This post concludes an introductory series on CUDA dynamic parallelism. In this post, I finish the series with a case study on an online track reconstruction algorithm for the high-energy physics PANDA experiment.
- In my first post, I introduced dynamic parallelism by using it to compute images of the Mandelbrot set using recursive subdivision, resulting in large increases in performance and efficiency.
- The second post is an in-depth tutorial on the ins and outs of programming with dynamic parallelism, including synchronization, streams, memory consistency, and limits.
The PANDA work was carried out in the scope of the NVIDIA Application Lab at Jülich.
The PANDA experiment
PANDA (anti-Proton ANnihilation at DArmstadt) is a state-of-the-art hadron particle physics experiment currently under construction at Facility for Anti-proton and Ion Research (FAIR) at Darmstadt. It is scheduled to start operation in 2019.
Inside the PANDA experiment, accelerated antiprotons will collide with protons, forming intermediate and unstable particles (mesons, baryons, and so on), which will decay in cascades into stable particles, like electrons and photons.
The unstable particles are of particular interest for PANDA, as they give insight into the processes governing this physics regime (QCD). Reconstructing all involved constituent particles of an event lets the physicists form a picture of the process, eventually confirming established physics theories, probing new ones, and potentially finding exciting and unexpected results.
A typical particle physics experiment continuously reads out only a part of the whole detector. Only the data sub-samples from dedicated and fast trigger sub-detectors are processed at all times. When the trigger sub-system records a signal of a physical event of interest, such as a muon of particular momentum, it triggers the data recording of the whole detector system. Only then are all of the sub-detector layers read out and saved to disk for further offline analysis.
PANDA wants to do research in seldom and possibly exotic physics cases. Because of this, the experiment wants to use an online, triggerless event reconstruction. It will process the incoming data stream of the whole experiment on the fly, run sophisticated reconstruction algorithms, and use this to decide whether or not to save a particular event for further, more precise, and elaborate offline analysis.
Running with an event rate of 20 million events per second results in a large amount of data. The structure of the antiproton beam, colliding in the center of the PANDA experiment, is as follows: 1600 ns long bursts, in which collisions are performed, are interleaved with collisionless 400 ns gaps. Each burst contains 40 events on average.
An important part of PANDA’s online reconstruction is online tracking. Tracking is the process of using the discrete detector responses (hits) particles leave while traversing active detector material to form the real, continuous trajectories of the particles (tracks).
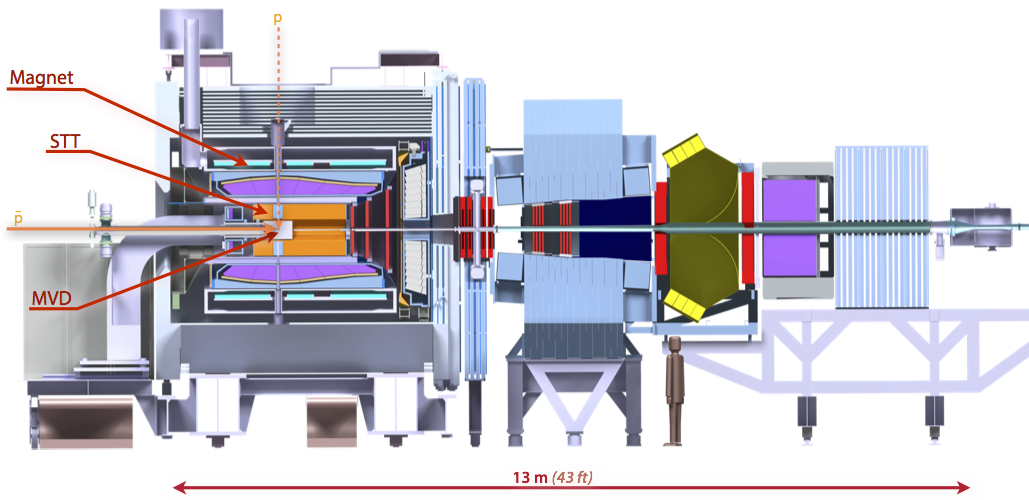
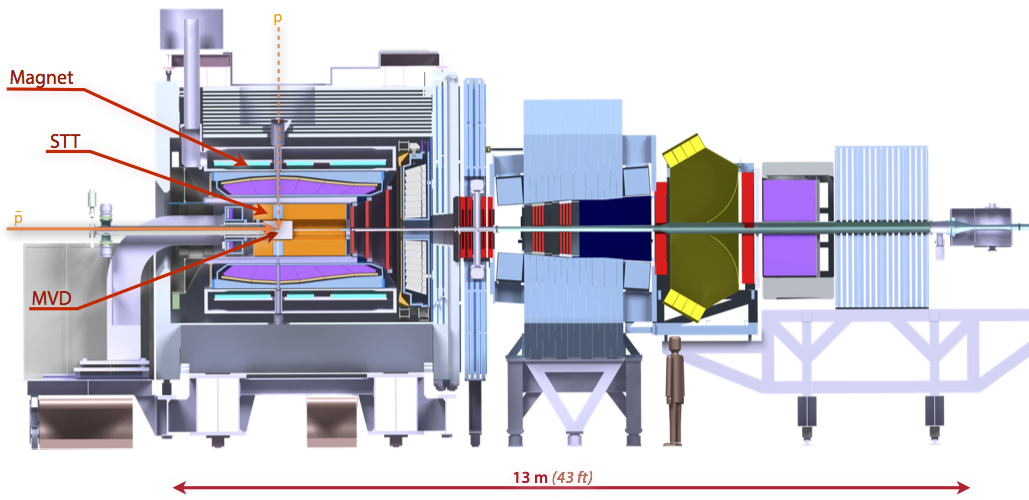
Two sub-detectors of the experiment are of particular interest for online tracking (Figure 1):
- Straw Tube Tracker (STT): A sub-detector using more than 4000 tiny drift tubes (straws) to locate particles.
- Micro Vertex Detector (MVD): PANDA’s innermost, silicon-based detector with 10 million channels.
Each event generates about 80 STT hits, which equates to 1.6 billion hits per second; the number of hits produced by the MVD is about a quarter of that. In total, the experiment will produce a data rate of 200 GB/s, which must be processed by the online reconstruction stage.
Online processing is intended to reduce the total volume of data by a factor of 1000 (from 200 GB/s to 200 MB/s), which will then be stored for further processing by scientists.
Triplet Finder algorithm
One of the candidate algorithms for online tracking is the Triplet Finder, which operates on STT hits. The idea of the algorithm is to trade in accuracy for speed: running at an early stage of the experiment’s reconstruction, the algorithm primarily has to be fast rather than precise. The precision needed for high-quality physics can still be achieved later on in the reconstruction chain with dedicated, but slower running algorithms.
The Triplet Finder uses certain layers of straws in the STT to seed particle track reconstruction; these are called pivot straws. Currently, 3 rows are selected as the ones with pivot straws (Figure 2).
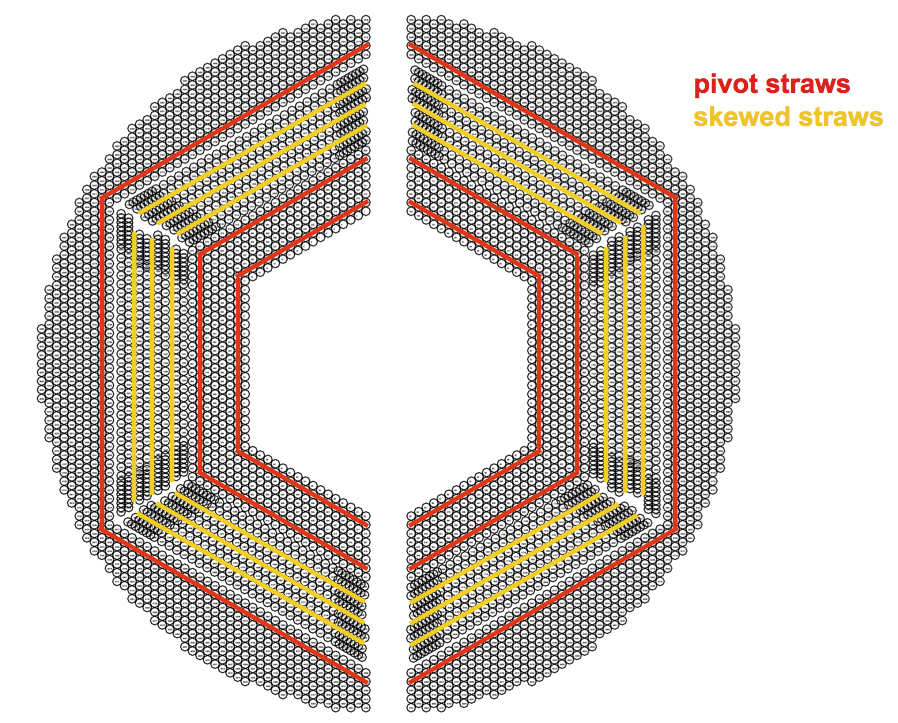
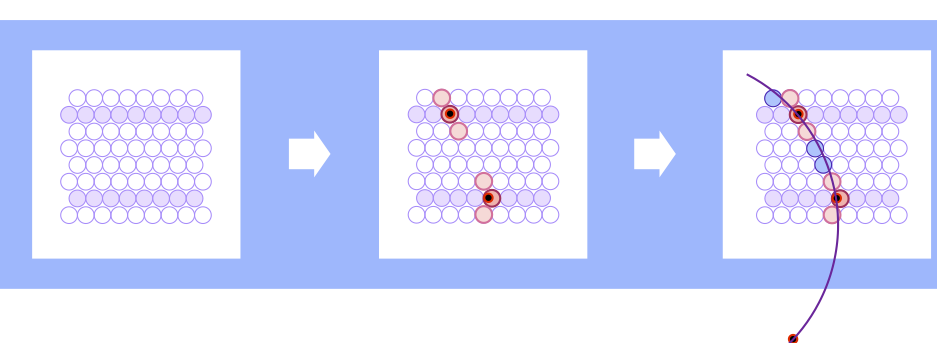
The algorithm starts by generating triplets for each tube in the pivot layers. A triplet is a virtual hit, using a center of gravity method to combine a hit in the pivot straw with two neighboring hits. A pair of triplets from different pivot layers is combined with the coordinate origin to form a single circular track candidate, as shown in Figure 3. A track candidate is validated by associating hits from the non-pivot layers with it. Hits need to be close to the track and surpass, in number, a certain threshold for the track candidate to be accepted.
Running the algorithm like this gives only two-dimensional information about the track in the plane orthogonal to the direction of the straws. To extract 3D information, a similar but more computationally demanding algorithm is applied to slightly tilted or skewed straws. For more information, see the Triplet based online track finding in the PANDA-STT paper.
Online reconstruction has to process large quantities of data and also has a large amount of parallelism. Different bursts can be processed independently. If necessary, each burst can be further subdivided into smaller time intervals called bunches, which can also be processed in parallel. The Triplet Finder algorithm can thus be summarized as follows:
- The entire set of hits is split into bunches, which can be processed in parallel.
- Each bunch is processed in a sequence of stages, which are performed sequentially.
- Within each stage, there is additional significant parallelism present.
- A single bunch is not enough to utilize a GPU fully; to do that, O(10), or better, O(100) bunches are needed.
Implementing Triplet Finder with dynamic parallelism
The earlier description of the task yields naturally to an implementation with CUDA dynamic parallelism.
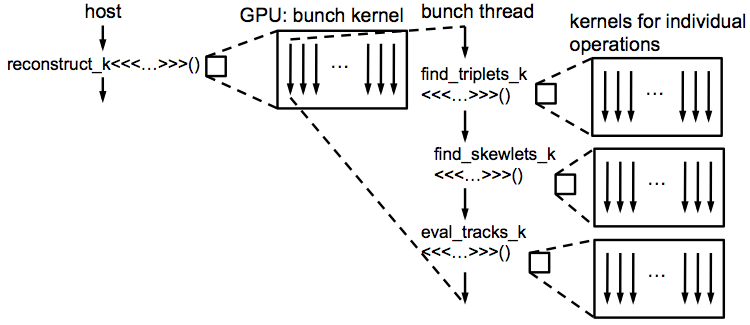
Each processing stage is implemented as a GPU kernel or a sequence of kernels. The host launches the reconstruction kernel, where each thread is responsible for a single bunch. Every thread then launches the kernels for its bunch, performing necessary synchronizations. As different bunches can be processed independently, each thread creates a single device stream to launch its kernels.
To reduce false dependencies and provide better concurrency, the number of threads per block in the reconstruction kernel is set to a low value. We found that 8 works well in practice. The entire kernel call tree is schematically depicted in Figure 4.
The complete source code for the CUDA dynamic parallelism implementation of the GPU Triplet Finder can be downloaded from PANDA SVN.
Performance comparison
We compared the performance of our dynamic parallelism implementation of Triplet Finder with a version that uses the same stage processing kernels, but launches them all from the host using one stream per bunch. Different bunch sizes were required for each approach. For host streams, setting the CUDA_DEVICE_MAX_CONNECTIONS environment variable to 24 gave the best performance.
Figure 5 shows the relative performance of both approaches on an NVIDIA v100 K20X GPU using CUDA 5.5 with driver version 331.22 and CUDA 6.0 with driver version 331.49. A clear performance improvement can be seen for both dynamic parallelism and host streams versions between CUDA 5.5 to CUDA 6.0.
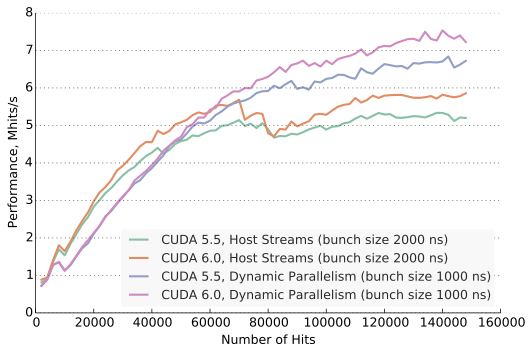
The dynamic parallelism implementation of Triplet Finder uses 1000 ns bunches, while for the host streams approach, 2000 ns bunches are used. This is because the host streams approach is limited by kernel launch throughput, and it is beneficial to have a smaller number of larger kernels, even if this leads to a larger amount of computation. For a reasonable number of hits, using dynamic parallelism results in 20% faster processing.
Dynamic parallelism is better than host streams for the following reasons:
- Avoiding extra PCI-e data transfers. The launch configuration of each subsequent kernel depends on the results of the previous kernel, which are stored in device memory. For the dynamic parallelism version, reading these results requires just a single memory access, while for host streams a data transfer from device to host is needed.
- Achieving higher launch throughput with dynamic parallelism, when compared to launching from host using multiple streams.
- Reducing false dependencies between kernel launches. All host streams are served by a single thread, which means that when waiting on a single stream, work cannot be queued into other streams, even if the data for launch configuration is available. For dynamic parallelism, there are multiple thread blocks queuing kernels executed asynchronously.
The dynamic parallelism version is also more straightforward to implement and leads to cleaner and more readable code. So in the case of PANDA, using dynamic parallelism improved both performance and productivity.
What dynamic parallelism is not
With all the advantages of dynamic parallelism, however, it is also important to understand when not to use it.
In all the examples in this series of posts, when a child kernel is launched, it always consisted of a large number of threads and also a large number of thread blocks. It is possible in some cases for each child grid to consist of a single thread block, which still contains O(100) threads.
However, it is a bad idea to start a child grid with just a few threads. This would lead to severe underutilization of GPU parallelism, since only a few threads in a warp would be active, and there would not be enough warps. This would also lead to GPU execution dominated by kernel launch latencies.
Nested parallelism can be visualized in a form of a tree. But the tree for dynamic parallelism looks very different from more traditional CPU tree processing (Table 1).
| characteristic | tree processing | dynamic parallelism |
| node | thin (1 thread) | thick (many threads) |
| branch degree | small (usually < 10) | large (usually > 100) |
| depth | large | small |
You can now see that dynamic parallelism is useful when it results in fat but relatively shallow trees. Adaptive grid algorithms often result in such trees. Traditional tree processing, in contrast, usually involves trees with small node degree but large depth, and is not a good use case for dynamic parallelism.
Conclusion
Dynamic parallelism provides clear benefits for applications that exhibit nested parallelism patterns. This applies to applications using hierarchical data structures, as well as applications processing non-uniform bunches of work.
As you have seen in this series with both the Mariani-Silver algorithm and bunch processing for the Triplet Finder, using dynamic parallelism enables you to write such applications in a natural and easy-to-understand way. In addition to better productivity, using dynamic parallelism also increases the performance and efficiency of your code.