Today we’re excited to announce the release of the CUDA Toolkit version 6.5. CUDA 6.5 adds a number of features and improvements to the CUDA platform, including support for CUDA Fortran in developer tools, user-defined callback functions in cuFFT, new occupancy calculator APIs, and more.
CUDA on ARM64
Last year we introduced CUDA on Arm, and in March we released the Jetson TK1 developer board, which enables development of CUDA on the NVIDIA Tegra K1 system-on-a-chip which includes a quad-core 32-bit Arm CPU and an NVIDIA Kepler GPU. There is a lot of excitement about developing mobile and embedded parallel computing applications on Jetson TK1. And this week at the Hot Chips conference, we provided more details about our upcoming 64-bit Denver Arm CPU architecture.
CUDA 6.5 takes the next step, enabling CUDA on 64-bit Arm platforms. The heritage of ARM64 is in low-power, scale-out data centers and microservers, while GPUs are built for ultra-fast compute performance. When we combine the two, we have a compelling solution for HPC. ARM64 provides power efficiency, system configurability, and a large, open ecosystem. GPUs bring to the table high-throughput, power-efficient compute performance, a large HPC ecosystem, and hundreds of CUDA-accelerated applications. For HPC applications, ARM64 CPUs can offload the heavy lifting of computational tasks to GPUs. CUDA and GPUs make ARM64 competitive in HPC from day one.
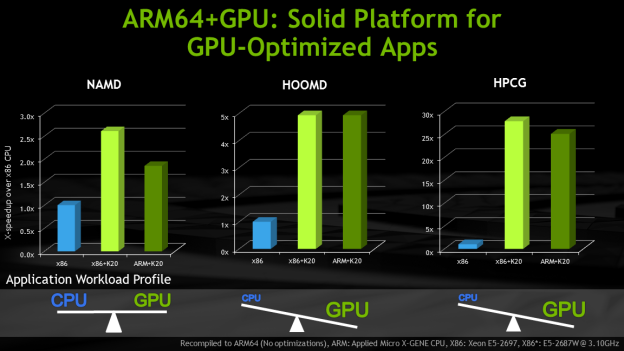
Development platforms available now for CUDA on ARM64 include the Cirrascale RM1905D HPC Development Platform and the E4 ARKA EK003. Eurotech has announced a system available later this year. These platforms are built on Applied Micro X-Gene 8-core 2.4GHz ARM64 CPUs, Tesla K20 GPU Accelerators, and CUDA 6.5. As Figure 1 shows, performance of CUDA-accelerated applications on ARM64+GPU systems is competitive with x86+GPU systems.
cuFFT Device Callbacks
Users of cuFFT often need to transform input data before performing an FFT, or transform output data afterwards. Before CUDA 6.5, doing this required running additional CUDA kernels to load, transform, and store the data. I emphasize load and store because these transform kernels increase the bandwidth used by applications, and that’s where cuFFT device callbacks come in.
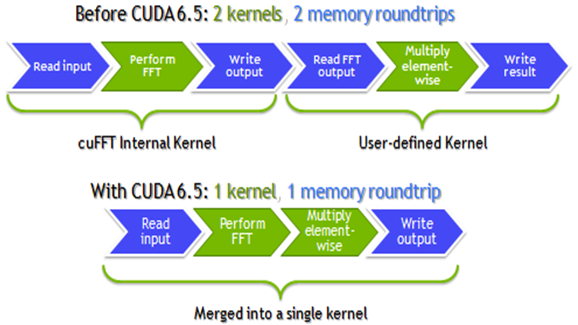
cuFFT 6.5 lets you specify CUDA device callback functions that re-direct or manipulate the data as it is loaded before processing the FFT, and/or before it is stored after the FFT. This means cuFFT can transform the input and output data without extra bandwidth usage above what the FFT itself uses, as Figure 2 shows. This can be a significant performance benefit.
CUDA Fortran tools support
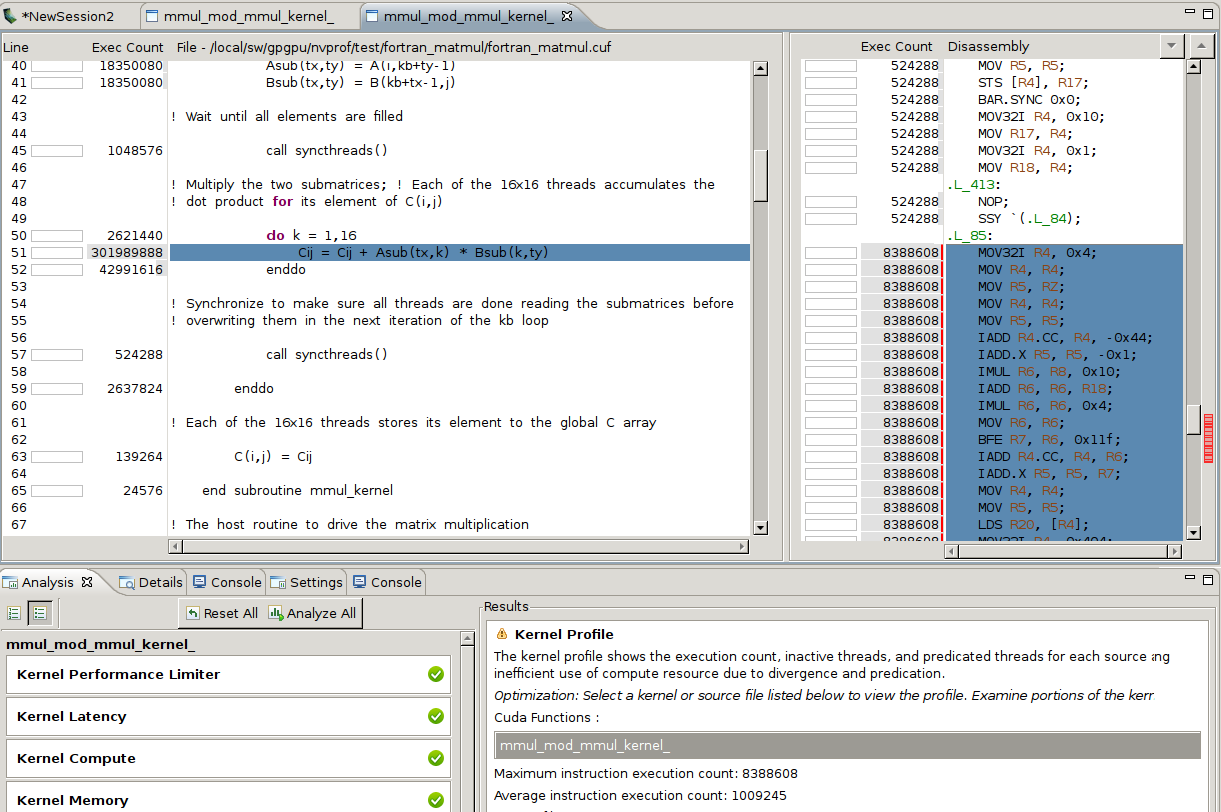
CUDA 6.5 adds improved support for CUDA Fortran in the cuda-gdb debugger, the nvprof command line profiler, cuda-memcheck, and the NVIDIA Visual Profiler (see Figure 3). This includes debugging support for FORTRAN arrays (in Linux only), improved source-to-assembly code correlation, and better documentation. CUDA Fortran tools support is a beta feature in CUDA 6.5, and requires PGI compiler version 14.4 or higher.
CUDA Occupancy Calculator APIs
CUDA 6.5 provides new CUDA occupancy calculator and occupancy-based launch configuration API interfaces. These functions help set execution configurations with reasonable occupancy. I wrote about this new functionality in CUDA Pro Tip: Simplify Launch Configuration with New CUDA Occupancy API. CUDA 6.5 also includes a substantially rewritten stand-alone programmatic occupancy calculator implementation (introduced as a beta in CUDA 6.0), cuda_occupancy.h. This file includes stand-alone implementations of both the occupancy calculator and the occupancy-based launch configuration functions, so applications can use them without depending on the entire CUDA software stack.
Other Improvements
CUDA 6.5 includes many other improvements to functionality and performance, as well as new features. Here are just a few.
Support for Visual Studio 2013
CUDA 6.5 expands host compiler support to include Microsoft Visual Studio 2013 for Windows.
Double Precision Performance Improvements
The core math libraries in CUDA 6.5 introduce significant performance improvements for many double precision functions, notably sqrt(), rsqrt(), hypot(), log(), log2(). These optimizations can result in real performance improvements in applications. My double precision n-body gravitational simulation code running on an NVIDIA Tesla K40 GPU achieves 801 fp64 GFLOP/s with CUDA 6.5, versus 698 GFLOP/s with CUDA 6.0. That’s nearly a 15% improvement with no application code changes, thanks to optimizations in the fp64 implementation of rsqrt() in the CUDA math library.
Static CUDA Libraries
CUDA 6.5 (on Linux and Mac OS) now includes static library versions of the cuBLAS, cuSPARSE, cuFFT, cuRAND, and NPP libraries. This can reduce the number of dynamic library dependencies you need to include with your deployed applications. These new static libraries depend on a common thread abstraction layer library cuLIBOS (libculibos.a) distributed as part of the CUDA toolkit.
New Tool: nvprune
nvprune is a new binary utility which prunes host object files and libraries to only contain device code for the specified target architectures. For example, the following command line prunes libcublas_static.a to only contain sm_35 code and remove all other targets contained by the library.
nvprune -arch sm_35 libcublas_static.a -o libcublas_static35.a
Software developers may find nvprune useful for reducing the GPU object file sizes in their apps, especially if they use third-party or NVIDIA libraries.
MPS Performance Improvements
The CUDA Multi-Process Service (MPS) transparently enables cooperative multiprocess CUDA applications, typically MPI jobs, to run kernels from multiple processes concurrently on individual GPUs. CUDA 6 introduced MPS, and CUDA 6.5 significantly improves MPS performance: reducing launch latency from 7 to 5 microseconds, and reducing launch and synchronize latency from 35 to 15 microseconds.
Improved Xid Error Reporting
NVIDIA driver Xid error reporting reports general GPU errors via the operating system’s kernel or event logs. The messages can indicate hardware problems, NVIDIA software problems, or user application problems. CUDA 6.5 improves Xid error 13 reporting on Linux to give more detail and show the type of the Xid 13 error cause. Here is an example error message from earlier CUDA versions.
GPU at 0000:07:00: GPU-b850f46d-d5ea-c752-ddf3-c4453e44d3f7 Xid (0000:07:00): 13, 0003 00000000 0000a1c0 000002bc 00000003 00000000
The same error message could be displayed for a number of causes. CUDA 6.5 differentiates Xid 13 errors based on the type of cause, as shown here.
Xid (0000:07:00): 13, Graphics SM Warp Exception on (GPC 0, TPC 4): Stack Error Xid (0000:07:00): 13, Graphics Exception: ESR - 0x506648=0x2000d, 0x506650=0x0, 0x506644=0xd3eff2, 0x50664c=0x7f Xid (0000:07:00): 13, Graphics Exception: ChID 0002, Class 0000a1c0, Offset 000002bc, Data 00000003
Download CUDA 6.5 Today!
CUDA 6.5 includes all of these new features and improvements, as well as others, including support for Block Sparse Row (BSR) format matrices in cuSparse, and Application Replay mode in the NVIDIA Visual Profiler that enables faster analysis of complex scenarios involving multiple hardware counters. Visit CUDA Zone to download the CUDA Toolkit version 6.5 today, read the release notes, or the latest CUDA docs.