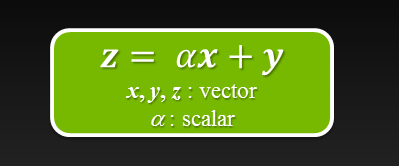
For even more ways to SAXPY using the latest NVIDIA HPC SDK with standard language parallelism, see N Ways to SAXPY: Demonstrating the Breadth of GPU Programming Options.
This post is a GPU program chrestomathy. What’s a Chrestomathy, you ask?
In computer programming, a program chrestomathy is a collection of similar programs written in various programming languages, for the purpose of demonstrating differences in syntax, semantics and idioms for each language. [Wikipedia]

There are several good examples of program chrestomathies on the web, including Rosetta Code and NBabel, which demonstrates gravitational N-body simulation in multiple programming languages. In this post I demonstrate six ways to implement a simple SAXPY computation on the CUDA platform. Why is this interesting? Because it demonstrates the breadth of options you have today for programming NVIDIA GPUs, and it covers the three main approaches to GPU computing: GPU-accelerated libraries, GPU compiler directives, and GPU programming languages.
SAXPY stands for “Single-Precision A·X Plus Y”. It is a function in the standard Basic Linear Algebra Subroutines (BLAS)library. SAXPY is a combination of scalar multiplication and vector addition, and it’s very simple: it takes as input two vectors of 32-bit floats X and Y with N elements each, and a scalar value A. It multiplies each element X[i] by A and adds the result to Y[i]. A simple C implementation looks like this.
void saxpy(int n, float a, float * restrict x, float * restrict y)
{
for (int i = 0; i < n; ++i)
y[i] = a*x[i] + y[i];
}
// Perform SAXPY on 1M elements
saxpy(1<<20, 2.0, x, y);
Given this basic example code, I can now show you six ways to SAXPY on GPUs. Note that I chose SAXPY because it is a really short and simple code, but it shows enough of the syntax of each programming approach to compare them. Because it’s so simple, and does very little computation, SAXPY is not really a great computation to use for comparing the performance of the different approaches, but that’s not my intent. My goal is to demonstrate multiple ways to program on the CUDA platform today, not to suggest that any one is better than any other.
1. CUBLAS SAXPY
int N = 1<<20; cublasInit(); cublasSetVector(N, sizeof(x[0]), x, 1, d_x, 1); cublasSetVector(N, sizeof(y[0]), y, 1, d_y, 1); // Perform SAXPY on 1M elements cublasSaxpy(N, 2.0, d_x, 1, d_y, 1); cublasGetVector(N, sizeof(y[0]), d_y, 1, y, 1); cublasShutdown();
As I mentioned, SAXPY is part of the BLAS library, and therefore a GPU SAXPY is available as part of the CUBLAS library. To use it, you just need to initialize CUBLAS (device) vectors for x and y and call cublasSaxpy(). Like all CUBLAS functions, cublasSaxpy conforms to the BLAS standard, and so it is a drop-in replacement for BLAS libraries for CPUs.
Libraries are one of the most efficient ways to program GPUs, because they encapsulate the complexity of writing optimized code for common algorithms into high-level, standard interfaces. There is a wide variety of high-performance libraries available for NVIDIA GPUs.
2. OpenACC SAXPY
If you have been following Parallel Forall, you are already familiar with OpenACC. OpenACC is an open standard that defines compiler directives for parallel computing on GPUs (see my previous posts on the subject). We can add a single line to the above example to produce an OpenACC SAXPY in C.
void saxpy(int n, float a, float * restrict x, float * restrict y)
{
#pragma acc kernels
for (int i = 0; i < n; ++i)
y[i] = a*x[i] + y[i];
}
...
// Perform SAXPY on 1M elements
saxpy(1<<20, 2.0, x, y);
A Fortran OpenACC SAXPY is very similar.
subroutine saxpy(n, a, x, y)
real :: x(:), y(:), a
integer :: n, i
!$acc kernels
do i=1,n
y(i) = a*x(i)+y(i)
enddo
$!acc end kernels
end subroutine saxpy
...
! Perform SAXPY on 1M elements
call saxpy(2**20, 2.0, x_d, y_d)
3. CUDA C++ SAXPY
__global__
void saxpy(int n, float a, float * restrict x, float * restrict y)
{
int i = blockIdx.x*blockDim.x + threadIdx.x;
if (i < n) y[i] = a*x[i] + y[i];
}
...
int N = 1<<20;
cudaMemcpy(d_x, x, N, cudaMemcpyHostToDevice);
cudaMemcpy(d_y, y, N, cudaMemcpyHostToDevice);
// Perform SAXPY on 1M elements
saxpy<<<4096,256>>>(N, 2.0, d_x, d_y);
cudaMemcpy(y, d_y, N, cudaMemcpyDeviceToHost);
CUDA C++ was the first general-purpose programming language on the CUDA platform. It provides a few simple extensions to the C language to express parallel computations. GPU functions, called kernels are declared with the__global__ specifier to indicate that they are callable from the host and run on the GPU. Kernels are run by many threads in parallel. Threads can compute their global index within an array of thread blocks by accessing the built-in variables blockIdx, blockDim, and threadIdx, which are assigned by the hardware for each thread and block. To launch a kernel, we specify the number of thread blocks and the number of threads in each thread block as arguments to the kernel function call inside <<<>>>, which we call the execution configuration. We copy data to and from GPU device memory using cudaMemcpy().
That is CUDA C in a nutshell. As you can see, the SAXPY kernel contains the same computation as the sequential C version, but instead of looping over the N elements, we launch a single thread for each of the N elements, and each thread computes its array index using blockIdx.x*blockDim.x + threadIdx.x.
4. Thrust SAXPY
using thrust::placeholders; int N = 1<<20; thrust::host_vector x(N), y(N); ... thrust::device_vector d_x = x; // alloc and copy host to device thrust::device_vector d_y = y; // Perform SAXPY on 1M elements thrust::transform(d_x.begin(), d_x.end(), d_y.begin(), d_y.begin(), 2.0f * _1 + _2); y = d_y; // copy results to the host vector
I wrote about Thrust in some detail in a recent post, so I will just point out a few interesting features of thrust demonstrated here. This code shows that copying a host vector to a device vector is as simple as assignment. It performes SAXPY in a single line using thrust::transform(), which acts like a parallel foreach (∥∀!), applying a multiply-add (MAD) operation to each element of the input vectors x and y. The MAD operation uses Thrust’s “placeholder” syntax (inspired by Boost placeholders), which uses the placeholder templates _1 and _2 to access the elements of the x and y input vectors, respectively.
5. CUDA Fortran SAXPY
module mymodule contains
attributes(global) subroutine saxpy(n, a, x, y)
real :: x(:), y(:), a
integer :: n, i
attributes(value) :: a, n
i = threadIdx%x+(blockIdx%x-1)*blockDim%x
if (i<=n) y(i) = a*x(i)+y(i)
end subroutine saxpy
end module mymodule
program main
use cudafor; use mymodule
real, device :: x_d(2**20), y_d(2**20)
x_d = 1.0, y_d = 2.0
! Perform SAXPY on 1M elements
call saxpy<<<4096, 256>>>(2**20, 2.0, x_d, y_d)
end program main
PGI CUDA Fortran provides parallel extensions to Fortran that are very similar to the parallel extensions to C provided by CUDA C. Here you can see how the saxpy subroutine computes an index i for each thread using the built-inthreadIdx, blockIdx, and blockDim variables, and is called using an execution configuration just like in the C version.
6. Python (Copperhead) SAXPY
from copperhead import * import numpy as np @cu def saxpy(a, x, y): return [a * xi + yi for xi, yi in zip(x, y)] x = np.arange(2**20, dtype=np.float32) y = np.arange(2**20, dtype=np.float32) with places.gpu0: gpu_result = saxpy(2.0, x, y) with places.openmp: cpu_result = saxpy(2.0, x, y)
Python is an extremely popular high-productivity programming language. Combined with popular modules Numpy andSciPy, Python is very popular in the scientific computing community. There have been a couple of projects to add GPU support to Python. The SAXPY example above is right off the home page of Copperhead, which is an open-source project from NVIDIA Research. Copperhead defines a small functional, data parallel subset of Python which it dynamically compiles and executes on parallel platforms, such as NVIDIA GPUs and multicore CPUs through OpenMP and Threading Building Blocks (TBB).
Enabling Endless Ways to SAXPY
So now, not only can you use “chrestomathy” in a sentence, but you know six different ways you can program GPUs on the CUDA platform. People often ask me “what’s the best way to program GPUs?”, and I hope that this SAXPY program chrestomathy makes it clear that there is no correct answer to that question. It’s just like asking “what’s the best way to program a computer?” There are hundreds of CPU programming languages, and there’s no reason that can’t and won’t be true for GPUs.
NVIDIA’s CUDA Compiler (NVCC) is based on the widely used LLVM open source compiler infrastructure (and recently, NVIDIA announced that it has contributed components to the popular open-source LLVM compiler infrastructure project). LLVM is used in a wide variety of compilers for general-purpose languages, as well as domain-specific languages (DSLs), which are languages targeted at solving problems in a specific domain.
Many GPU users want to target the CUDA platform with a general-purpose language they are already using. For this purpose, NVIDIA has released the CUDA Compiler SDK, which can be used to create or extend programming languages with support for GPU acceleration. The CUDA Compiler SDK is now included with the CUDA Toolkit. We hope that providing developers with access to an open compiler tool chain will help enable endless ways to program GPUs, so try out the CUDA Compiler SDK today!