Feb 25, 2021
Developing AI-Powered Digital Health Applications Using NVIDIA Jetson
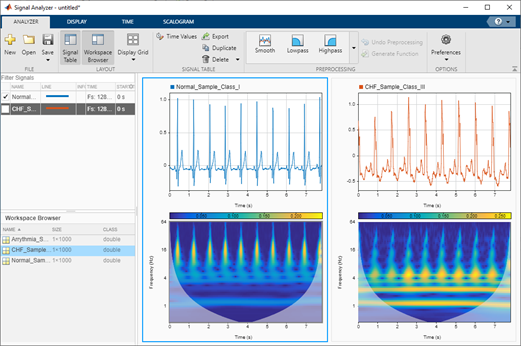
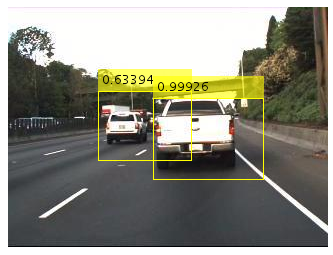
Traditional healthcare systems have large amounts of patient data in the form of physiological signals, medical records, provider notes, and comments. The...
17 MIN READ