In part II of this series, we looked at hierarchical tree traversal as a means of quickly identifying pairs of potentially colliding 3D objects and we demonstrated how optimizing for low divergence can result in substantial performance gains on massively parallel processors. Having a fast traversal algorithm is not very useful, though, unless we also have a tree to go with it. In this part, we will close the circle by looking at tree building; specifically, parallel bounding volume hierarchy (BVH) construction. We will also see an example of an algorithmic optimization that would be completely pointless on a single-core processor, but leads to substantial gains in a parallel setting.
There are many use cases for BVHs, and also many ways of constructing them. In our case, construction speed is of the essence. In a physics simulation, objects keep moving from one time step to the next, so we will need a different BVH for each step. Furthermore, we know that we are going to spend only about 0.25 milliseconds in traversing the BVH, so it makes little sense to spend much more on constructing it. One well-known approach for handling dynamic scenes is to essentially recycle the same BVH over and over. The basic idea is to only recalculate the bounding boxes of the nodes according to the new object locations while keeping the hierarchical structure of nodes the same. It is also possible to make small incremental modifications to improve the node structure around objects that have moved the most. However, the main problem plaguing these algorithms is that the tree can deteriorate in unpredictable ways over time, which can result in arbitrarily bad traversal performance in the worst case. To ensure predictable worst-case behavior, we instead choose to build a new tree from scratch every time step. Let’s look at how.
Exploiting the Z-Order Curve
The most promising current parallel BVH construction approach is to use a so-called linear BVH (LBVH). The idea is to simplify the problem by first choosing the order in which the leaf nodes (each corresponding to one object) appear in the tree, and then generating the internal nodes in a way that respects this order. We generally want objects that located close to each other in 3D space to also reside nearby in the hierarchy, so a reasonable choice is to sort them along a space-filling curve. We will use the Z-order curve for simplicity. 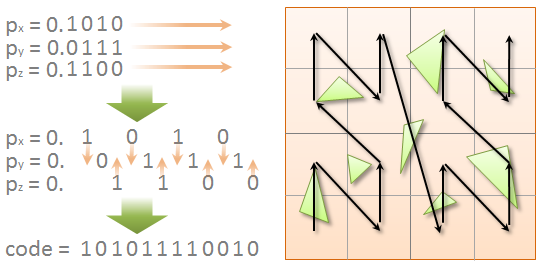 The Z-order curve is defined in terms of Morton codes. To calculate a Morton code for the given 3D point, we start by looking at the binary fixed-point representation of its coordinates, as shown in the top left part of the figure. First, we take the fractional part of each coordinate and expand it by inserting two “gaps” after each bit. Second, we interleave the bits of all three coordinates together to form a single binary number. If we step through the Morton codes obtained this way in increasing order, we are effectively stepping along the Z-order curve in 3D (a 2D representation is shown on the right-hand side of the figure). In practice, we can determine the order of the leaf nodes by assigning a Morton code for each object and then sorting the objects accordingly. As mentioned in the context of sort and sweep in part I, parallel radix sort is just the right tool for this job. A good way to assign the Morton code for a given object is to use the centroid point of its bounding box, and express it relative to the bounding box of the scene. The expansion and interleaving of bits can then be performed efficiently by exploiting the arcane bit-swizzling properties of integer multiplication, as shown in the following code.
The Z-order curve is defined in terms of Morton codes. To calculate a Morton code for the given 3D point, we start by looking at the binary fixed-point representation of its coordinates, as shown in the top left part of the figure. First, we take the fractional part of each coordinate and expand it by inserting two “gaps” after each bit. Second, we interleave the bits of all three coordinates together to form a single binary number. If we step through the Morton codes obtained this way in increasing order, we are effectively stepping along the Z-order curve in 3D (a 2D representation is shown on the right-hand side of the figure). In practice, we can determine the order of the leaf nodes by assigning a Morton code for each object and then sorting the objects accordingly. As mentioned in the context of sort and sweep in part I, parallel radix sort is just the right tool for this job. A good way to assign the Morton code for a given object is to use the centroid point of its bounding box, and express it relative to the bounding box of the scene. The expansion and interleaving of bits can then be performed efficiently by exploiting the arcane bit-swizzling properties of integer multiplication, as shown in the following code.
// Expands a 10-bit integer into 30 bits
// by inserting 2 zeros after each bit.
unsigned int expandBits(unsigned int v)
{
v = (v * 0x00010001u) & 0xFF0000FFu;
v = (v * 0x00000101u) & 0x0F00F00Fu;
v = (v * 0x00000011u) & 0xC30C30C3u;
v = (v * 0x00000005u) & 0x49249249u;
return v;
}
// Calculates a 30-bit Morton code for the
// given 3D point located within the unit cube [0,1].
unsigned int morton3D(float x, float y, float z)
{
x = min(max(x * 1024.0f, 0.0f), 1023.0f);
y = min(max(y * 1024.0f, 0.0f), 1023.0f);
z = min(max(z * 1024.0f, 0.0f), 1023.0f);
unsigned int xx = expandBits((unsigned int)x);
unsigned int yy = expandBits((unsigned int)y);
unsigned int zz = expandBits((unsigned int)z);
return xx * 4 + yy * 2 + zz;
}
In our example dataset with 12,486 objects, assigning the Morton codes this way takes 0.02 milliseconds on GeForce GTX 690, whereas sorting the objects takes 0.18 ms. So far so good, but we still have a tree to build.
Top-Down Hierarchy Generation
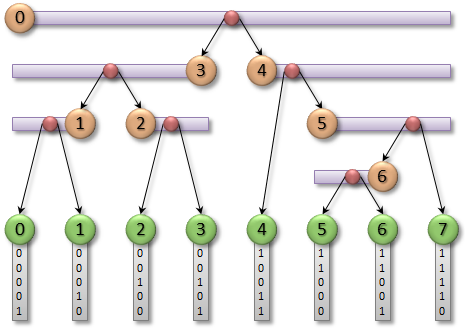
One of the great things about LBVH is that once we have fixed the order of the leaf nodes, we can think of each internal node as just a linear range over them. To illustrate this, suppose that we have N leaf nodes in total. The root node contains all of them, i.e. it covers the range [0,N-1]. The left child of the root must then cover the range [0,γ], for some appropriate choice of γ, and the right child covers the range [γ+1,N-1]. We can continue this all the way down to obtain the following recursive algorithm.
Node* generateHierarchy( unsigned int* sortedMortonCodes,
int* sortedObjectIDs,
int first,
int last)
{
// Single object => create a leaf node.
if (first == last)
return new LeafNode(&sortedObjectIDs[first]);
// Determine where to split the range.
int split = findSplit(sortedMortonCodes, first, last);
// Process the resulting sub-ranges recursively.
Node* childA = generateHierarchy(sortedMortonCodes, sortedObjectIDs,
first, split);
Node* childB = generateHierarchy(sortedMortonCodes, sortedObjectIDs,
split + 1, last);
return new InternalNode(childA, childB);
}
We start with a range that covers all objects (first=0, last=N-1), and determine an appropriate position to split the range in two (split=γ). We then repeat the same thing for the resulting sub-ranges, and generate a hierarchy where each such split corresponds to one internal node. The recursion terminates when we encounter a range that contains only one item, in which case we create a leaf node. 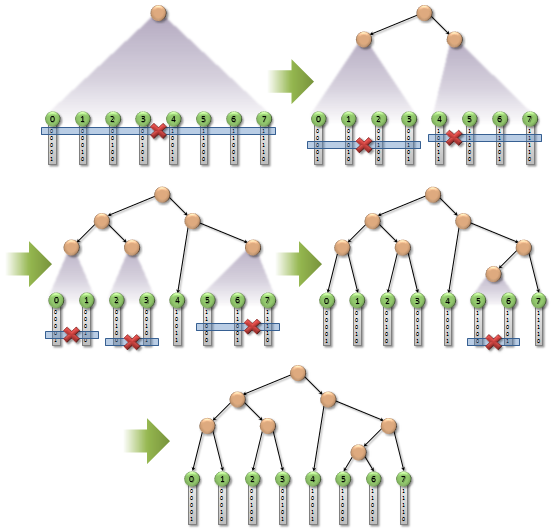 The only remaining question is how to choose γ. LBVH determines γ according to the highest bit that differs between the Morton codes within the given range. In other words, we aim to partition the objects so that the highest differing bit will be zero for all objects in
The only remaining question is how to choose γ. LBVH determines γ according to the highest bit that differs between the Morton codes within the given range. In other words, we aim to partition the objects so that the highest differing bit will be zero for all objects in childA, and one for all objects in childB. The intuitive reason that this is a good idea is that partitioning objects by the highest differing bit in their Morton codes corresponds to classifying them on either side of an axis-aligned plane in 3D. In practice, the most efficient way to find out where the highest bit changes is to use binary search. The idea is to maintain a current best guess for the position, and try to advance it in exponentially decreasing steps. On each step, we check whether the proposed new position would violate the requirements for childA, and either accept or reject it accordingly. This is illustrated by the following code, which uses the __clz() intrinsic function available in NVIDIA Fermi and Kepler GPUs to count the number of leading zero bits in a 32-bit integer.
int findSplit( unsigned int* sortedMortonCodes,
int first,
int last)
{
// Identical Morton codes => split the range in the middle.
unsigned int firstCode = sortedMortonCodes[first];
unsigned int lastCode = sortedMortonCodes[last];
if (firstCode == lastCode)
return (first + last) >> 1;
// Calculate the number of highest bits that are the same
// for all objects, using the count-leading-zeros intrinsic.
int commonPrefix = __clz(firstCode ^ lastCode);
// Use binary search to find where the next bit differs.
// Specifically, we are looking for the highest object that
// shares more than commonPrefix bits with the first one.
int split = first; // initial guess
int step = last - first;
do
{
step = (step + 1) >> 1; // exponential decrease
int newSplit = split + step; // proposed new position
if (newSplit < last)
{
unsigned int splitCode = sortedMortonCodes[newSplit];
int splitPrefix = __clz(firstCode ^ splitCode);
if (splitPrefix > commonPrefix)
split = newSplit; // accept proposal
}
}
while (step > 1);
return split;
}
How should we go about parallelizing this kind of recursive algorithm? One way is to use the approach presented by Garanzha et al., which processes the levels of nodes sequentially, starting from the root. The idea is to maintain a growing array of nodes in a breadth-first order, so that every level in the hierarchy corresponds to a linear range of nodes. On a given level, we launch one thread for each node that falls into this range. The thread starts by reading first and last from the node array and calling findSplit(). It then appends the resulting child nodes to the same node array using an atomic counter and writes out their corresponding sub-ranges. This process iterates so that each level outputs the nodes contained on the next level, which then get processed in the next round.
Occupancy
The algorithm just described (Garanzha et al.) is surprisingly fast when there are millions of objects. The algorithm spends most of the execution time at the bottom levels of the tree, which contain more than enough work to fully employ the GPU. There is some amount of data divergence on the higher levels, as the threads are accessing distinct parts of the Morton code array. But those levels are also less significant considering the overall execution time, since they do not contain as many nodes to begin with. In our case, however, there are only 12K objects (recall the example seen from the last post). Note that this is actually less than the number of threads we would need to fill our GTX 690, even if we were able to parallelize everything perfectly. GTX 690 is a dual-GPU card, where each of the two GPUs can run up to 16K threads in parallel. Even if we restrict ourselves to only one of the GPUs—the other one can e.g. handle rendering while we do physics—we are still in danger of running low on parallelism.
The top-down algorithm takes 1.04 ms to process our workload, which is more than twice the total time taken by all the other processing steps. To explain this, we need to consider another metric in addition to divergence: occupancy. Occupancy is a measure of how many threads are executing on average at any given time, relative to the maximum number of threads that the processor can theoretically support. When occupancy is low, it translates directly to performance: dropping occupancy in half will reduce performance by 2x. This dependence gets gradually weaker as the number of active threads increases. The reason is that when occupancy is high enough, the overall performance starts to become limited by other factors, such as instruction throughput and memory bandwidth.
To illustrate, consider the case with 12K objects and 16K threads. If we launch one thread per object, our occupancy is at most 75%. A bit low, but not by any means catastrophic. How does the top-down hierarchy generation algorithm compare to this? There is only one node on the first level, so we launch only one thread. This means that the first level will run at 0.006% occupancy! The second level has two nodes, so it runs at 0.013% occupancy. Assuming a balanced hierarchy, the third level runs at 0.025% and the fourth at 0.05%. Only when we get to the 13th level, can we even hope to reach a reasonable occupancy of 25%. But right after that we will already run out of work. These numbers are somewhat discouraging—due to the low occupancy, the first level will cost roughly as much as the 13th level, even though there are 4096 times fewer nodes to process.
Fully Parallel Hierarchy Generation
There is no way to avoid this problem without somehow changing the algorithm in a fundamental way. Even if our GPU supports dynamic parallelism (as NVIDIA Tesla K20 does), we cannot avoid the fact that every node is dependent on the results of its parent. We have to finish processing the root before we know which ranges its children cover, and we cannot even hope to start processing them until we do. In other words, regardless of how we implement top-down hierarchy generation, the first level is doomed to run at 0.006% occupancy. Is there a way to break the dependency between nodes?
In fact there is, and I recently presented the solution at High Performance Graphics 2012 (paper, slides). The idea is to number the internal nodes in a very specific way that allows us to find out which range of objects any given node corresponds to, without having to know anything about the rest of the tree. Utilizing the fact that any binary tree with N leaf nodes always has exactly N-1 internal nodes, we can then generate the entire hierarchy as illustrated by the following pseudocode.
Node* generateHierarchy( unsigned int* sortedMortonCodes,
int* sortedObjectIDs,
int numObjects)
{
LeafNode* leafNodes = new LeafNode[numObjects];
InternalNode* internalNodes = new InternalNode[numObjects - 1];
// Construct leaf nodes.
// Note: This step can be avoided by storing
// the tree in a slightly different way.
for (int idx = 0; idx < numObjects; idx++) // in parallel
leafNodes[idx].objectID = sortedObjectIDs[idx];
// Construct internal nodes.
for (int idx = 0; idx < numObjects - 1; idx++) // in parallel
{
// Find out which range of objects the node corresponds to.
// (This is where the magic happens!)
int2 range = determineRange(sortedMortonCodes, numObjects, idx);
int first = range.x;
int last = range.y;
// Determine where to split the range.
int split = findSplit(sortedMortonCodes, first, last);
// Select childA.
Node* childA;
if (split == first)
childA = &leafNodes[split];
else
childA = &internalNodes[split];
// Select childB.
Node* childB;
if (split + 1 == last)
childB = &leafNodes[split + 1];
else
childB = &internalNodes[split + 1];
// Record parent-child relationships.
internalNodes[idx].childA = childA;
internalNodes[idx].childB = childB;
childA->parent = &internalNodes[idx];
childB->parent = &internalNodes[idx];
}
// Node 0 is the root.
return &internalNodes[0];
}
The algorithm simply allocates an array of N-1 internal nodes, and then processes all of them in parallel. Each thread starts by determining which range of objects its node corresponds to, with a bit of magic, and then proceeds to split the range as usual. Finally, it selects children for the node according to their respective sub-ranges. If a sub-range has only one object, the child must be a leaf so we reference the corresponding leaf node directly. Otherwise, we reference another internal node from the array. 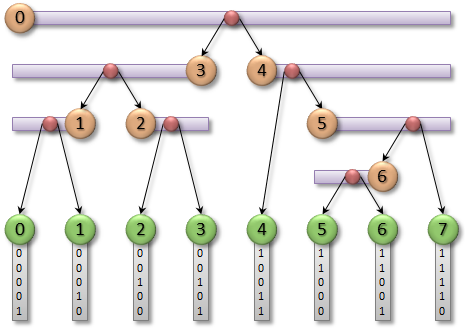 The way the internal nodes are numbered is already evident from the pseudocode. The root has index 0, and the children of every node are located on either side of its split position. Due to some nice properties of the sorted Morton codes, this numbering scheme never results in any duplicates or gaps. Furthermore, it turns out that we can implement
The way the internal nodes are numbered is already evident from the pseudocode. The root has index 0, and the children of every node are located on either side of its split position. Due to some nice properties of the sorted Morton codes, this numbering scheme never results in any duplicates or gaps. Furthermore, it turns out that we can implement determineRange() in much the same way as findSplit(), using two similar binary searches over the nearby Morton codes. For further details on how and why this works, please see the paper.
How does this algorithm compare to the recursive top-down approach? It clearly performs more work—we now need three binary searches per node, whereas the top-down approach only needs one. But it does all of the work completely in parallel, reaching the full 75% occupancy in our example, and this makes a huge difference. The execution time of parallel hierarchy generation is merely 0.02 ms—a 50x improvement over the top-down algorithm!
You might think that the top-down algorithm should start to win when the number of objects is sufficiently high, since the lack of occupancy is no longer a problem. However, this is not the case in practice—the parallel algorithm consistently performs better on all problem sizes. The explanation for this is, as always, divergence. In the parallel algorithm, nearby threads are always accessing nearby Morton codes, whereas the top-down algorithm spreads out the accesses over a wider area.
Bounding Box Calculation
Now that we have a hierarchy of nodes in place, the only thing left to do is to assign a conservative bounding box for each of them. The approach I adopt in my paper is to do a parallel bottom-up reduction, where each thread starts from a single leaf node and walks toward the root. To find the bounding box of a given node, the thread simply looks up the bounding boxes of its children and calculates their union. To avoid duplicate work, the idea is to use an atomic flag per node to terminate the first thread that enters it, while letting the second one through. This ensures that every node gets processed only once, and not before both of its children are processed. The bounding box calculation has high execution divergence—only half of the threads remain active after processing one node, one quarter after processing two nodes, one eigth after processing three nodes, and so on. However, this is not really a problem in practice because of two reasons. First, bounding box calculation takes only 0.06 ms, which is still reasonably low compared to e.g. sorting the objects. Second, the processing mainly consists of reading and writing bounding boxes, and the amount of computation is minimal. This means that the execution time is almost entirely dictated by the available memory bandwidth, and reducing execution divergence would not really help that much.
SUMMARY
Our algorithm for finding potential collisions among a set of 3D objects consists of the following 5 steps (times are for the 12K object scene used in the previous post).
- 0.02 ms, one thread per object: Calculate bounding box and assign Morton code.
- 0.18 ms, parallel radix sort: Sort the objects according to their Morton codes.
- 0.02 ms, one thread per internal node: Generate BVH node hierarchy.
- 0.06 ms, one thread per object: Calculate node bounding boxes by walking the hierarchy toward the root.
- 0.25 ms, one thread per object: Find potential collisions by traversing the BVH.
The complete algorithm takes 0.53 ms, out of which 53% goes to tree construction and 47% to tree traversal.
Discussion
We have presented a number of algorithms of varying complexity in the context of broad-phase collision detection, and identified some of the most important considerations when designing and implementing them on a massively parallel processor. The comparison between independent traversal and simultaneous traversal illustrates the importance of divergence in algorithm design—the best single-core algorithm may easily turn out to be the worst one in a parallel setting. Relying on time complexity as the main indicator of a good algorithm can sometimes be misleading or even harmful—it may actually be beneficial to do more work if it helps in reducing divergence.
The parallel algorithm for BVH hierarchy generation brings up another interesting point. In the traditional sense, the algorithm is completely pointless—on a single-core processor, the dependencies between nodes were not a problem to begin with, and doing more work per node only makes the algorithm run slower. This shows that parallel programming is indeed fundamentally different from traditional single-core programming: it is not so much about porting existing algorithms to run on a parallel processor; it is about re-thinking some of the things that we usually take for granted, and coming up with new algorithms specifically designed with massive parallelism in mind.
And there is still a lot to be accomplished on this front.