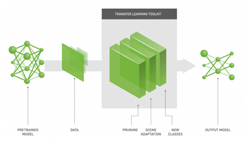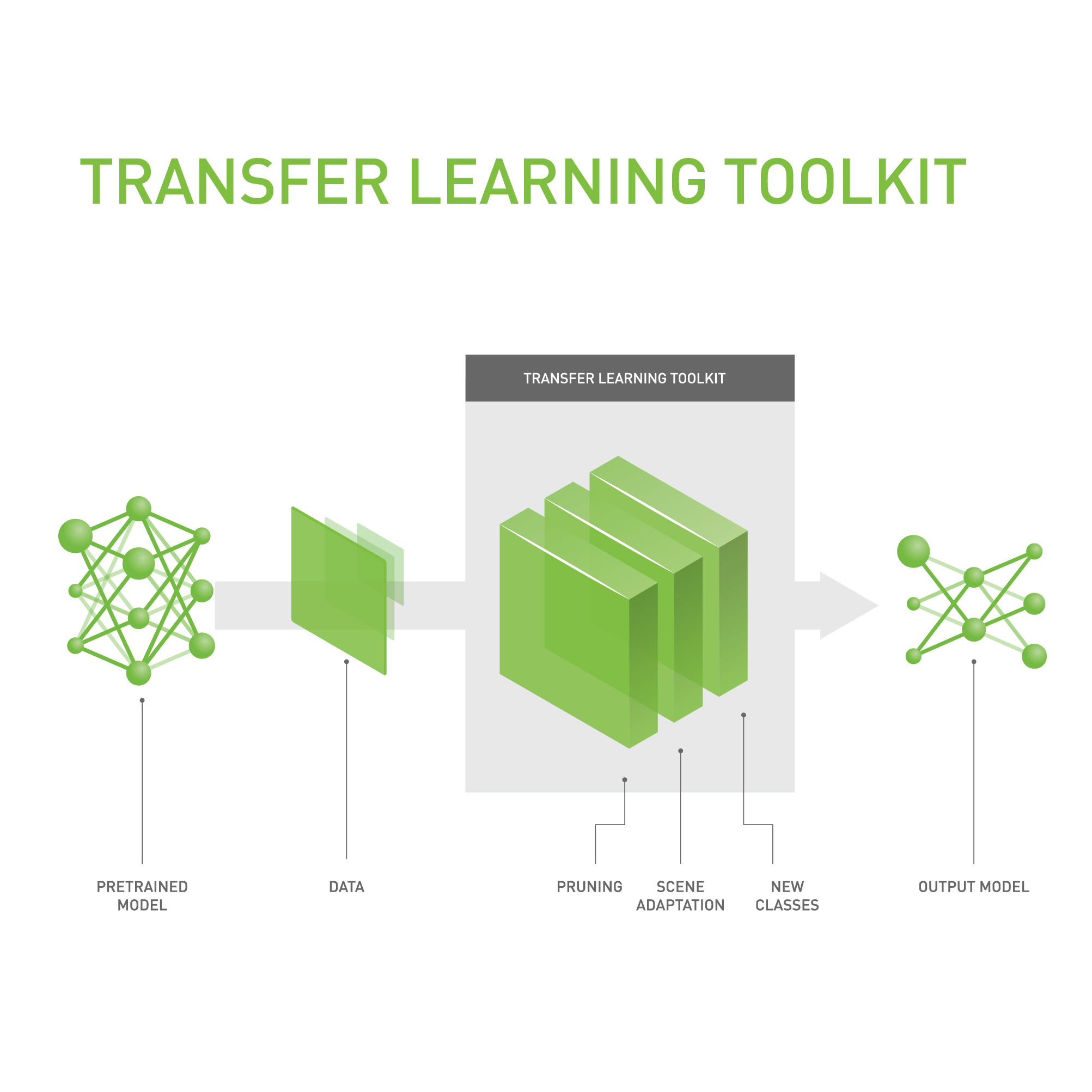

Over the past several years, NVIDIA has been developing solutions to make AI and its benefits accessible to every industry. NVIDIA Transfer Learning Toolkit specifically allows developers looking into faster implementation of Intelligent Video Analytics (IVA) systems use deep learning and take their application from prototype to production in the fastest and most efficient way.
Neural networks gain knowledge by learning from data compiled as “weights” within the neural network. Instead of training newer neural networks from scratch, you can transfer the features learned earlier by extracting these weights and transferring them to another neural network. This is known as transfer learning. Some amount of transfer learning is needed even with optimized, pre-trained models. This happens because certain applications require learning specifics of an image. Examples include differences in light settings when the image was captured or changes in viewing angle. Sensor adaptation is widely recognized as a transfer learning technique in computer vision applications.
Developers wanting acceleration of their deep learning application development can use, pre-trained deep learning models such as ResNet-10, ResNet-18, ResNet-50, GoogLeNet, VGG-16 and VGG-19 as a basis for adapting to their custom dataset. They can incrementally retrain the model with the help of the Transfer Learning Toolkit for object detection and image classification use cases.
NVIDIA Transfer Learning Toolkit uses a simple command line user interface to enable users to fine tune pre-trained networks with their own data and also offers capabilities such as pruning models, scene adaptation and adding new classes for a faster deep learning training workflow and also allows export to NVIDIA TensorRT-based inference. Transfer Learning Toolkit provides multi-GPU support; your application can be deployed on a GPU-accelerated platform in your datacenter, in the cloud, on premises, or on a local workstation for further use with NVIDIA DeepStream SDK 3.0 plugins.
Transfer Learning Toolkit for Intelligent Video Analytics (IVA)
Developers working on any IVA application such as parking management, securing critical infrastructure, retail analytics, logistics management, and access control can benefit from using Transfer Learning Toolkit with NVIDIA DeepStream SDK 3.0 for faster and efficient deep learning inference for IVA use cases.
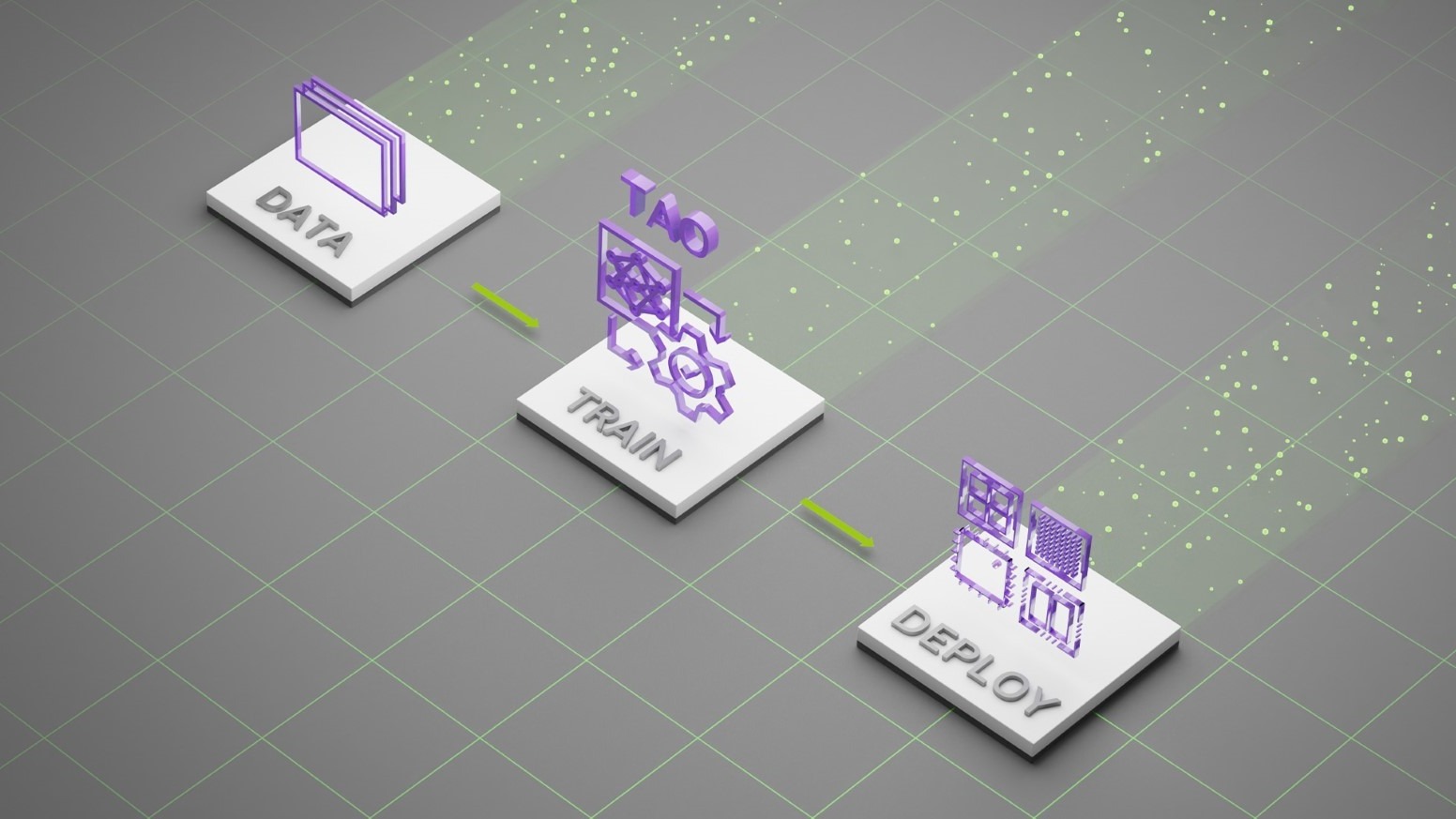
The flow diagram in Figure 1 shows how NVIDIA enables step-by-step transfer learning for pre-trained models with an end to end deep learning workflow for IVA application developers. After downloading the docker container, list and pull commands allow users to see which models are provided and obtain directly from the model registry on NGC. Jupyter notebooks show example workflow, guidance on how to get started is provided in a getting started document included in the container. Training with user data involves specifying where data is located. Conversion tools are provided to help users prepare data for input.
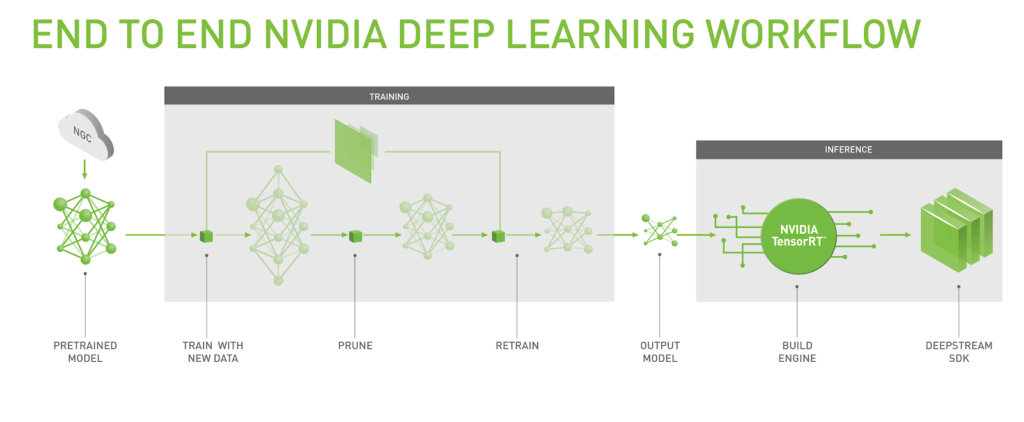
The memory footprint of models needs to be compact for computer vision use cases. These models deploy to edge devices that support fast inference through DeepStream SDK and TensorRT. Multiple video stream channels are important, so smaller model size enables the use of more simultaneous channels. Reducing size also results in faster inference time. Hence “pruning” models is an essential step in the end to end workflow. NVIDIA uses a patented pruning technology that helps with model compression, enabling smaller models which provide faster inference on Tesla platforms. Some accuracy loss may occur after pruning, requiring retraining to recover loss.
Transfer Learning Toolkit uses Keras TensorFlow framework under the hood to develop and process models. The easy to use interface enables even developers who are not familiar with deep learning frameworks to quickly develop applications. Transfer Learning Toolkit makes it easy to prune and retrain models. The high level APIs abstract away details, allowing developers to focus on their application development rather than algorithms.
Using Transfer Learning Toolkit Features
Let’s quickly walk through key Transfer Learning Toolkit features. Nine image classification and detection models come prepackaged with Transfer Learning Toolkit and include networks which have been trained on publicly available datasets. Object detection models use detection technology developed at NVIDIA. Each model is optimized and trained on Pascal, Volta, and Turing GPUs to achieve highest accuracy levels.
Image Classification
- ResNet18
- ResNet50
- VGG16
- VGG19
- AlexNet
- GoogLeNet
Object Detection
- ResNet50
- VGG16
- GoogLeNet
Let’s look at a reference application of how to use Transfer Learning Toolkit features such as retrain, adapt, and prune for a resnet50 4 class object detector
Step 1: Download the Model
Use the List command to see available models. Use pull command to get the model; add the version argument. NVIDIA will be updating the models and versioning them so that users have access to the latest optimization.
tlt-pull --list_models -k <NGC API Key>
tlt-pull --list_version --model_name $MODEL_NAME -k $API_KEY
tlt-pull --model_name $MODEL_NAME --version $VERSION -k $API_KEY --dir ./path/to/save/model
Download times vary depending on the network speed.
Step 2: Training the model
Pretrained models for object detection work with a dataset in kitti file format. TLT provides a dataset converter from kitti to TFRecords.; TFRecords help iterate faster through the data.
Users can bring their kitti format datasets and use the converter to convert them to TFRecords
tlt-dataset-convert [-h] -d DATASET_EXPORT_SPEC -o OUTPUT_FILENAME [-f VALIDATION_FOLD] [-v]
Model input requirements for a detection network include:
- Input size: 3 x W x H, where W ≥ 480, H ≥ 272, and W and H are multiples of 16; (if using pretrained weights, the input size should be 3 x 1248 x 384)
- Image format: JPG, JPEG, PNG
- Label format: KITTI detection
Adaptive global tone-mapping and static white balance have been applied in advance. The model output is a horizontal boundary with associated labels such as car, bicycle, person, and road sign. All correspond to an image of size of 3 x 960 x 544 and confidence of detection.
Training a model from scratch involves multiple iterations and experimentation. Having pretrained models available reduces the number of iterations and compute resources required to fine-tune the model. A training specification file helps make it easier to specify parameters. Let’s look at a sample config file.
sample_spec.cfg
random_seed: 42
model_config {
arch: "resnet",
n_layers: 50
input_image_size: "3,960,544"
}
train_config {
train_dataset_path: "./dataset_train"
val_dataset_path: "./dataset_val"
pretrained_model_path: "./tlt_pretrained_model/resnet50.hdf5"
batch_size_per_gpu: 64
n_epochs: 15
n_workers: 16
step_size: 10
learning_rate: 0.01
weight_decay: 0.00005
gamma: 0.1
}
Users simply update the dataset path to their location and execute simple commands to train the model. Transfer Learning Toolkit supports single and multi-GPU training.
tlt-train [-h] detection --gpus <num GPUs> -k <encoding key> -r <result directory> [-e SPEC_FILE] [-v]
tlt-train classification -e sample_spec -r outdir -k <NGC API Key> --gpus 4
tlt-train {classification, detection} --gpus<num GPUs>
Training parameters used for initial training include batch size and learning rate, among others.
You should experiment with different hyperparameter values to retrain the pretrained model, lowering learning_rate to 1e-5. Increasing batch_size to 32 may lead to improved accuracy.
Note on Multi GPU training at scale
Training with more GPUs allows networks to ingest more data faster, saving precious time during the development process. Transfer Learning Toolkit supports multi-GPU training so users can train the model with several GPUs in parallel. This feature is also helpful for hyper-parameter optimization.
Step 3: Evaluating the Trained Model
Model evaluation using common metrics is carried out using the evaluate command:
tlt-evaluate detection [-h] [-e EXPERIMENT_SPEC_FILE] -m MODEL_FILE -k KEY [–use_training_set] [-v]
tlt-evaluate classification -d dataset_val -pm outdir/weights/resnet_015.hdf5 -b 32
Sample output of evaluation for Object Detection task is shown below.
2018-11-06 01:05:44,920 [INFO] tensorflow: loss = 0.05362146, epoch = 0.0663716814159292, step = 15 (5.978 sec)
INFO:tensorflow:global_step/sec: 0.555544
..
=========== ====== ====== ======
class mAP easy hard mdrt
=========== ====== ====== ======
car 91.06 84.50 84.50
cyclist 0.00 7.70 7.70
pedestrian 0.00 0.00 0.00
=========== ====== ====== ======
Sample output of evaluation for classification task looks like the output shown in figure 1.

Step 4: Model Pruning & Retraining
Pruning reduces the number of parameters by an order of magnitude, leading to a model that runs many times faster. Pruning refers to removing unnecessary neuron connections reducing the memory needed to store parameters by 25% or more.
Pruning has shown to increase the throughput for video frames in IVA applications. One study found that the ResNet-50 four class detector ran at 30 frames per second , 3x the throughput of the model which was not pruned and not GPU optimized. This occurs because the pruning API can reduce size of a model by 6 times without sacrificing accuracy. After pruning, the model needs to be retrained to recover accuracy since some useful connections may have been removed during pruning.
tlt-train detection -e retrain_spec.cfg -r outdir_retrain
OR
tlt-train classification -e $DATA_DIR/retrain_spec.cfg -r $RETRAIN_OUTPUT_DIR
Add the pretrained model file path in retrain_spec.cfg by modifying this line:
pretrained_model_path: "OUTPUT_DIR/weights/resnet_50.hdf5"
Step 5: Model Export
Once the adaptation completes, the model can be exported to a format usable by the DeepStream SDK such as the universal file format (uff). A small utility called TLT converter is included. The converter takes a model that was exported in the TLT docker using tlt-export and converts it to a TensorRT engine. Optionally, the export creates a calibration cache file to perform int8 TensorRT engine calibration during the conversion. The exported uff model is data type agnostic because TensorRT optimizes data types when the engine is built. Export only generates the calibration cache in int8 mode. The model exporter is a combination of multiple export functions.
Example of basic usage for fp16 and fp32 data types, no calibration cache generated:
tlt-export [-h] [-k KEY]
[-o OUTPUT_FILE]
[--outputs OUTPUTS]
[--data_type {fp32,fp16,int8}]
[-v]
input_file
Supported data_types include: FP16, FP32 or INT8 and maximum batch size and maximum workspace size can be specified on the command line. Model calibration can be performed based on a calibration data file for the INT8 engine.
tlt-export $RETRAIN_OUTPUT_DIR/weights/resnet_50.hdf5 -f uff --parser uff -o $EXPORT_DIR/resnet_50.uff -k $API_KEY
NVIDIA is continuously building developer tools to make AI and deep learning easy to use and deployable for developers who are building innovative solutions to bring unique experiences to their end users. Get faster to the market with NVIDIA Transfer Learning Toolkit. Apply to the Transfer Learning Toolkit early access program to get started with accelerating your IVA based end application.