The new NVIDIA A100 GPU based on the NVIDIA Ampere GPU architecture delivers the greatest generational leap in accelerated computing. The A100 GPU has revolutionary hardware capabilities and we’re excited to announce CUDA 11 in conjunction with A100.
CUDA 11 enables you to leverage the new hardware capabilities to accelerate HPC, genomics, 5G, rendering, deep learning, data analytics, data science, robotics, and many more diverse workloads.
CUDA 11 is packed full of features—from platform system software to everything that you need to get started and develop GPU-accelerated applications. This post offers an overview of the major software features in this release:
- Support for the NVIDIA Ampere GPU architecture, including the new NVIDIA A100 GPU for accelerated scale-up and scale-out of AI and HPC data centers; multi-GPU systems with the NVSwitch fabric such as the DGX A100 and HGX A100.
- Multi-Instance GPU (MIG) partitioning capability that is particularly beneficial to cloud service providers (CSPs) for improved GPU utilization.
- New third-generation Tensor Cores to accelerate mixed-precision, matrix operations on different data types, including TF32 and Bfloat16.
- Programming and APIs for task graphs, asynchronous data movement, fine-grained synchronization, and L2 cache residency control.
- Performance optimizations in CUDA libraries for linear algebra, FFTs, and matrix multiplication.
- Updates to the Nsight product family of tools for tracing, profiling, and debugging of CUDA applications.
- Full support on all major CPU architectures, across x86_64, Arm64 server and POWER architectures.
A single post cannot do justice to every feature available in CUDA 11. At the end of this post, there are links to GTC Digital sessions that offer deeper dives into the new CUDA features.
CUDA and NVIDIA Ampere microarchitecture GPUs
Fabricated on the TSMC 7nm N7 manufacturing process, the NVIDIA Ampere GPU microarchitecture includes more streaming multiprocessors (SMs), larger and faster memory, and interconnect bandwidth with third-generation NVLink to deliver massive computational throughput.
The A100’s 40 GB (5-site) high-speed, HBM2 memory has a bandwidth of 1.6 TB/sec, which is over 1.7x faster than V100. The 40 MB L2 cache on A100 is almost 7x larger than that of Tesla V100 and provides over 2x the L2 cache-read bandwidth. CUDA 11 provides new specialized L2 cache management and residency control APIs on the A100. The SMs in A100 include a larger and faster combined L1 cache and shared memory unit (at 192 KB per SM) to provide 1.5x the aggregate capacity of the Volta V100 GPU.
The A100 comes equipped with specialized hardware units including third-generation Tensor Cores, more video decoder (NVDEC) units, JPEG decoder and optical flow accelerators. All of these are used by various CUDA libraries to accelerate HPC and AI applications.
The next few sections discuss the major innovations introduced in NVIDIA A100 and how CUDA 11 enables you to make the most of these capabilities. CUDA 11 offers something for everyone, whether you’re a platform DevOps engineer managing clusters or a software developer writing GPU-accelerated applications. For more information about the NVIDIA Ampere GPU microarchitecture, see the NVIDIA Ampere Architecture In Depth post.
Multi-Instance GPU
The MIG feature can physically divide a single A100 GPU into multiple GPUs. It enables multiple clients such as VMs, containers, or processes to run simultaneously while providing error isolation and advanced quality of service (QoS) between these programs.
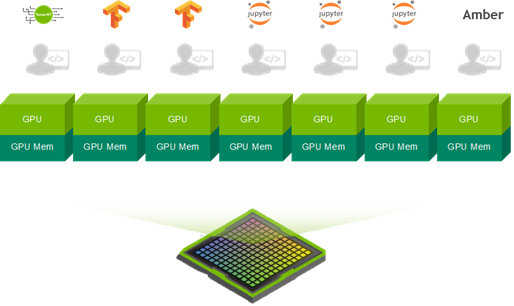
A100 is the first GPU that can either scale up to a full GPU with NVLink or scale out with MIG for many users by lowering the per-GPU instance cost. MIG enables several use cases to improve GPU utilization. This could be for CSPs to rent separate GPU instances, running multiple inference workloads on the GPU, hosting multiple Jupyter notebook sessions for model exploration, or resource sharing of the GPU among multiple internal users in an organization (single-tenant, multi-user).
MIG is transparent to CUDA and existing CUDA programs can run under MIG unchanged to minimize programming effort. CUDA 11 enables configuration and management of MIG instances on Linux operating systems using the NVIDIA Management Library (NVML) or its command-line interface nvidia-smi (nvidia-smi mig subcommands).
Using the NVIDIA Container Toolkit and A100 with MIG enabled, you can also run GPU containers with Docker (using the --gpus option starting with Docker 19.03) or scale out with the Kubernetes container platform using the NVIDIA device plugin.
The following command shows MIG management using nvidia-smi:
# List gpu instance profiles:
# nvidia-smi mig -i 0 -lgip
+-------------------------------------------------------------------------+
| GPU instance profiles: |
| GPU Name ID Instances Memory P2P SM DEC ENC |
| Free/Total GiB CE JPEG OFA |
|=========================================================================|
| 0 MIG 1g.5gb 19 0/7 4.95 No 14 0 0 |
| 1 0 0 |
+-------------------------------------------------------------------------+
| 0 MIG 2g.10gb 14 0/3 9.90 No 28 1 0 |
| 2 0 0 |
+-------------------------------------------------------------------------+
| 0 MIG 3g.20gb 9 0/2 19.81 No 42 2 0 |
| 3 0 0 |
+-------------------------------------------------------------------------+
| 0 MIG 4g.20gb 5 0/1 19.81 No 56 2 0 |
| 4 0 0 |
+-------------------------------------------------------------------------+
| 0 MIG 7g.40gb 0 0/1 39.61 No 98 5 0 |
| 7 1 1 |
+-------------------------------------------------------------------------+
System software platform support
For use in the enterprise datacenter, the NVIDIA A100 introduces new memory error recovery features that improve resilience and avoid impacting running CUDA applications. Uncorrectable ECC errors on prior architectures would impact all running workloads on the GPU, requiring a reset of the GPU.
On the A100, the impact is limited to the application that encountered the error and which is terminated, while other running CUDA workloads are unaffected. The GPU no longer requires a reset to recover. The NVIDIA driver performs dynamic page blacklisting to mark the page unusable so that current and new applications do not access the affected memory region.
When the GPU is reset, as part of a regular GPU/VM service window, the A100 is equipped with a new hardware mechanism called row-remapping that replaces degraded cells in memory with spare cells and avoids creating any holes in the physical memory address space.
The NVIDIA driver with CUDA 11 now reports various metrics related to row-remapping both in-band (using NVML/nvidia-smi) and out-of-band (using the system BMC). A100 includes new out-of-band capabilities, in terms of more available GPU and NVSwitch telemetry, control and improved bus transfer data rates between the GPU and the BMC.
For improved resiliency and high availability on multi-GPU systems such as DGX A100 and HGX A100, the system software supports the ability to disable a failing GPU or NVSwitch node rather than the entire baseboard as in previous generations of systems.
CUDA 11 is the first release to add production support for Arm servers. By combining Arm’s energy-efficient CPU architecture with CUDA, the Arm ecosystem will benefit from GPU-accelerated computing for a variety of use cases: from edge, cloud, and gaming to powering supercomputers. CUDA 11 supports Marvell’s high-performance ThunderX2-based servers and is working closely with Arm and other hardware and software partners in the ecosystem to quickly enable support for GPUs.
Third-generation, multi-precision Tensor Cores
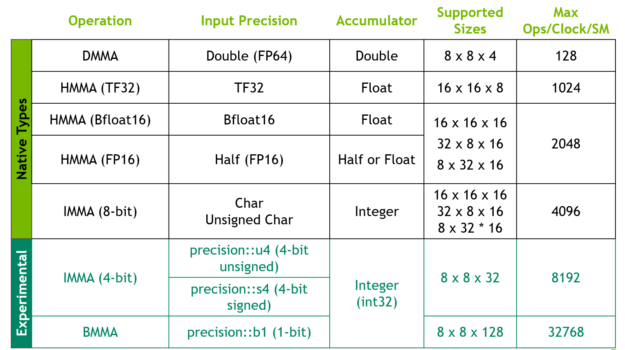
The four large Tensor Cores per SM (for a total of 432 Tensor Cores) in the NVIDIA A100 provide faster matrix-multiply-accumulate (MMA) operations for all datatypes: Binary, INT4, INT8, FP16, Bfloat16, TF32, and FP64.
You access Tensor Cores through either different deep learning frameworks, CUDA C++ template abstractions provided by CUTLASS, or CUDA libraries such as cuBLAS, cuSOLVER, cuTENSOR, or TensorRT.
CUDA C++ makes Tensor Cores available using the warp-level matrix (WMMA) API. This portable API abstraction exposes specialized matrix load, matrix multiply and accumulate, and matrix store operations to efficiently use Tensor Cores from a CUDA C++ program. All functions and data types for WMMA are available in the nvcuda::wmma namespace. You can also directly access the Tensor Cores for A100 (that is, devices with compute capability compute_80 and higher) using the mma_sync PTX instruction.
CUDA 11 adds support for the new input data type formats: Bfloat16, TF32, and FP64. Bfloat16 is an alternate FP16 format but with reduced precision that matches the FP32 numerical range. Its usage results in lower bandwidth and storage requirements and therefore higher throughput. Bfloat16 is exposed as a new CUDA C++ __nv_bfloat16 data type in cuda_bf16.h, through WMMA and supported by the various CUDA math libraries.
TF32 is a special floating-point format meant to be used with Tensor Cores. TF32 includes an 8-bit exponent (same as FP32), 10-bit mantissa (same precision as FP16), and one sign-bit. It is the default math mode to allow you to get speedups over FP32 for DL training, without any changes to models. Finally, A100 brings double precision (FP64) support to MMA operations, which is also supported by the WMMA interfaces.
Programming NVIDIA Ampere architecture GPUs
With the goal of improving GPU programmability and leveraging the hardware compute capabilities of the NVIDIA A100 GPU, CUDA 11 includes new API operations for memory management, task graph acceleration, new instructions, and constructs for thread communication. Here’s a look at some of these new operations and how they can enable you to take advantage of A100 and the NVIDIA Ampere microarchitecture.
Memory management
One of the optimization strategies to maximize the performance of a GPU kernel is to minimize data transfer. If the memory is resident in global memory, the latency of reading data into the L2 cache or into shared memory might take several hundred processor cycles.
For example, on the GV100, shared memory provides a bandwidth of 17x faster than global memory or 3x faster than L2. Thus, some algorithms with a producer-consumer paradigm may observe performance benefits with persisting data in L2 between kernels, and therefore achieve higher bandwidth and performance.
On A100, CUDA 11 offers API operations to set aside a portion of the 40-MB L2 cache to persist data accesses to global memory. Persisting accesses have prioritized use of this set-aside portion of L2 cache, whereas normal or streaming accesses to global memory can only use this portion of L2 when it is unused by persisting accesses.
L2 persistence can be set for use in a CUDA stream or in a CUDA graph kernel node. Some considerations need to be made when setting aside the L2 cache area. For example, multiple CUDA kernels executing concurrently in different streams, while having a different access policy window, share the L2 set-aside cache. The following code example shows setting aside the L2 cache ratio for persistence.
cudaGetDeviceProperties( &prop, device_id); // Set aside 50% of L2 cache for persisting accesses size_t size = min( int(prop.l2CacheSize * 0.50) , prop.persistingL2CacheMaxSize ); cudaDeviceSetLimit( cudaLimitPersistingL2CacheSize, size); // Stream level attributes data structure cudaStreamAttrValue attr ; attr.accessPolicyWindow.base_ptr = /* beginning of range in global memory */ ; attr.accessPolicyWindow.num_bytes = /* number of bytes in range */ ; // hitRatio causes the hardware to select the memory window to designate as persistent in the area set-aside in L2 attr.accessPolicyWindow.hitRatio = /* Hint for cache hit ratio */ // Type of access property on cache hit attr.accessPolicyWindow.hitProp = cudaAccessPropertyPersisting; // Type of access property on cache miss attr.accessPolicyWindow.missProp = cudaAccessPropertyStreaming; cudaStreamSetAttribute(stream,cudaStreamAttributeAccessPolicyWindow,&attr);
The virtual memory management API operations have been extended to support compression on pinned GPU memory to reduce L2 to DRAM bandwidth. This can be important for deep learning training and inference use cases. When you create a shareable memory handle using cuMemCreate, you provide an allocation hint to the API operation.
Efficient implementations of algorithms such as 3D stencils or convolutions involve a memory copy and computation control flow pattern where data is transferred from global memory into shared memory of thread blocks, followed by computations that use this shared memory. The global to shared memory copy is expanded into a read from global memory into a register, followed by a write to shared memory.
CUDA 11 lets you take advantage of a new asynchronous copy (async-copy) paradigm. It essentially overlaps copying data from global to shared memory with computation and avoids the use of intermediate registers or the L1 cache. Async-copy has benefits: control flow no longer traverses the memory pipeline twice and not using intermediate registers can reduce register pressure, increasing kernel occupancy. On A100, async-copy operations are hardware-accelerated.
The following code example shows a simple example of using async-copy. The resulting code, while more performant, can be further optimized by pipelining multiple batches of async-copy operations. This additional pipelining can result in the elimination of one of the synchronization points in the code.
Async-copy is offered as an experimental feature in CUDA 11 and is exposed using cooperative group collectives. The CUDA C++ Programming Guide includes more advanced examples of using async-copy with multi-stage pipelining and hardware-accelerated barrier operations in A100.
//Without async-copy
using namespace nvcuda::experimental;
__shared__ extern int smem[];
// algorithm loop iteration
while ( ... ) {
__syncthreads();
// load element into shared mem
for ( i = ... ) {
// uses intermediate register
// {int tmp=g[i]; smem[i]=tmp;}
smem[i] = gldata[i];
}//With async-copy
using namespace nvcuda::experimental;
__shared__ extern int smem[];
pipeline pipe;
// algorithm loop iteration
while ( ... ) {
__syncthreads();
// load element into shared mem
for ( i = ... ) {
// initiate async memory copy
memcpy_async(smem[i],
gldata[i],
pipe);
}
// wait for async-copy to complete
pipe.commit_and_wait();
__syncthreads();
/* compute on smem[] */
}Task graph acceleration
CUDA Graphs, introduced in CUDA 10, represented a new model for submitting work using CUDA. A graph consists of a series of operations, such as memory copies and kernel launches, connected by dependencies and defined separately from its execution.
Graphs enable a define-once-run-repeatedly execution flow. They can reduce cumulative launch overheads and improve overall performance of the application. This is particularly true for deep learning applications that may launch several kernels with decreasing task size and runtimes, or which may have complex dependencies between tasks.
Starting with A100, the GPU provides task graph hardware acceleration to prefetch grid launch descriptors, instructions, and constants. This improves the kernel launch latency using CUDA graphs on A100 compared to prior GPUs such as V100.
 CPU launch latency with CUDA Graphs")
The CUDA Graph API operations now have a lightweight mechanism to support in-place updates to instantiated graphs without requiring a graph rebuild. During repeated instantiations of a graph, it is common for node parameters, such as kernel parameters, to change while the graph topology remains constant. Graph API operations provide a mechanism for updates to the whole graph, where you provide a topologically identical cudaGraph_t object with updated node parameters, or explicit updates to individual nodes.
Additionally, CUDA graphs now support cooperative kernel launch (cuLaunchCooperativeKernel), including stream capture for parity with CUDA streams.
Thread collectives
Here are some of the enhancements that CUDA 11 adds to cooperative groups, introduced in CUDA 9. Cooperative Groups is a collective programming mode that aims to enable you to explicitly express granularities at which the threads can communicate. This enables new patterns of cooperative parallelism within CUDA.
In CUDA 11, cooperative group collectives expose new A100 hardware features and add several API enhancements. For more information about the complete list of changes, see the CUDA C++ Programming Guide.
A100 introduces a new reduce instruction that operates on the data provided by each thread. This is exposed as a new collective using cooperative groups, which provides a portable abstraction that can be used on older architectures as well. The reduce operation supports arithmetic (for example, add), and logical (for example, AND) operations. The following code example shows the reduce collective.
// Simple Reduction Sum
#include <cooperative_groups/reduce.h>
...
const int threadId = cta.thread_rank();
int val = A[threadId];
// reduce across tiled partition
reduceArr[threadId] = cg::reduce(tile, val, cg::plus<int>());
// synchronize partition
cg::sync(cta);
// accumulate sum using a leader and return sumCooperative groups provide collective operations (labeled_partition) that partition the parent group into one-dimensional subgroups within which the threads are coalesced. This is particularly helpful for control flow that attempts to keep track of active threads through basic blocks of conditional statements.
For example, multiple partitions can be formed out of a warp-level group (that is not constrained to powers of 2) using labeled_partition and used in an atomic add operation. The labeled_partition API operation evaluates a condition label and assigns threads that have the same value for the label into the same group.
The following code example shows custom thread partitions:
// Get current active threads (that is, coalesced_threads())
cg::coalesced_group active = cg::coalesced_threads();
// Match threads with the same label using match_any()
int bucket = active.match_any(value);
cg::coalesced_group subgroup = cg::labeled_partition(active, bucket);
// Choose a leader for each partition (for example, thread_rank = 0)
//
if (subgroup.thread_rank() == 0) {
threadId = atomicAdd(&addr[bucket], subgroup.size());
}
// Now use shfl to transfer the result back to all threads in partition
return (subgroup.shfl(threadId, 0));CUDA C++ language and compiler improvements
CUDA 11 is also the first release to officially include CUB as part of the CUDA Toolkit. CUB is now one of the supported CUDA C++ core libraries.
One of the major features in nvcc for CUDA 11 is the support for link time optimization (LTO) for improving the performance of separate compilation. LTO, using the --dlink-time-opt or -dlto options, stores intermediate code during compilation and then performs higher-level optimizations at link time, such as inlining code across files.
nvcc in CUDA 11 adds support for ISO C++17 and support for new host compilers across PGI, gcc, clang, Arm, and Microsoft Visual Studio. If you want to experiment with host compilers not yet supported, nvcc supports a new --allow-unsupported-compiler flag during the compile-build workflow. nvcc adds other new features, including the following:
- Improved lambda support
- Dependency file generation enhancements (
-MD,-MMDoptions) - Pass-through options to the host compiler
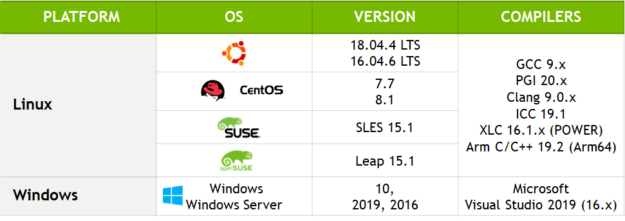
CUDA libraries
The libraries in CUDA 11 continue to push the boundaries of performance and developer productivity by using the latest and greatest A100 hardware features behind familiar drop-in APIs in linear algebra, signal processing, basic mathematical operations, and image processing.

Across the linear algebra libraries, you will see Tensor Core acceleration for the full range of precisions available on A100, including FP16, Bfloat16, TF32, and FP64. This includes BLAS3 operations in cuBLAS, factorizations and dense linear solvers in cuSOLVER, and tensor contractions in cuTENSOR.
In addition to the enhanced range of precisions, restrictions on matrix dimensions and alignment for Tensor Core acceleration have been removed. For appropriate precisions, the acceleration is now automatic, requiring no user opt-in. The heuristics for cuBLAS automatically adapt to resources when running on the GPU instances with MIG on A100.

CUTLASS, the CUDA C++ template abstractions for high-performance GEMM, supports all the various precision modes offered by A100. With CUDA 11, CUTLASS now achieves more than 95% performance parity with cuBLAS. This allows you to write your own custom CUDA kernels for programming the Tensor Cores in NVIDIA GPUs.


cuFFT takes advantage of the larger shared memory size in A100, resulting in better performance for single-precision FFTs at larger batch sizes. Finally, on multi-GPU A100 systems, cuFFT scales and delivers 2X performance per GPU compared to V100.
nvJPEG is a GPU-accelerated library for JPEG decoding. Together with NVIDIA DALI, a data augmentation and image loading library, it can accelerate deep learning training on image classification models, especially computer vision. The libraries accelerate the image decode and data augmentation phase of the deep learning workflow.
The A100 includes a 5-core hardware JPEG decode engine and nvJPEG takes advantage of the hardware backend for batched processing of JPEG images. JPEG acceleration by a dedicated hardware block alleviates bottlenecks on the CPU and allows better GPU utilization.
Selecting the hardware decoder is done automatically by the nvjpegDecode for a given image or by explicitly selecting the hardware backend using nvjpegCreateEx init function. nvJPEG provides acceleration of baseline JPEG decode, and various color conversion formats, for example, YUV 420, 422, and 444.
Figure 8 shows that this results in up to 18x faster image decode compared to CPU-only processing. If you use DALI, you can directly benefit from this hardware acceleration because nvJPEG is abstracted.
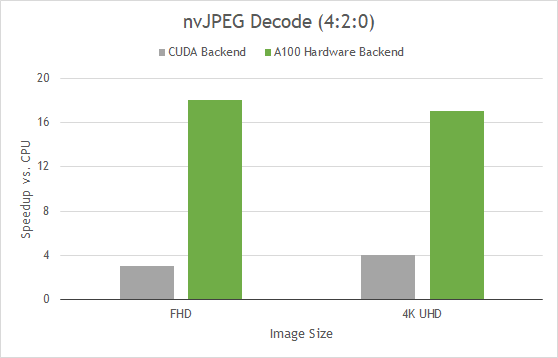
(Batch 128 with Intel Platinum 8168 @2GHz 3.7GHz Turbo HT on; with TurboJPEG)
There are many more features in the CUDA math libraries than can be covered in a single post.
Developer tools
CUDA 11 continues to add rich features to the existing portfolio of developer tools. This includes familiar plugins for Visual Studio, with the NVIDIA Nsight Integration for Visual Studio, and Eclipse, with Nsight Eclipse Plugins Edition. It also includes standalone tools, such as Nsight Compute for kernel profiling, and Nsight Systems for system-wide performance analysis. Nsight Compute and Nsight Systems are now supported on all three CPU architectures supported by CUDA: x86, POWER, and Arm64.
 and Nsight Compute (kernel profiling).")
One of the key features of Nsight Compute for CUDA 11 is the ability to generate the Roofline model of the application. A Roofline model is a visually intuitive method for you to understand kernel characteristics by combining floating-point performance, arithmetic intensity, and memory bandwidth into a two-dimensional plot.
By looking at the Roofline model, you can quickly determine whether the kernel is compute-bound or memory-bound. You can also understand potential directions for further optimizations, for example, kernels that are near the roofline make optimal use of computational resources.
For more information, see Roofline Performance Model.
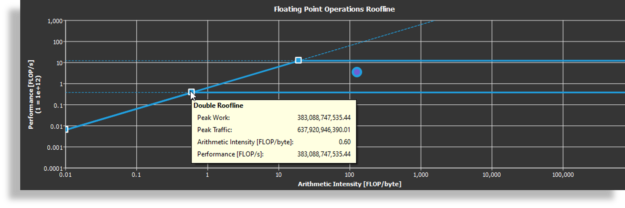
CUDA 11 includes the Compute Sanitizer, a next-generation, functional correctness checking tool that provides runtime checking for out-of-bounds memory accesses and race conditions. Compute Sanitizer is intended to be a replacement for the cuda-memcheck tool.
The following code example shows an example of Compute Sanitizer checking memory accesses.
//Out-of-bounds Array Access
__global__ void oobAccess(int* in, int* out)
{
int bid = blockIdx.x;
int tid = threadIdx.x;
if (bid == 4)
{
out[tid] = in[dMem[tid]];
}
}
int main()
{
...
// Array of 8 elements, where element 4 causes the OOB
std::array<int, Size> hMem = {0, 1, 2, 10, 4, 5, 6, 7};
cudaMemcpy(d_mem, hMem.data(), size, cudaMemcpyHostToDevice);
oobAccess<<<10, Size>>>(d_in, d_out);
cudaDeviceSynchronize();
...
$ /usr/local/cuda-11.0/Sanitizer/compute-sanitizer --destroy-on-device-error kernel --show-backtrace no basic
========= COMPUTE-SANITIZER
Device: Tesla T4
========= Invalid __global__ read of size 4 bytes
========= at 0x480 in /tmp/CUDA11.0/ComputeSanitizer/Tests/Memcheck/basic/basic.cu:40:oobAccess(int*,int*)
========= by thread (3,0,0) in block (4,0,0)
========= Address 0x7f551f200028 is out of boundsThe following code example shows a Compute Sanitizer example for race condition checks.
//Contrived Race Condition Example
__global__ void Basic()
{
__shared__ volatile int i;
i = threadIdx.x;
}
int main()
{
Basic<<<1,2>>>();
cudaDeviceSynchronize();
...
$ /usr/local/cuda-11.0/Sanitizer/compute-sanitizer --destroy-on-device-error kernel --show-backtrace no --tool racecheck --racecheck-report hazard raceBasic
========= COMPUTE-SANITIZER
========= ERROR: Potential WAW hazard detected at __shared__ 0x0 in block (0,0,0) :
========= Write Thread (0,0,0) at 0x100 in /tmp/CUDA11.0/ComputeSanitizer/Tests/Racecheck/raceBasic/raceBasic.cu:11:Basic(void)
========= Write Thread (1,0,0) at 0x100 in /tmp/CUDA11.0/ComputeSanitizer/Tests/Racecheck/raceBasic/raceBasic.cu:11:Basic(void)
========= Current Value : 0, Incoming Value : 1
=========
========= RACECHECK SUMMARY: 1 hazard displayed (1 error, 0 warnings)Finally, even though CUDA 11 no longer supports running applications on macOS, we are making developer tools available for users on macOS hosts:
- Remote target debugging using
cuda-gdb - NVIDIA Visual Profiler
- Nsight Eclipse plugins
- The Nsight family of tools for remote profiling or tracing
Summary
CUDA 11 provides a foundational development environment for building applications for the NVIDIA Ampere GPU architecture and powerful server platforms built on the NVIDIA A100 for AI, data analytics, and HPC workloads, both for on-premises (DGX A100) and cloud (HGX A100) deployments.
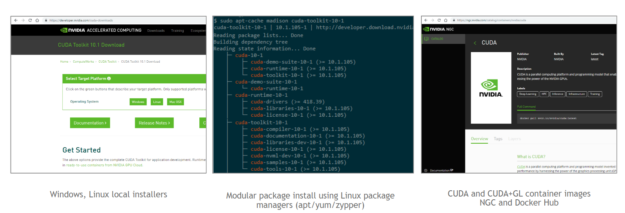
CUDA 11 is now available. As always, you can get CUDA 11 in several ways: download local installer packages, install using package managers, or grab containers from various registries. For enterprise deployments, CUDA 11 also includes driver packaging improvements for RHEL 8 using modularity streams to improve stability and reduce installation time.
To learn more about CUDA 11 and get answers to your questions, register for the following upcoming live webinars:
- Inside the NVIDIA Ampere Architecture
- CUDA New Features and Beyond
- Inside the HPC SDK: The Compilers, Libraries, and Tools for Accelerated Computing
- CUDA on NVIDIA Ampere Architecture: Taking Your Algorithms to the Next Level of Performance
- Optimizing Applications for NVIDIA Ampere GPU Architecture
- Tensor Core Performance on NVIDIA GPUs: The Ultimate Guide
- Developing CUDA Kernels to Push Tensor Cores to the Absolute Limit on NVIDIA A100
Also, watch out for the following related GTC talks for deep dives on the features for A100 covered in this post. These GTC recorded talks will be posted during the month of May:
- How CUDA Math Libraries Can Help You Unleash the Power of the New NVIDIA A100 GPU
- Inside NVIDIA’s Multi-Instance GPU Feature
- CUDA Developer Tools: Overview & Exciting New Features
Finally, register for the NVIDIA Developer Program to receive updates on CUDA 11 and future releases of CUDA.