over a range in your device or kernel functions, I recommend using the hemi::grid_stride_range() with a range-based for loop, as previously discussed. Hemi also provides portable helper functions for situations where you need to customize iteration or array indexing based on thread or block index.
For kernel functions with simple independent element-wise parallelism, hemi/device_api.h includes functions to enable iterating over elements sequentially in host code or in parallel in device code.
globalThreadIndex()returns the offset of the current thread within the 1D grid, or 0 for host code. In device code, it resolves toblockDim.x * blockIdx.x + threadIdx.x.globalThreadCount()returns the size of the 1D grid in threads, or 1 in host code. In device code, it resolves togridDim.x * blockDim.x.
Here’s a SAXPY implementation using the above functions.
HEMI_LAUNCHABLE
void saxpy(int n, float a, float *x, float *y)
{
using namespace hemi;
for (auto i = globalThreadIndex(); i < n; i += globalThreadCount()) {
y[i] = a * x[i] + y[i];
}
}
Hemi provides a complete set of portable element accessors in hemi\device_api.h including localThreadIndex(), globalBlockCount(), etc. hemi\device_api.h also provides the synchronize() function which maps to __syncthreads() barrier operation when compiled for the device, and (currently) a no-op when compiled for the host.
Mix and Match
HEMI is intended to provide a loosely-coupled set of utilities and examples for creating reusable, portable CUDA C/C++ code. Feel free to use the parts that you need and ignore others. You may modify and replace portions as needed. We have selected a permissive open source license (BSD) to encourage these kinds of flexible use.
Requirements
Hemi 2 requires a host compiler with support for C++11 or later. Hemi builds on a number of C++11 features, including lambda expressions, variadic templates, and range-based for loops.
For CUDA device execution, Hemi 2 requires CUDA 7.0 or later. To launch lambda expressions on the GPU using hemi::launch() or hemi::parallel_for(), Hemi requires CUDA 7.5 or later with experimental support for “extended lambdas” (enabled using the nvcc command line option --expt-extended-lambda).
Parallel-For GPU Programming in Other Frameworks
Hemi is not alone in taking advantage of modern C++ to enable easier, more portable parallel programming. In fact, the following sophisticated frameworks address many of same challenges as Hemi, and much more.
![]() Thrust, the parallel algorithms template library included with the NVIDIA CUDA Toolkit, is also compatible with CUDA 7.5 GPU lambdas. You can combine GPU lambdas with Thrust algorithms like
Thrust, the parallel algorithms template library included with the NVIDIA CUDA Toolkit, is also compatible with CUDA 7.5 GPU lambdas. You can combine GPU lambdas with Thrust algorithms like thrust::for_each() and thrust::_transform() in the same way that you can combine STL algorithms with normal C++ lambdas. Here is an example of SAXPY implemented with Thrust and a portable GPU lambda.
void saxpy(float *x, float *y, float a, int N) {
using namespace thrust;
auto r = counting_iterator(0);
for_each(device, r, r+N, [=] HEMI_LAMBDA (int i) {
y[i] = a * x[i] + y[i];
});
}
Kokkos![]() , developed at Sandia National Laboratory, “implements a programming model in C++ for writing performance portable applications targeting all major HPC platforms”. Kokkos provides abstractions for both parallel execution of code and, importantly, data management, with support for nodes with multi-level memory hierarchies. Kokkos has backends for CUDA, OpenMP, and Pthreads execution. GPU lambdas are a key enabler for the Kokkos CUDA implementation. Here is an example of a parallel loop in Kokkos:
, developed at Sandia National Laboratory, “implements a programming model in C++ for writing performance portable applications targeting all major HPC platforms”. Kokkos provides abstractions for both parallel execution of code and, importantly, data management, with support for nodes with multi-level memory hierarchies. Kokkos has backends for CUDA, OpenMP, and Pthreads execution. GPU lambdas are a key enabler for the Kokkos CUDA implementation. Here is an example of a parallel loop in Kokkos:
Kokkos::parallel_for(N, KOKKOS_LAMBDA (int i) {
y[i] = a * x[i] + y[i];
});
Check out the GTC 2015 talk about Kokkos.
RAJA![]() is a software abstraction developed at Lawrence Livermore National Laboratory that “systematically encapsulates platform-specific code to enable applications to be portable across diverse hardware architectures without major source code disruption.” Here is an example of a CUDA-executable parallel loop in RAJA:
is a software abstraction developed at Lawrence Livermore National Laboratory that “systematically encapsulates platform-specific code to enable applications to be portable across diverse hardware architectures without major source code disruption.” Here is an example of a CUDA-executable parallel loop in RAJA:
RAJA::forall<cuda_exec>(0, N, [=] __device__ (int i) {
y[i] = a * x[i] + y[i];
});
Co-design discussions arising from NVIDIA’s work in the FastForward program, funded by the U.S. Department of Energy, helped motivate the design and deployment of the lambda support included in CUDA C++.
Try CUDA 7.5 and Portable Parallel Programming Today!
To get started with modern, portable C++ on GPUs, download the latest CUDA Toolkit today. To get started writing portable code with Hemi, download Hemi release 2.0 from Github.
To learn all about the new features in CUDA 7.5, sign up for the webinar “CUDA Toolkit 7.5 Features Webinar” and put it on your calendar for Tuesday, September 22.