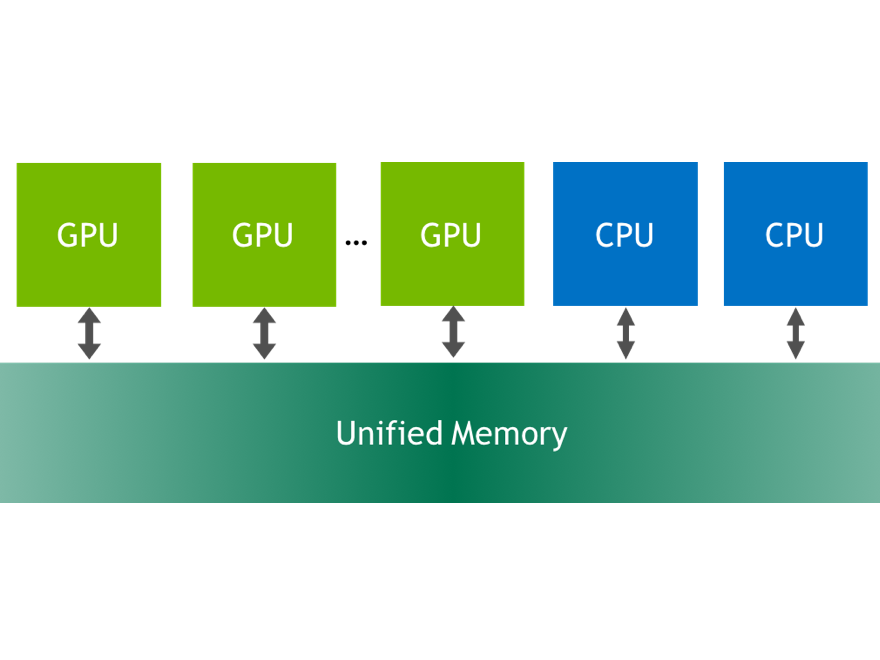
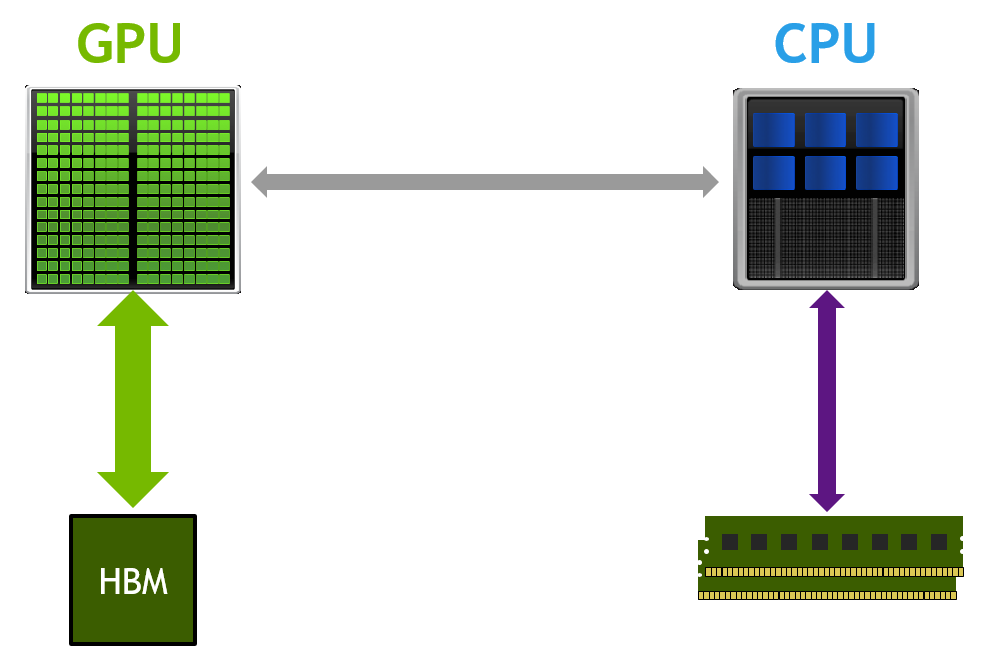
Unified Memory is a CUDA feature that we’ve talked a lot about on Parallel Forall. CUDA 6 introduced Unified Memory, which dramatically simplifies GPU programming by giving programmers a single pointer to data which is accessible from either the GPU or the CPU. But this enhanced memory model has only been available to CUDA C/C++ programmers, until now. The new PGI Compiler release 14.7 enables Unified Memory in CUDA Fortran.
In a PGInsider article called CUDA Fortran Managed Memory, PGI Applications and Services Manager Brent Leback writes “using managed memory simplifies many coding tasks, makes source code cleaner, and enables a unified view of complicated data structures across host and device memories.” PGI 14.7 adds the managed keyword to the language, which you can use in host code similarly to the device keyword. Here’s part of an example Brent included in his article, showing the allocation of managed arrays.
! matrix data real, managed, allocatable, dimension(:,:) :: A, B, C real, allocatable, dimension(:,:) :: gold
See the article for the complete example, which demonstrates a dramatic simplification in the GPU memory management code. As Brent explains:
As you can see, we no longer need two copies of the arrays A, B, and C. The data movement still happens, but rather than being explicit, now it is controlled by the unified memory management system behind the scenes, much like the way an OS manages virtual memory.
If your CUDA Fortran program is bogged down with two copies of variables, like
variable_namefor the host, andvariable_name_dfor the device, then managed memory might be the answer for you.
Just as in CUDA C++, Unified Memory simplifies sharing complex data structures between CPU and GPU code. Brent writes:
One area where CUDA Fortran managed data really shines is with derived types. Before, using device data, derived types were awkward because a derived type containing
allocatabledevice arrays could not itself easily have thedeviceattribute. So, in effect, some fields of the derived type were resident on the device while other fields were resident on the host. Managing that programmatically was cumbersome as the types became larger and more deeply nested.Now, if your program makes use of derived types in its computational core, managed data seems like a great way to go. Only the data that is required will be moved on demand. If large areas of the types are not accessed, they will not incur the overhead of being moved back and forth. Furthermore, putting these types in modules, both the definitions and instantiated entities, means they can be used in both host and device code and don’t need to be passed as arguments.
If you are a Fortran user, download PGI 14.7 and give CUDA Fortran Managed Memory a try.