Since its introduction more than 7 years ago, the CUDA Unified Memory programming model has kept gaining popularity among developers. Unified Memory provides a...
Analyzing the RNA-Sequence of 1.3M Mouse Brain Cells with RAPIDS on NVIDIA GPUs
Single-cell genomics research continues to advance drug discovery for disease prevention. For example, it has been pivotal in developing treatments for the...
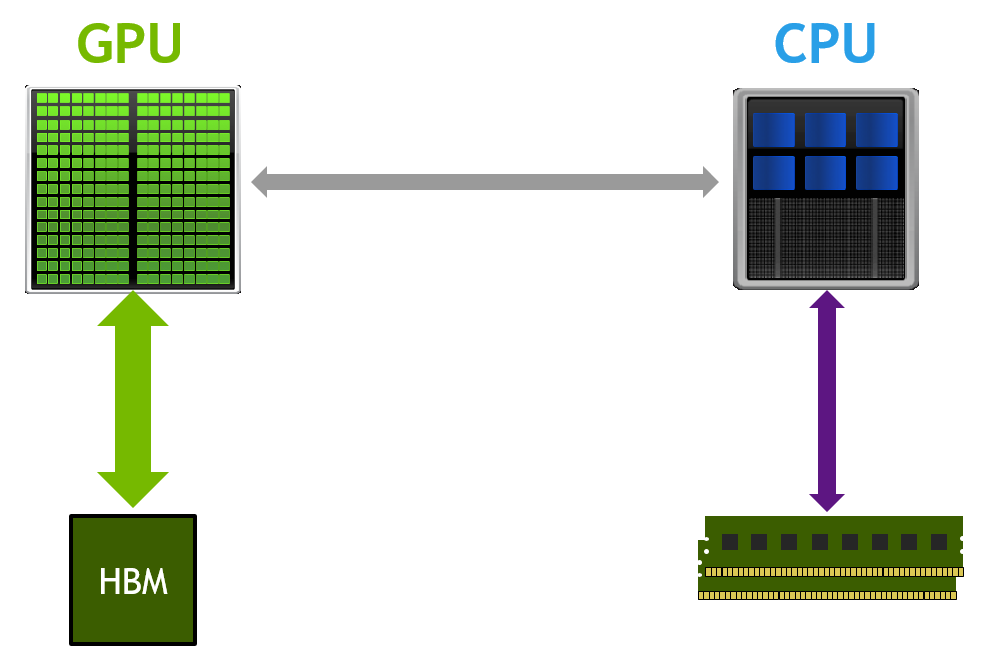
Many of today's applications process large volumes of data. While GPU architectures have very fast HBM or GDDR memory, they have limited capacity. Making the...
My previous introductory post, "An Even Easier Introduction to CUDA C++", introduced the basics of CUDA programming by showing how to write a simple program...
At the 2016 GPU Technology Conference in San Jose, NVIDIA CEO Jen-Hsun Huang announced the new NVIDIA Tesla P100, the most advanced accelerator ever built....
Today I'm excited to announce the general availability of CUDA 8, the latest update to NVIDIA's powerful parallel computing platform and programming model. In...
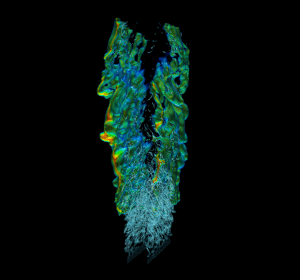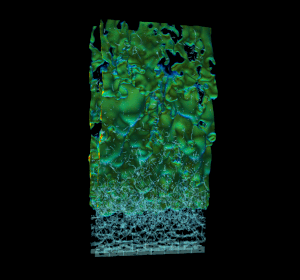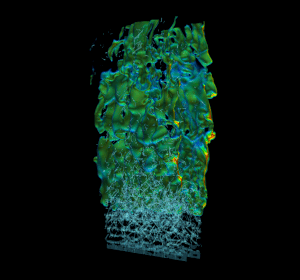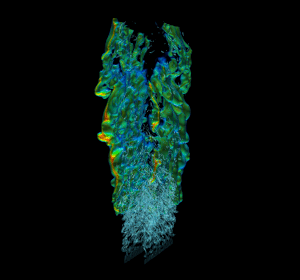
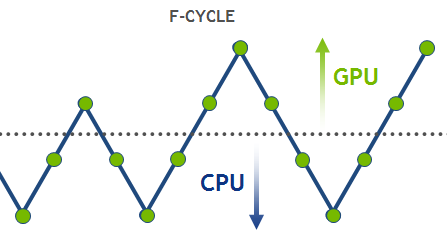
High-Performance Geometric Multi-Grid with GPU Acceleration
Linear solvers are probably the most common tool in scientific computing applications. There are two basic classes of methods that can be used to solve an...
Combine OpenACC and Unified Memory for Productivity and Performance
The post Getting Started with OpenACC covered four steps to progressively accelerate your code with OpenACC. It's often necessary to use OpenACC directives to...
How NVLink Will Enable Faster, Easier Multi-GPU Computing
Accelerated systems have become the new standard for high performance computing (HPC) as GPUs continue to raise the bar for both performance and energy...
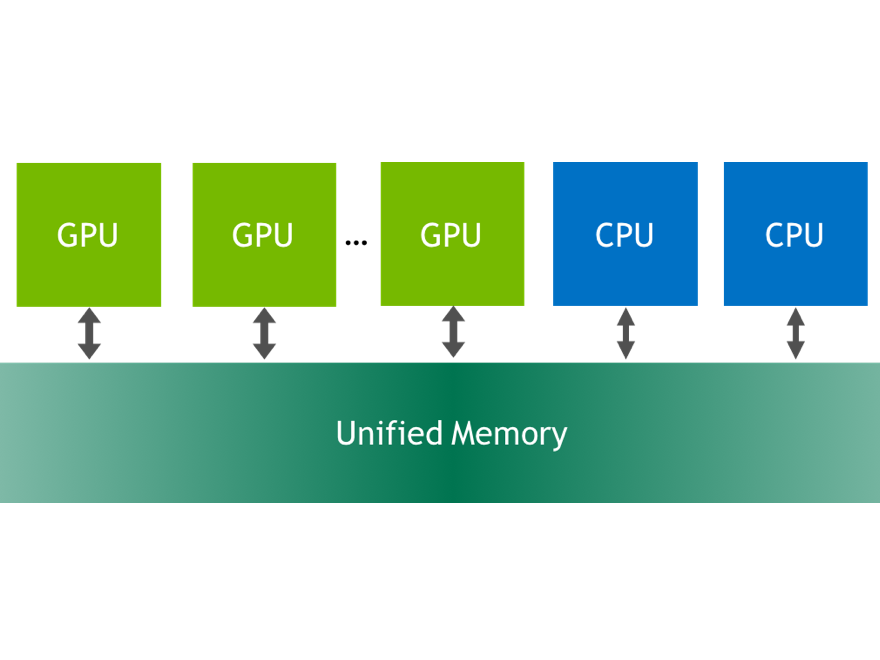
Unified Memory is a CUDA feature that we've talked a lot about on Parallel Forall. CUDA 6 introduced Unified Memory, which dramatically simplifies GPU...
NVLink, Pascal and Stacked Memory: Feeding the Appetite for Big Data
For more recent info on NVLink, check out the post, "How NVLink Will Enable Faster, Easier Multi-GPU Computing". NVIDIA GPU accelerators have emerged in...
CUDA 6 introduces Unified Memory, which dramatically simplifies memory management for GPU computing. Now you can focus on writing parallel kernels when porting...
CUDA Pro Tip: Control GPU Visibility with CUDA_VISIBLE_DEVICES
As a CUDA developer, you will often need to control which devices your application uses. In a short-but-sweet post on the Acceleware blog, Chris Mason writes:...
With CUDA 6, NVIDIA introduced one of the most dramatic programming model improvements in the history of the CUDA platform, Unified Memory. In a typical PC or...