Today software companies use frameworks such as .NET to target multiple platforms from desktops to mobile phones with a single code base to reduce costs by leveraging existing libraries and to cope with changing trends. While developers can easily write scalable parallel code for multi-core CPUs on .NET with libraries such as the task parallel library, they face a bigger challenge using GPUs to tackle compute intensive tasks. To accelerate .NET applications with GPUs, developers must write functions in CUDA C/C++ and write or generate code to interoperate between .NET and CUDA C/C++.
Alea GPU closes this gap by bringing GPU computing directly into the .NET ecosystem. With Alea GPU you can write GPU functions in any .NET language you like, compile with your standard .NET build tool and accelerate it with a GPU. Alea GPU offers a full implementation of all CUDA features, and code compiled with Alea GPU performs as well as equivalent CUDA C/C++ code.
CUDA on .NET with Alea GPU
Alea GPU is a professional CUDA development stack for .NET and Mono built directly on top of the NVIDIA compiler toolchain. Alea GPU offers the following benefits:
- Easy to use
- Cross-platform
- Support for many existing GPU algorithms and libraries
- Debugging and profiling functionality
- JIT compilation and a compiler API for GPU scripting
- Future-oriented technology based on LLVM
- No compromise on performance
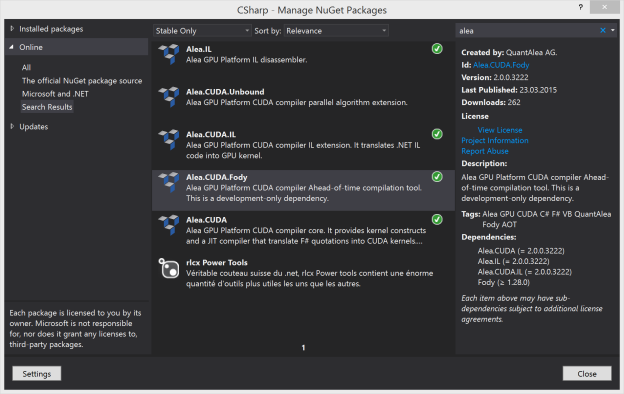
You can easily install Alea GPU as a Nuget package, as Figure 1 shows.
Ease of Use
Alea GPU is easy to use for all kinds of parallel problems. Developers can write GPU code in any .NET language and use the full set of CUDA device functions provided by NVIDIA LibDevice, as well as CUDA device parallel intrinsic functions, such as thread synchrhonization, warp vote functions, warp shuffle functions, and atomic functions. Let’s consider a simple example which applies the same calculation to many data values. SquareKernel is a GPU kernel written in C# that accesses memory on the GPU.
static void SquareKernel(deviceptr outputs,
deviceptr inputs, int n)
{
var start = blockIdx.x * blockDim.x + threadIdx.x;
var stride = gridDim.x * blockDim.x;
for (var i = start; i < n; i += stride)
{
outputs[i] = inputs[i] * inputs[i];
}
}
Alea GPU kernels require no special attribution and have access to the full CUDA semantics. Invoking a CUDA kernel requires configuring the thread block and grid layout, transferring data to device memory, and launching the kernel. The above SquareKernel GPU function can be launched as shown in the following code.
static double[] SquareGPU(double[] inputs)
{
var worker = Worker.Default;
using (var dInputs = worker.Malloc(inputs))
using (var dOutputs = worker.Malloc(inputs.Length))
{
const int blockSize = 256;
var numSm = worker.Device.Attributes.MULTIPROCESSOR_COUNT;
var gridSize = Math.Min(16 * numSm,
Common.divup(inputs.Length, blockSize));
var lp = new LaunchParam(gridSize, blockSize);
worker.Launch(SquareKernel, lp, dOutputs.Ptr, dInputs.Ptr,
inputs.Length);
return dOutputs.Gather();
}
}
When we call worker.Launch, Alea GPU Just-In-Time (JIT) compiles the kernel function SquareKernel, loads it into the worker and executes it on the GPU attached to the worker.
The JIT compilation workflow is extremely flexible. It allows code generation and execution on the fly, enabling GPU scripting and rapid prototyping. JIT compilation is also very useful for application scenarios where the algorithms depend on runtime information. JIT compilation adds a small start-up time overhead and requires deployment of the Alea GPU compiler along with the application.
An alternative is Ahead-Of-Time (AOT) compilation. For kernel functions tagged with the attribute AOTCompile, the Alea GPU compiler generates PTX code at compile time and embeds it into the assembly as a binary resource.
[AOTCompile]
static void SquareKernel(deviceptr outputs,
deviceptr inputs,
int n)
...
AOT compilation saves run-time compilation overhead and simplifies deployment because only the Alea GPU runtime components need to be installed. More details about JIT and AOT compilation can be found in the Alea GPU manual.
Another benefit of GPU development in .NET is that all GPU resources are managed, thus simplifying development and leading to more robust code. For example, all memory objects allocated through a Worker instance are disposable. The using statement
using (var dOutputs = worker.Malloc(inputs.Length))
{
...
}
is a convenient syntax that ensures the correct use of IDisposable objects, providing a clean and safe mechanism for releasing unmanaged resources. You can find more details in the Alea GPU tutorial.
Cross-Platform
Alea GPU is fully cross-platform. The code is compiled on one platform and the resulting assembly is binary compatible with all other platforms. Alea GPU supports Windows, Linux, Mac OS X and is also tested on the ARM based Tegra development kits.
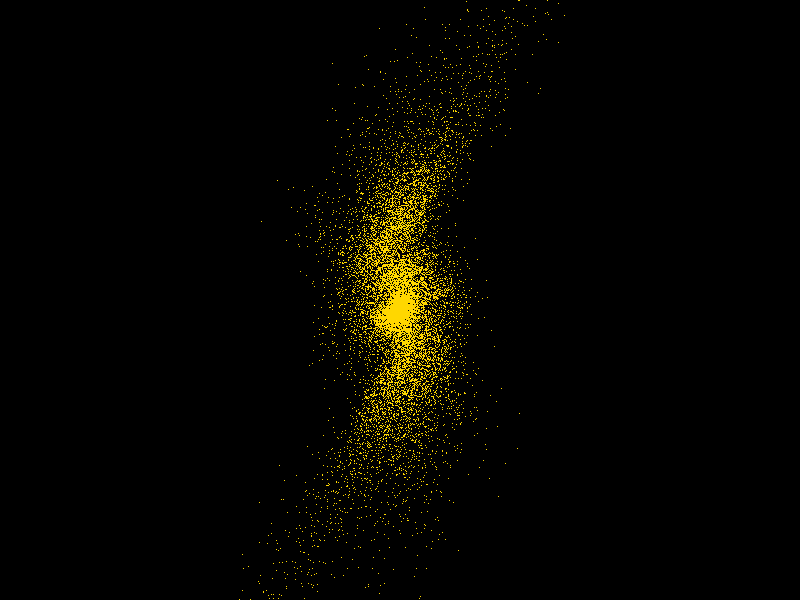
In combination with other .NET libraries, impressive cross-platform GPU-accelerated applications with sophisticated user interfaces or graphics visualization can be developed. The n-body simulation (Figure 2) in the Alea GPU tutorial is an example which uses OpenGL through OpenTK to display the simulation results. Its code base is 100% cross-platform.
An Ecosystem of Algorithms and Libraries
Developing high-performance generic GPU kernels for basic parallel primitives such as scan, reduce, sort or linear algebra codes for parallelized matrix multiplication or linear system solving is challenging and time-consuming.
Alea GPU offers productivity gains in the form of a range of GPU algorithms and integrated libraries such as cuBLAS and cuDNN. These library interfaces are fully type-safe, and library functions can be mixed seamlessly with custom GPU kernels developed in .NET as both rely on the same memory management and data types for GPU memory and GPU pointers.
Full Device-Side Functionality
Alea GPU provides a rich set of device-side functions and advanced CUDA features which are useful for creating sophisticated GPU algorithms, including
- All CUDA intrinisic functions such as
__ballot,__atomic_add, etc.; - The complete set of LibDevice functions;
- Additional useful functions exposed under
LibDeviceEx.
Alea Unbound: CUB Parallel Algorithms in F
Alea GPU is flexible enough to handle complex CUDA code found in some advanced CUDA C++ libraries. A good example is the CUB library of generic GPU parallel algorithm primitives. We have ported a subset of the CUB primitives to .NET using Alea GPU and made them available in Alea Unbound. Here is an example of how to use the device level sum scan primitive in C#:
public static void DeviceScanInclusive()
{
const int numItems = 1000000;
var rng = new Random(42);
var inputs = Enumerable.Range(0, numItems).Select(i => rng.Next(-10, 10)).ToArray();
var gpuScanModule = DeviceSumScanModuleI32.Default;
using (var gpuScan = gpuScanModule.Create(numItems))
using (var dInputs = gpuScanModule.GPUWorker.Malloc(inputs))
using (var dOutputs = gpuScanModule.GPUWorker.Malloc(inputs.Length))
{
gpuScan.InclusiveScan(dInputs.Ptr, dOutputs.Ptr, numItems);
var actual = dOutputs.Gather();
Assert.AreEqual(actual, inputs.ScanInclusive(0, (a, b) => a + b).ToArray());
}
}
The generic scan primitive Primitives.DeviceScanModule expects the binary operator to be used in the scan process as a delegate Func<int, int, int>:
public static void DeviceGenericScanInclusive()
{
const int numItems = 1000000;
var rng = new Random(42);
var inputs = (Enumerable.Repeat(rng, numItems).Select(gen)).ToArray();
Func<int, int, int> scanOp = Math.Max;
using (var gpuScanModule = new Primitives.DeviceScanModule(GPUModuleTarget.DefaultWorker, scanOp))
using (var gpuScan = gpuScanModule.Create(numItems))
using (var dInputs = gpuScanModule.GPUWorker.Malloc(inputs))
using (var dOutputs = gpuScanModule.GPUWorker.Malloc(inputs.Length))
{
gpuScan.InclusiveScan(dInputs.Ptr, dOutputs.Ptr, numItems);
var actual = dOutputs.Gather();
Assert.AreEqual(actual, inputs.ScanInclusive(zero, scanOp).ToArray());
}
}
Following the design of CUB, Alea Unbound has warp, block and device-wide primitives. The warp- and block-wide primitives can be used in kernels as convenient plugin components to write new algorithms. Alea Unbound algorithms deliver the same performance as the CUB CUDA C/C++ counterparts. They are all implemented in F# using warp shuffle or shared memory with union storage for optimal shared memory use.
Besides the primitive algorithms, Alea Unbound also provides fast implementations of matrix multiplication, matrix transpose, random number generators, statistical functions and some linear system solvers.
Debugging and Profiling
Alea GPU provides first class tools for coding, debugging and profiling which are fully integrated into Visual Studio. GPU kernels developed with Alea GPU can be debugged on Windows with the NVIDIA Nsight Visual Studio Debugger.
To support debugging and profiling, Alea GPU has three compilation levels: Optimized, Profiling and Diagnostic:
| Level | Description | Profiling | Debugging |
|---|---|---|---|
| Optimized | No source line information nor variable meta data | No | No |
| Profiling | Source line information but no variable meta data | Yes | No |
| Diagnostic | Source line information and variable meta data | Yes | Yes |
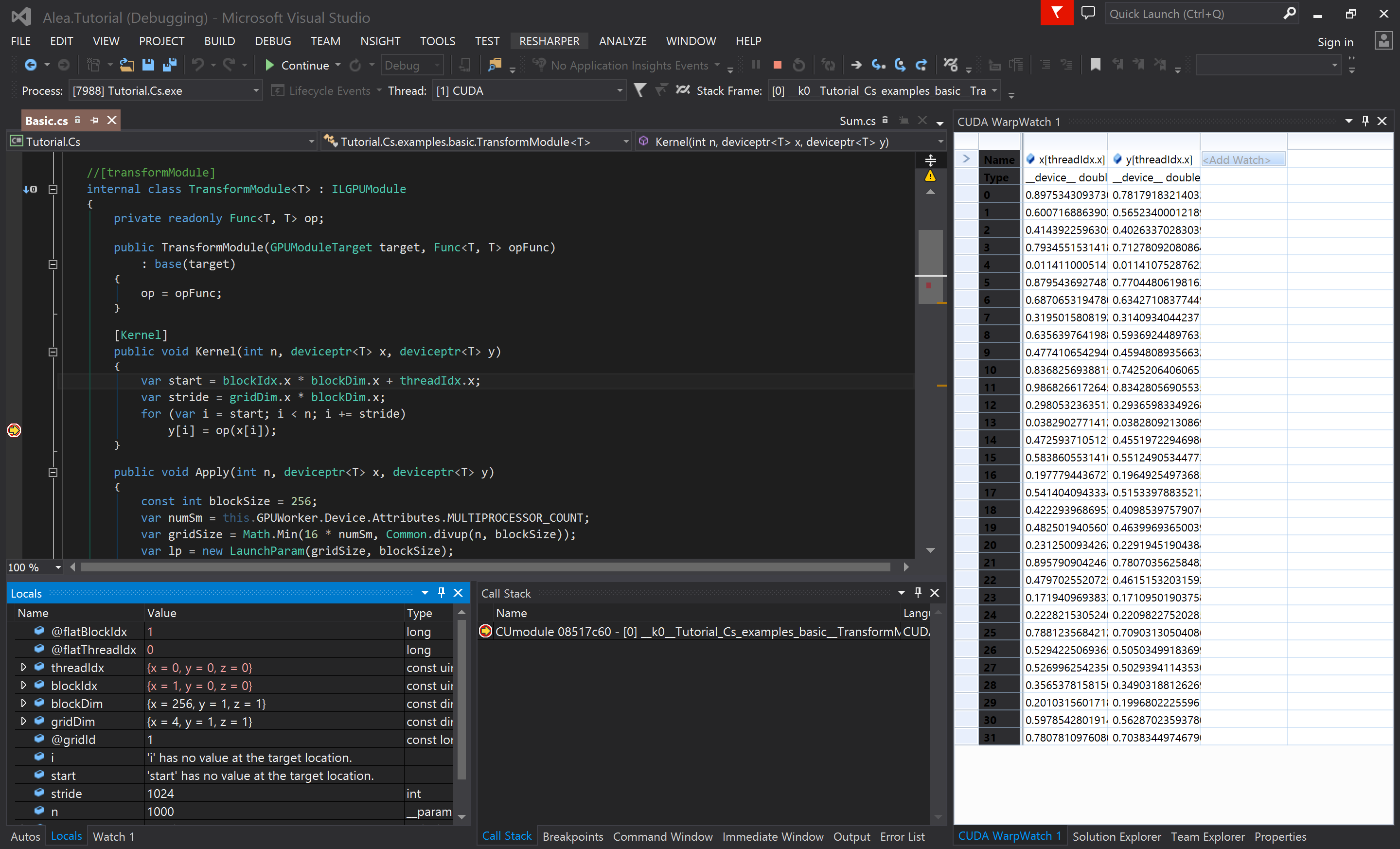
The Nsight Visual Studio debugger allows breakpoints to be directly set in Alea GPU source code even in F# code quotations. The full range of standard debugging features are available such as memory inspection, local variable values and memory checks, as Figure 3 shows. Debugging functionality is based upon LLVM debug meta information which is generated by Alea GPU.
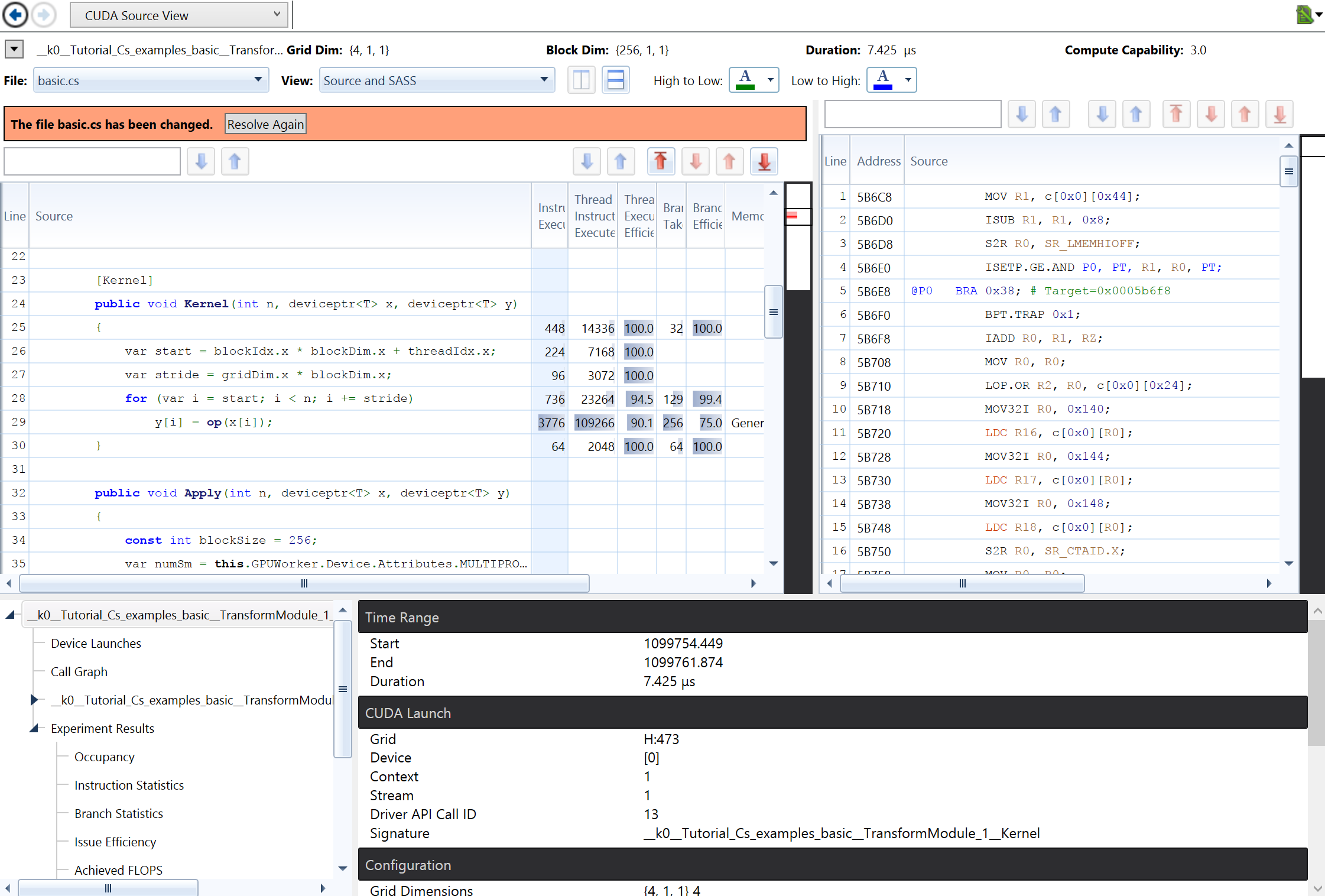
The compilation level Profiling also supports source code correlation, as Figure 4 shows.
The Alea GPU tutorial has detailed explanations about how to debug and profile GPU-accelerated .NET applications.
GPU Scripting
Developing GPU algorithms is often an iterative process. Usually many variations have to be explored to fine-tune the algorithm. GPU scripting and rapid prototyping greatly improve productivity and encourage the developer to thoroughly investigate the efficiency of the code.
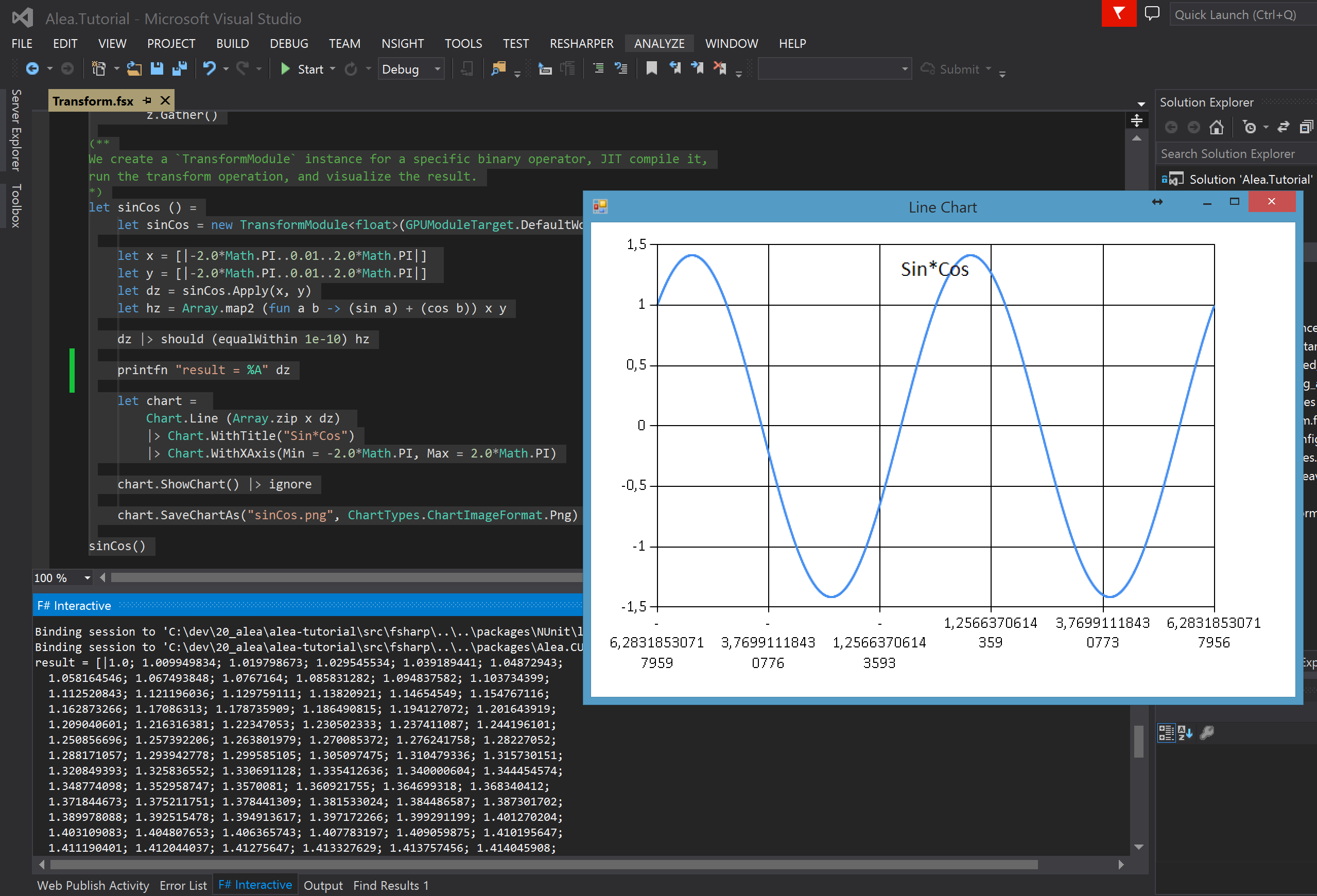
Alea GPU is the only solution that can deliver GPU scripting and a REPL in Visual Studio for interactive prototyping of GPU code. F# code can be directly sent to the F# interactive console for execution. The JIT compilation mode of Alea GPU allows for the execution of F# GPU code on the fly in the F# interactive console, as Figure 5 shows.
GPU code can also be embedded in F# scripts which are then executed with fsi.exe as ordinary scripts on the console.
Advanced GPU Coding with Full CUDA Flexibility
The example above illustrates the most basic usage of Alea GPU. It uses plain functions or methods for GPU code and a separate function for memory management and kernel execution and is therefore very well-suited for simple applications. For more complex problems Alea GPU offers two alternatives: Class instances and Workflows.
Class Instances
Class instances use a class derived from GPUModule or ILGPUModule to manage all GPU resources. CUDA compile-time arguments can be supplied to the constructor. This allows for the creation of advanced kernels using generics, such as the following example generic map kernel.
internal class TransformModule : ILGPUModule
{
private readonly Func<T, T> op;
public TransformModule(GPUModuleTarget target,
Func<T, T> opFunc)
: base(target)
{
op = opFunc;
}
[Kernel]
public void Kernel(int n, deviceptr<T> x, deviceptr<T> y)
{
var start = blockIdx.x * blockDim.x + threadIdx.x;
var stride = gridDim.x * blockDim.x;
for (var i = start; i < n; i += stride)
y[i] = op(x[i]);
}
...
}
Workflows
Workflows specify all GPU resources and kernels in composable cuda {...}workflow blocks. This exposes the full expressive power of Alea GPU and is very well suited for scripting. This feature is only available in F#.
let template (transform:Expr<int -> int -> int>) = cuda {
let! kernel =
<@ fun (z:deviceptr<int>) (x:deviceptr<int>)
(y:deviceptr<int>) (n:int) ->
let start = blockIdx.x * blockDim.x + threadIdx.x
let stride = gridDim.x * blockDim.x
let mutable i = start
while i < n do
z.[i] <- (%transform) x.[i] y.[i]
i <- i + stride @>
|> Compiler.DefineKernel
return Entry(fun program ->
let worker = program.Worker
let kernel = program.Apply kernel
let lp = LaunchParam(16, 256)
let run (x:int[]) (y:int[]) =
let n = inputs1.Length
use x = worker.Malloc(x)
use y = worker.Malloc(y)
use z = worker.Malloc(n)
kernel.Launch lp z.Ptr x.Ptr y.Ptr n
outputs.Gather()
run) }
You can find more details about the programming approaches that Alea GPU supports in the Alea GPU tutorial.
Future-Oriented Technology
Alea GPU is a complete compiler built on top of the popular LLVM compiler infrastructure and the NVIDIA CUDA compiler SDK. Code compiled with Alea GPU delivers the same performance as equivalent CUDA C/C++ or CUDA Fortran. Alea GPU takes advantage of the code optimization passes in LLVM as well as the GPU-specific optimizations provided in the NVIDIA NVVM compiler back-end.
Get Started with Alea GPU Today!
Sign up for a free Alea GPU hands-on webinar hosted by NVIDIA on July 8, 2015.
Alea GPU contains individual packages which can be conveniently installed through NuGet. The deployment package Alea.CUDA.Fody installs the necessary compilers together with the ahead-of-time compilation tool.
To install Alea GPU, run the following command in the
Package Manager Console:
PM> Install-Package Alea.CUDA.Fody
Alea GPU requires a CUDA-capable GPU with compute capability 2.0 (Fermi architecture) or higher and an installed CUDA driver version 6.5 or higher.
Finally you need a Alea GPU license. The community edition is free and supports consumer GPUs of the GeForce product line. Register on the QuantAlea web page, select Client Login and sign up to retrieve a free community edition license. For applications which require enterprise hardware or mobile GPUs QuantAlea provides commercial licenses.
Your Feedback
We are interested to hear all of your feedback and suggestions for Alea GPU. Write to us at info@quantalea.com or @QuantAlea on Twitter.