Dec 08, 2020
Fast, Flexible Allocation for NVIDIA CUDA with RAPIDS Memory Manager
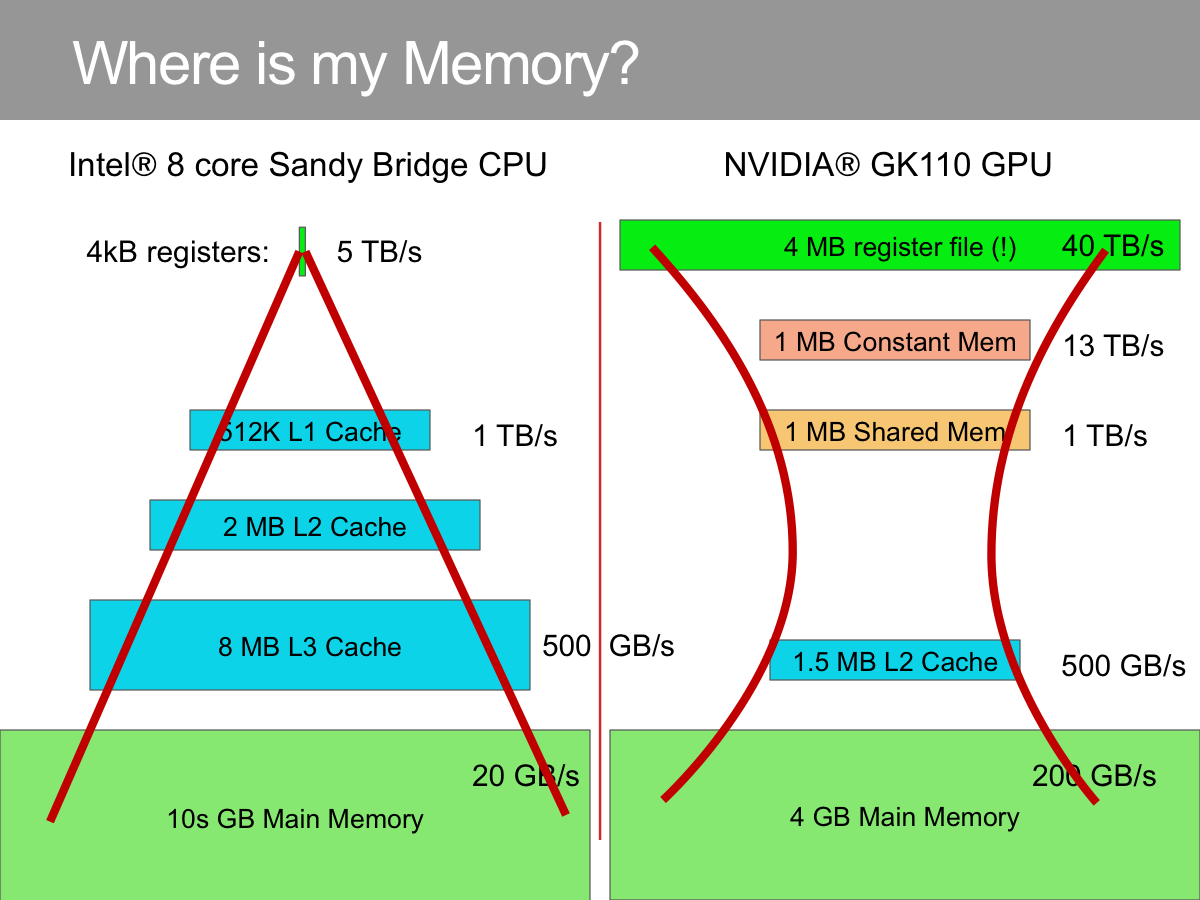
When I joined the RAPIDS team in 2018, NVIDIA CUDA device memory allocation was a performance problem. RAPIDS cuDF allocates and deallocates memory at high...
24 MIN READ