For the last eleven years, NVIDIA’s CUDA development platform has unleashed the power of GPUs for general purpose processing in a wide variety of applications. These include: high performance computing (HPC), data center applications, and content creation workflows. Most recently, artificial intelligence systems and applications ranging from embedded systems to the cloud have benefited from high-performance GPUs.
CUDA 10, announced at SIGGRAPH 2018 alongside the new Turing GPU architecture, is now generally available for all NVIDIA GPU developers. The enhanced APIs and SDKs tap the power of new Turing GPUs, enable scaled up NVLINK-powered GPU systems, and provide benefits to CUDA software deployed on existing systems. This post gives an overview of the major features in the release:
- Support for the Turing GPU architecture, including the new NVIDIA Tesla T4 GPU for hyperscale data centers, multi-GPU systems with the NVSwitch fabric such as the DGX-2 and HGX-2, and Drive AGX Pegasus and Jetson AGX Xavier, the AI platform for autonomous cars and autonomous machines
- A new asynchronous task-graph programming model in CUDA which enables more efficient launch and execution
- Performance optimizations in CUDA libraries for FFTs, linear algebra, and matrix multiplication
- A new Nsight product family of tools for tracing, profiling, and debugging of CUDA applications
- Expanded developer platform and host compiler support for the major operating systems and compiler toolchains
- CUDA compatibility packages, available on enterprise Tesla systems, which allow users to access features from newer versions of CUDA without requiring a kernel driver update
You can download the CUDA Toolkit 10 today. We will be publishing blog posts over the next few weeks covering some of the major features in greater depth than this overview. But for now, let’s begin our tour of CUDA 10.
CUDA and Turing GPUs
CUDA 10 is the first version of CUDA to support the new NVIDIA Turing architecture. Turing’s new Streaming Multiprocessor (SM) builds on the Volta GV100 architecture and achieves 50% improvement in delivered performance per CUDA Core compared to the previous Pascal generation. Similar to Volta, the Turing SM provides independent floating-point and integer data paths, allowing a more efficient execution of workloads with a mix of computation and address calculations. The redesigned SM memory hierarchy results in 2x more bandwidth and more than doubles the L1 cache capacity available for compute workloads, relative to Pascal. For more in-depth information on the Turing architecture, read the NVIDIA Turing architecture whitepaper.
Turing GPUs also inherit all the enhancements to CUDA introduced in the Volta architecture that improve the capability, flexibility, productivity, and portability of compute applications. Features such as independent thread scheduling, hardware-accelerated Multi-Process Service (MPS) with address space isolation for multiple applications, and Cooperative Groups are all part of the Turing GPU architecture. CUDA’s binary compatibility guarantee means that applications that are compiled for Volta’s compute capability (7.0), will run on Turing (with a compute capability of 7.5) without any need for offline or just-in-time recompilation.
In the next few sections, let’s look at the major innovations introduced in Turing and how CUDA 10 enables developers to take advantage of these capabilities.
Deep Learning Inference using Multi-Precision Tensor Cores
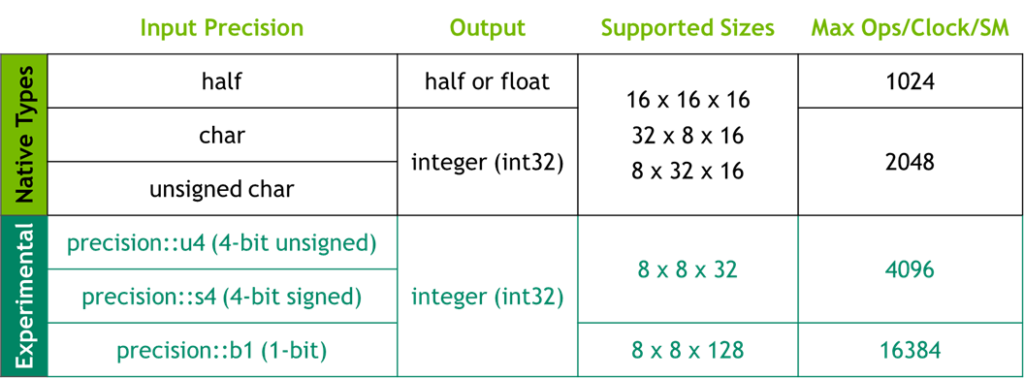
Turing includes Tensor Cores, which are specialized hardware units designed for performing mixed precision matrix computations commonly used in deep learning neural network training and inference applications. In addition to the FP16/FP32 modes, Turing adds new INT8 and INT4 precision modes for inferencing workloads that don’t require FP16 precision. These new modes provide higher math throughput and more efficient bandwidth utilization, offering a substantial increase in performance. In addition, Turing adds experimental support for Tensor Cores with 4-bit and 1-bit precision to enable researchers to learn and experiment with ultra-low precision math for deep learning inference.
Each Tensor Core operates on a 4×4 matrix and performs the operation D=A*B+C, where A, B, C and D are 4×4 matrices. The matrix multiply inputs A and B are FP16 matrices, while the accumulation matrices C and D may be FP16 or FP32 matrices as shown in Figure 1.

In Turing, each Tensor Core can perform up to 64 floating point fused multiply-add (FMA) operations per clock using FP16 inputs. Eight Tensor Cores in an SM perform a total of 512 FP16 multiply and accumulate operations per clock, or 1024 total FP operations per clock. The new INT8 precision mode works at double this rate, or 2048 integer operations per clock, as shown in Figure 2.
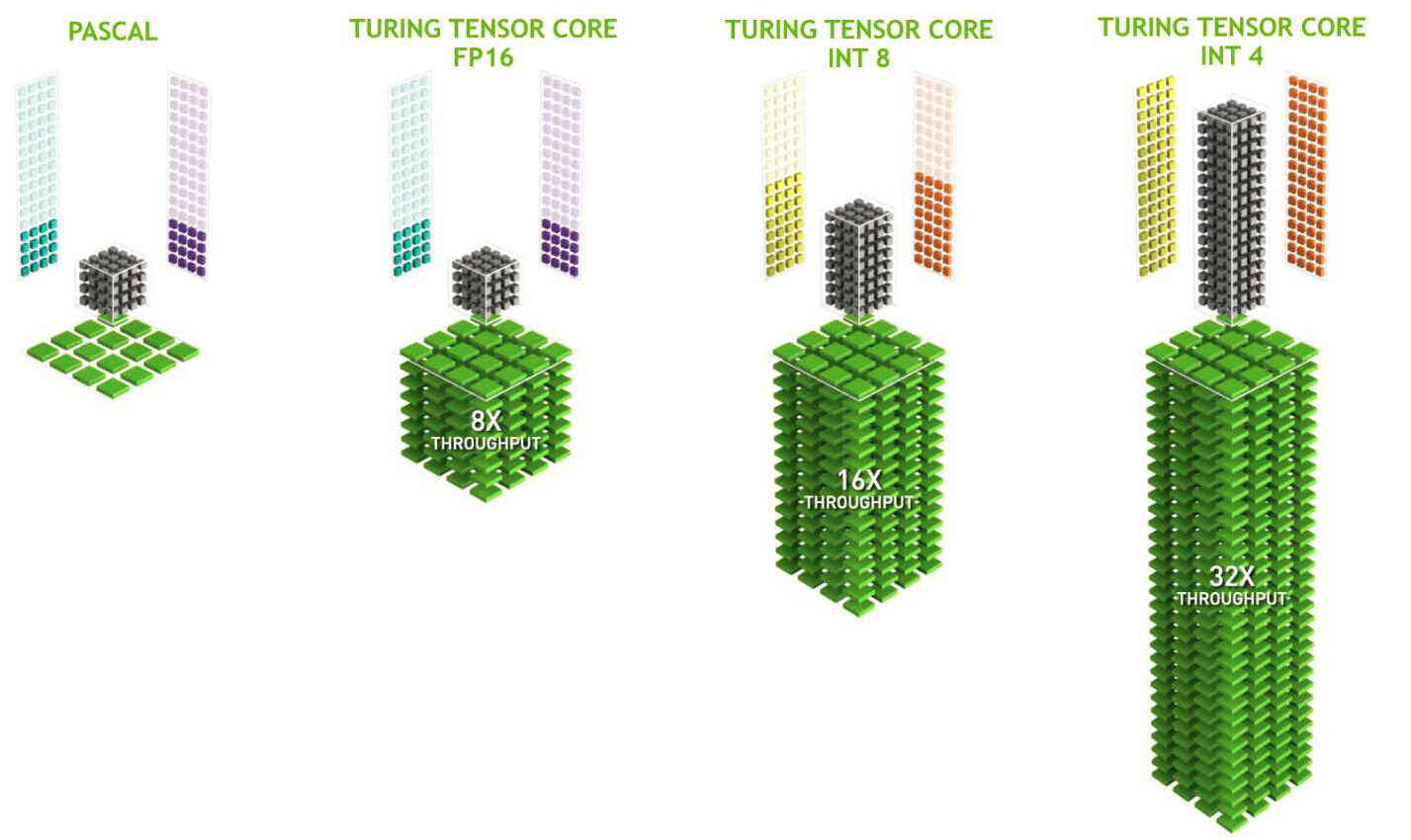
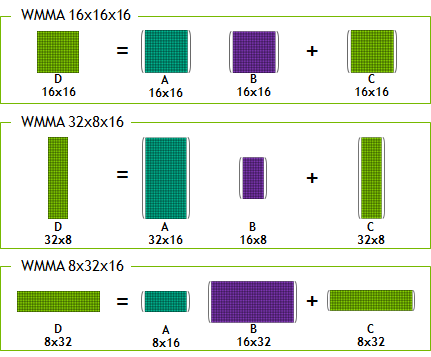
Programmers access Tensor Cores through CUDA libraries, TensorRT and different deep learning frameworks. CUDA C++ makes Tensor Cores available via the Warp-Level Matrix Operations (WMMA) API. This API exposes specialized matrix load, matrix multiply and accumulate, and matrix store operations to efficiently use Tensor Cores from a CUDA-C++ program, as you can see in Figure 3. At the CUDA level, the warp-level interface addresses 16×16, 32×8 and 8×32 size matrices by spanning all 32 threads of the warp. All functions and data types for WMMA are available in the nvcuda::wmma namespace.
CUDA 10 on Turing enables WMMA support for INT8 (both signed and unsigned) with 32-bit integer accumulation. In addition, CUDA 10 provides experimental sub-byte data types for use with WMMA as a way to access the INT4 and binary capabilities of the Tensor Cores. You access these via the nvcuda::wmma::experimental namespace. This functionality is an experimental feature to enable deep learning research with ultra low-precision. The Binary Tensor Cores can provide 16,384 binary operations per clock.
namespace experimental { namespace precision { struct u4; // 4-bit unsigned struct s4; // 4-bit signed struct b1; // 1-bit } enum bmmaBitOp { bmmaBitOpXOR = 1 }; enum bmmaAccumulateOp { bmmaAccumulateOpPOPC = 1 }; }
More information on WMMA can be found in the CUDA Programming Guide and the blog post. Figure 4 displays a matrix of supported data types, configurations and performance.
Implementations of matrix multiplication (GEMM) for Turing using the WMMA APIs described above are also available in CUTLASS as part of its v1.1 release. Check out the CUTLASS release on GitHub.
CUDA 10 offers a unified software architecture, ranging from Tegra embedded products up through the Tesla data center products. Support for Tensor Cores scales from Xavier all the way to Turing.
Ray Tracing Acceleration
Turing’s new RT Cores accelerate ray tracing and enable a single GPU to render visually realistic 3D games and complex professional models with physically accurate shadows, reflections, and refractions. RT Cores accelerate Bounding Volume Hierarchy (BVH) traversal and ray/triangle intersection testing (ray casting) functions. Developers can use NVIDIA’s OptiX ray tracing engine and APIs with CUDA to access the RT Cores for accelerating these functions.
Windows Peer-to-Peer
CUDA 10 now supports peer-to-peer communication between GPUs in Windows 10 with Windows Display Driver Model 2.0. Since Turing GPUs (TU102 and TU104) incorporate NVLink between pairs of GPUs, these two features together enable new possibilities for applications on Windows. NVLink provides peer-to-peer atomics and much higher bandwidth between GPUs. For large memory workloads, including professional ray tracing applications, scene data can be split across the frame buffer of both GPUs and memory requests are automatically routed by hardware to the correct GPU based on the location of the physical memory.
CUDA Graphs
Many HPC applications such as deep neural network training and scientific simulations have an iterative structure where the same workflow is executed repeatedly. CUDA streams require that the work be resubmitted with every iteration, which consumes both time and CPU resources. Graphs present a new model for submitting work using CUDA. A graph consists of a series of operations, such as memory copies and kernel launches, connected by dependencies and defined separately from its execution. Graphs enable a define-once-run-repeatedly execution flow.
For GPU kernels with short runtimes, the overhead of a kernel launch can be a significant fraction of the overall end-to-end execution time. Separating out the definition of a graph from its execution reduces CPU kernel launch costs and can make a significant performance difference in such cases. Graphs also enable the CUDA driver to perform a number of optimizations because the whole workflow is visible, including execution, data movement, and synchronization interactions, improving execution performance in a variety of cases (depending on the workload).
CUDA operations form the nodes of a graph, with the edges being the dependencies between the operations. The nodes of a graph can be kernel launches, memory copies, CPU function calls, or graphs themselves. Figure 5 outlines an example of how this might look with a four-node graph. The code sample below shows how this might be written.
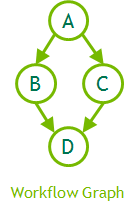
// Define graph of work + dependencies cudaGraphCreate(&graph); cudaGraphAddNode(graph, kernel_a, {}, ...); cudaGraphAddNode(graph, kernel_b, { kernel_a }, ...); cudaGraphAddNode(graph, kernel_c, { kernel_a }, ...); cudaGraphAddNode(graph, kernel_d, { kernel_b, kernel_c }, ...); // Instantiate graph and apply optimizations cudaGraphInstantiate(&instance, graph); // Launch executable graph 100 times for(int i=0; i<100; i++) cudaGraphLaunch(instance, stream);
While CUDA 10 includes explicit APIs for creating graphs, graphs can also be captured from existing stream-based APIs as shown in Figure 6, along with some example code which generate the graph. Although all stream work can be mapped to a graph, the two programming models suit different needs and use-cases and are meant to be complementary.
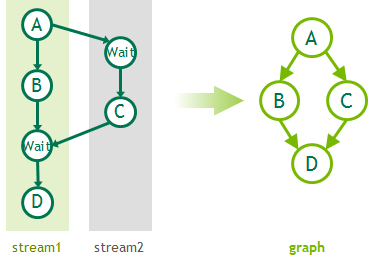
// Start by initating stream capture cudaStreamBeginCapture(stream1); // Build stream work as usual A<<< ..., stream1 >>>(); cudaEventRecord(e1, stream1); B<<< ..., stream1 >>>(); cudaStreamWaitEvent(stream2, e1); C<<< ..., stream2 >>>(); cudaEventRecord(e2, stream2); cudaStreamWaitEvent(stream1, e2); D<<< ..., stream1 >>>(); // Now convert the stream to a graph cudaStreamEndCapture(stream1, &graph);
Refer to the CUDA Programming Guide for more information on using the graph APIs. CUDA developer tools such as Nsight Compute allow debugging and profiling of applications using graph APIs, including exporting of graphs for use with visualization tools.
CUDA Graphics Interoperability
Many professional workstation and gaming applications use a graphics API such as OpenGL or DirectX for rendering 3D graphics and a compute API such as CUDA for computational work. Some examples of these interactions include
- Scientific computations in CUDA which produce vertex buffers for visualization
- Image frames generated by the graphics API which require processing by CUDA e.g. deep learning inference, computational photography, transcoding
- Procedural content generation in games and visual media by CUDA which is then consumed by graphics APIs
Resources must be shared to avoid excessive memory usage for interoperability between these APIs to be effective. CUDA has long supported interoperability with OpenGL and Microsoft’s DirectX (9, 10, 11). CUDA 10 introduces interoperability with Vulkan and DirectX 12 APIs, allowing applications using these APIs to take advantage of the rich feature set provided by CUDA. Vulkan is a cross-platform, low-level graphics API that minimizes the driver’s CPU overhead typically associated with APIs like OpenGL. DirectX 12 (DX12) provides a similar set of features on Windows. Both Vulkan and DX12 allow the application to exercise tight control over GPU resource management and work scheduling.
CUDA 10 introduces new data types to encapsulate memory allocations (cudaExternalMemory_t) and semaphores (cudaExternalSemaphore_t) imported from Vulkan. APIs are provided to import memory allocated by Vulkan (cudaImportExternalMemory) and to directly map buffers or CUDA mipmapped arrays. Figure 7 shows the interfaces between these APIs.
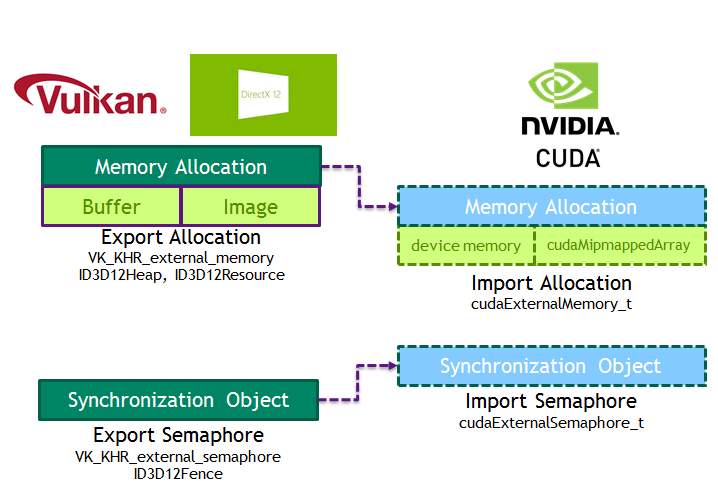
Refer to the CUDA Runtime API documentation on External Resource Interoperability for more information. CUDA 10 also includes a sample to showcase interoperability between CUDA and Vulkan.
CUDA Compiler and Language Improvements
CUDA 10 includes a number of changes for half-precision data types (half and half2) in CUDA C++. CUDA 9 added support for half as a built-in arithmetic type, similar to float and double. CUDA 10 builds on this capability and adds support for volatile assignment operators, and native vector arithmetic operators for the half2 data type to increase performance in device code. The half precision conversion intrinsics (e.g. float2half) are now supported from within host functions. Additionally half C++ casts, constructors and assignment operators, previously device-only, are now also available from host code. CUDA 10 also supports atomicAdd operations on both the half and half2 types. Figure 8 summarizes the changes with some examples. See the CUDA Programming Guide and CUDA Math API for more details on the available functions.

CUDA 10 adds host compiler support for latest versions of Clang (6.x), ICC (18), Xcode (9.4) and Visual Studio 2017. A full list of supported compilers is available in the documentation on system requirements.
NVIDIA has worked closely with Microsoft on improving the compatibility of nvcc with the Visual Studio 2017 updates to provide a better experience for our developers. Visual Studio now ships more frequent minor updates every six weeks. The last minor update to Visual Studio 2017 (15.8) released in August 2018. Starting with CUDA 10, nvcc supports all updates (past and upcoming) to Visual Studio 2017. This means CUDA developers on Windows can easily update or migrate between Visual Studio 2017 versions.
CUDA Compatibility
Since CUDA 9, CUDA has transitioned to a faster release cadence to deliver more features, performance improvements, and critical bug fixes. The tight coupling of the CUDA runtime with the NVIDIA display driver requires customers to update the NVIDIA driver in order to use the latest CUDA software, such as compiler, libraries, and tools. This package introduces a new CUDA compatibility package on Linux cuda-compat-<toolkit-version>, available on enterprise Tesla systems. CUDA compatibility allows customers to access features from newer versions of CUDA without requiring a full NVIDIA driver update. More details on CUDA compatibility and deployment will be published in a future post.
CUDA Libraries
The CUDA toolkit includes GPU-accelerated libraries for linear algebra, image and signal processing, direct solvers, and general math functions. CUDA libraries offer significant performance advantages over multi-core CPU alternatives. Thanks to their drop-in interfaces, you can use these libraries with minimal or no code changes.
Let’s take a look at what’s new in CUDA 10 libraries.
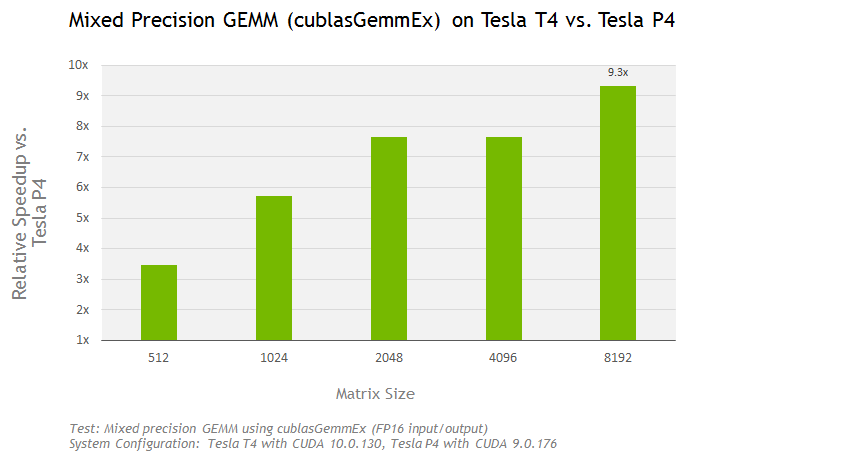
Turing architecture support: cuBLAS 10 includes Turing optimized mixed-precision GEMMs (matrix-matrix multiplications) which take advantage of the Tensor Cores when using the GEMM APIs. Thanks to Tensor Cores, using the cublasGemmEx API on the Tesla T4 with CUDA 10 achieves a speedup of up to 9x compared to the Tesla P4 as shown in Figure 9.
Other CUDA libraries have also been optimized for out-of-the-box performance on the Turing architecture. A more detailed performance report on CUDA 10 libraries will be available soon.
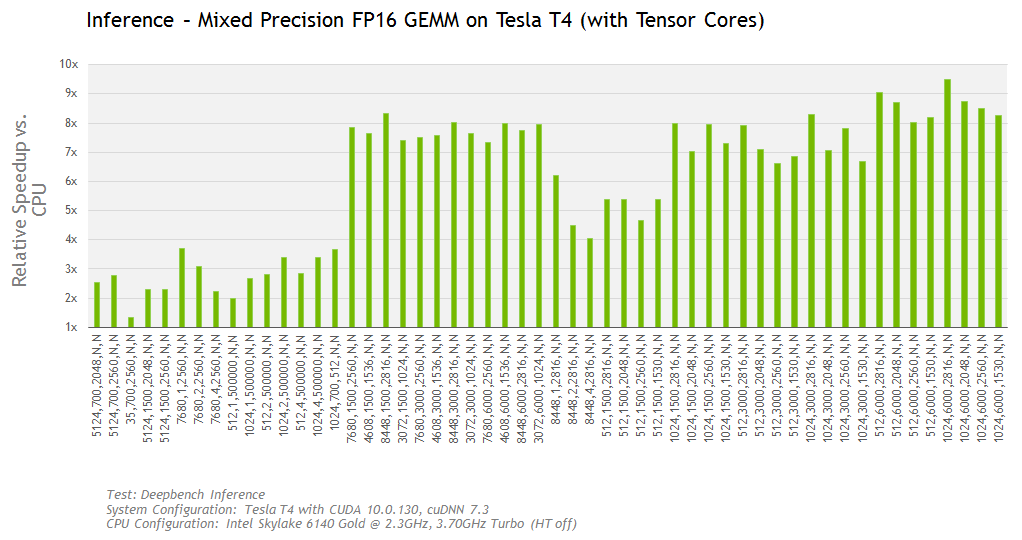
The Tesla T4 can achieves up to 9.5x (or up to 28TF) compared to an Intel CPU on the DeepBench inference test, as shown in Figure 10.
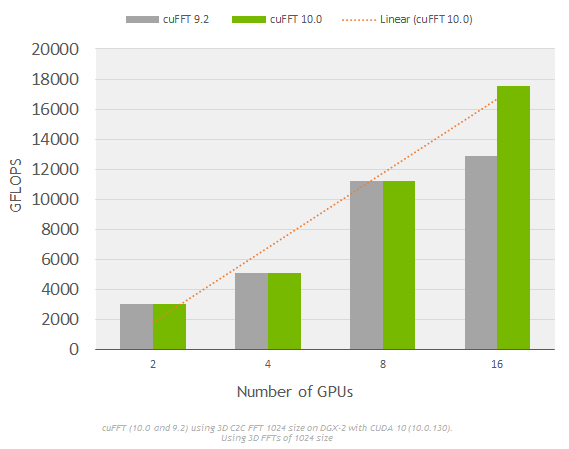
Performance optimizations: cuFFT includes improvements for strong scaling on multi-GPU systems such as NVIDIA’s DGX. Figure 11 shows linear strong scaling of cuFFT (CUDA 10) on a DGX-2 system using varying (2-16) numbers of GPUs.
cuSOLVER 10 includes new algorithms and significant performance improvements for dense linear algebra routines, such as Cholesky factorization, Symmetric Eigensolvers and QR factorization. For example, compared to CUDA 9.2, cuSOLVER 10 achieves a speedup of up to 44x on dense symmetric Eigensolvers (DSYEVD) that helps accelerate a range of quantum chemistry applications in life sciences.
New Libraries and APIs: JPEG decoding is a compute-intensive step in typical deep learning input pipeline and e-commerce applications that perform on-the-fly image resizing. nvJPEG, a new GPU-accelerated library in CUDA 10, will provide acceleration to such applications with low latency decoding of single and batched images, color space conversion, multiple phase decoding, and hybrid decoding using both CPU and GPU. The recently announced open source data loading and augmentation library, NVIDIA DALI, uses nvJPEG to speedup decoding of JPEG images.
cuBLAS 10 includes batched GEMV (matrix-vector multiplication) with FP16 input/output to enable deep learning RNNs using attention models. To aid developers with debugging and better understanding of the APIs, cuBLAS provides an API logger that can be configured at runtime. The logger provides rich information such as Tensor Core usage, tile sizes, kernel names and grid dimensions to name a few metrics. The example below shows the output from logging for program that calls the cublasSgemv API.
I! cuBLAS (v10.0) function cublasStatus_t cublasSgemv_v2(cublasContext*, cublasOperation_t, int, int, const float*, const float*, int, const float*, int, const float*, float*, int) called: i! handle: type=cublasHandle_t; val=POINTER (IN HEX:0x0x7538c00) i! trans: type=cublasOperation_t; val=CUBLAS_OP_T(1) i! m: type=int; val=3 i! n: type=int; val=3 i! alpha: type=float; val=POINTER (IN HEX:0x0x7ffc4f153d64) i! A: type=float; val=POINTER (IN HEX:0x0x1203dc0600) i! lda: type=int; val=3 i! x: type=float; val=POINTER (IN HEX:0x0x1203dc0800) i! incx: type=int; val=1 i! beta: type=float; val=POINTER (IN HEX:0x0x7ffc4f153d68) i! y: type=float; val=POINTER (IN HEX:0x0x1203dc0a00) i! incy: type=int; val=1 i! Time: 2018-09-21T07:13:28 elapsed from start 0.050000 minutes or 3.000000 seconds i!Process=23613; Thread=139695840044864; GPU=0; Handle=POINTER (IN HEX:0x0x7538c00); StreamId=POINTER (IN HEX:0x(nil)) (defaultStream); MathMode=CUBLAS_DEFAULT_MATH
Developer Tools
CUDA 10 introduces a new Nsight product family of developer tools: Nsight Systems and Nsight Compute. Previous releases of CUDA have included standalone tools for debugging (cuda-gdb), functional correctness (cuda-memcheck), profiling (nvprof, Visual Profiler and CUPTI libraries) and IDEs. CUDA 10 continues to include these familiar standalone tools and plugins—Nsight Visual Studio Edition for Microsoft Visual Studio and Nsight Eclipse Edition for the Eclipse development environment. Nsight Systems and Nsight Compute consolidate the functionality provided by these various tools while adding many more features.
Let’s take a brief look at the new tools.
Nsight Systems
Nsight Systems offers system-wide performance analysis that allows developers to visualize application behavior on the CPU and GPU. By using low overhead tracing and sampling techniques to collect process and thread activity, the tool can help developers identify issues such as GPU starvation, unnecessary GPU synchronization, insufficient CPU parallelization, or pipelining. Nsight Systems supports tracing of OpenGL APIs, CUDA APIs, and user annotations using the NVIDIA Tools Extension (NVTX) library. These and other features take advantage of a fast GUI capable of visualizing millions of events. More detailed information is available in the product page and the blog post. Figure 12 shows an example of application profiling.

Nsight Compute
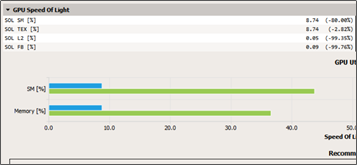
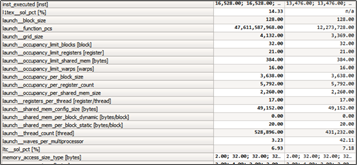
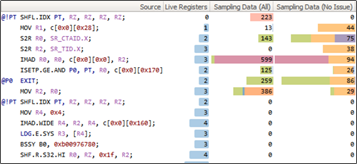
The new Nsight Compute allows kernel profiling and API debugging of CUDA applications. The tool lets developers visualize reports collected across different profiling runs using baselines, allowing metrics to be easily compared during optimization activities. Other features include source code correlation (assembly and PTX) and display of profiling metrics including live registers, memory transactions, instructions executed, and more. Nsight Compute includes a standalone command-line tool for profiling (nv-nsight-cu-cli) applications. Nsight Compute supports Pascal, Volta and Turing GPUs. Note that legacy profiling tools such as nvprof and the Visual Profiler nvvp still support GPUs up to the Volta architecture, however developers should use Nsight Compute for profiling CUDA applications on Turing GPUs.
Check out the documentation for more information on supported platforms and on customizing Nsight Compute using the new Python based rule system. Figure 13 shows example screenshots of the user interface.
 |
 |
 |
Summary
This whirlwind tour of CUDA 10 shows how the latest CUDA provides all the components needed to build applications for Turing GPUs and NVIDIA’s most powerful server platforms for AI and high performance computing (HPC) workloads, both on-premise (DGX-2) and in the cloud (HGX-2).
Download CUDA 10 and get started building and running GPU applications today. CUDA is available on all the popular operating system platforms – Linux, Mac and Windows. NVIDIA provides various meta packages that allow customized installs for Linux using package managers such as apt or yum. CUDA 10 containers are available on the NVIDIA GPU Cloud registry and DockerHub.
Finally, don’t forget to register for the NVIDIA developer program to receive updates on CUDA 10 and future releases of CUDA.