Mar 06, 2024
How to Accelerate Quantitative Finance with ISO C++ Standard Parallelism
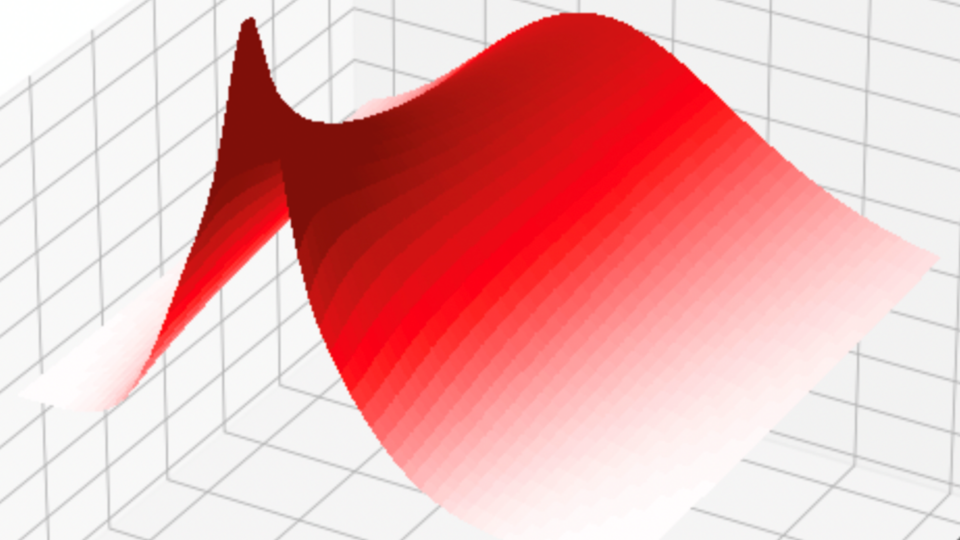
Quantitative finance libraries are software packages that consist of mathematical, statistical, and, more recently, machine learning models designed for use in...
10 MIN READ