By Adnan Boz (GTC 2012 Guest Blogger)
 Question: Why would you need 50 petaflops of horsepower and a 500,000 scalar processor capable supercomputer?
Question: Why would you need 50 petaflops of horsepower and a 500,000 scalar processor capable supercomputer?
Answer: You need to simulate dynamics of complex fluid systems!
On Day 3 of GTC, HPC architect and Ogden prize winner Dr. Alan Gray from the University of Edinburgh described his use of C, MPI and CUDA on an NVIDIA Tesla -powered Cray XK6 hybrid supercomputer to run massively parallel Lattice-Boltzmann methods.
“Simulating simple fluids like water requires massive amount of computer power, but simulating complex fluids like mixtures, surfactants, liquid crystals or particle suspensions, requires much more than that,” commented Dr. Gray.
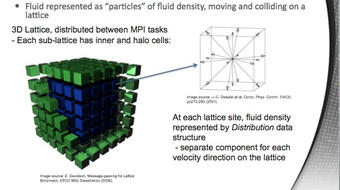
Because the Lattice-Boltzmann method generally needs only nearest neighbor information and the data volume can be divided into spatially contiguous blocks along one axis, the algorithm was an ideal candidate for NVIDIA’s SIMD architecture. Dr. Gray is using 1933 (a total of 7,529,536) particles on every one of the 1000 GPUs. He has achieved a 2x performance over a previously-tested CPU-only solution, with just half the node count.
Dr. Gray pointed out that running algorithms on many cores and many machines would be a bigger challenge if we did not have well-tested and proven libraries. He referred to a library called Ludwig, a versatile code for the simulation of Lattice-Boltzmann models in 3D on cubic lattices. It is capable of simulating the hydrodynamics of complex fluids in 3D. If Ludwig is used as intended, a variety of complex fluid models with different equilibrium free energies are simple to code, so that the user may concentrate on the physics of the problem, rather than on parallel computing issues see: http://arxiv.org/pdf/cond-mat/0005213.pdf)
Even though libraries like cuBLAS, cuFFT and Ludwig provide the infrastructure for parallelizing algorithms, non-optimized code will always give poor performance. That is exactly what happened initially with Dr. Gray’s project; in order to achieve highest performance he had to tune register usage, take memory coalescing into account and introduce asynchronous streaming to pipeline multiple kernel executions. So, no matter what size of a problem we are working on, we have to look for optimization opportunities on CUDA.
Be sure to watch the streamcast of this presentation : Scaling Applications to a Thousand GPUs and Beyond
About our Guest Blogger
 Adnan Boz is an NVIDIA certified CUDA programmer working at Yahoo! He is also the organizer of the South Florida GPU Meetup.
Adnan Boz is an NVIDIA certified CUDA programmer working at Yahoo! He is also the organizer of the South Florida GPU Meetup.