It’s almost time for the next major release of the CUDA Toolkit, so I’m excited to tell you about the CUDA 7 Release Candidate, now available to all CUDA Registered Developers. The CUDA Toolkit version 7 expands the capabilities and improves the performance of the Tesla Accelerated Computing Platform and of accelerated computing on NVIDIA GPUs.
Recently NVIDIA released the CUDA Toolkit version 5.5 with support for the IBM POWER architecture. Starting with CUDA 7, all future CUDA Toolkit releases will support POWER CPUs.
CUDA 7 is a huge update to the CUDA platform; there are too many new features and improvements to describe in one blog post, so I’ll touch on some of the most significant ones today. Please refer to the CUDA 7 release notes and documentation for more information. We’ll be covering many of these features in greater detail in future Parallel Forall posts, so check back often!
Support for Powerful C++11 Features
C++11 is a major update to the popular C++ language standard. C++11 includes a long list of new features for simpler, more expressive C++ programming with fewer errors and higher performance. I think Bjarne Stroustrup, the creator of C++, put it best:
C++11 feels like a new language: The pieces just fit together better than they used to and I find a higher-level style of programming more natural than before and as efficient as ever.
CUDA 7 adds C++11 feature support to nvcc, the CUDA C++ compiler. This means that you can use C++11 features not only in your host code compiled with nvcc, but also in device code. In your device code, you can now use new C++ language features like auto, lambda, variadic templates, static_assert, rvalue references, range-based for loops, and more.
Here’s a little example I whipped up to demonstrate using C++ auto, lambdas, std::initializer_list, and range-based for loops in CUDA device code. This program defines a generic find routine and then uses it in a kernel with a lambda function to customize its use to count occurences in a text of a list of letters.
#include <initializer_list>
#include <iostream>
#include <cstring>
// Generic parallel find routine. Threads search through the
// array in parallel. A thread returns the index of the
// first value it finds that satisfies predicate `p`, or -1.
template <typename T, typename Predicate>
__device__ int find(T *data, int n, Predicate p)
{
for (int i = blockIdx.x * blockDim.x + threadIdx.x;
i < n;
i += blockDim.x * gridDim.x)
{
if (p(data[i])) return i;
}
return -1;
}
// Use find with a lambda function that searches for x, y, z
// or w. Note the use of range-based for loop and
// initializer_list inside the functor, and auto means we
// don't have to know the type of the lambda or the array
__global__
void xyzw_frequency(unsigned int *count, char *data, int n)
{
auto match_xyzw = [](char c) {
const char letters[] = { 'x','y','z','w' };
for (const auto x : letters)
if (c == x) return true;
return false;
};
int i = find(data, n, match_xyzw);
if (i >= 0) atomicAdd(count, 1);
}
int main(void)
{
char text[] = "zebra xylophone wax";
char *d_text;
cudaMalloc(&d_text, sizeof(text));
cudaMemcpy(d_text, text, sizeof(text),
cudaMemcpyHostToDevice);
unsigned int *d_count;
cudaMalloc(&d_count, sizeof(unsigned int));
cudaMemset(d_count, 0, sizeof(unsigned int));
xyzw_frequency<<<1, 64>>>(d_count, d_text,
strlen(text));
unsigned int count;
cudaMemcpy(&count, d_count, sizeof(unsigned int),
cudaMemcpyDeviceToHost);
std::cout << count << " instances of 'x', 'y', 'z', 'w'"
<< "in " << text << std::endl;
cudaFree(d_count);
cudaFree(d_text);
return 0;
}
Here’s how I compiled and ran this code on my Macbook Pro (GeForce GT 750M), and the output.
$ nvcc --std=c++11 c++11_cuda.cu -o c++11_cuda $ ./c++11_cuda 5 instances of 'x', 'y', 'z', or 'w' in zebra xylophone wax
New Capabilities and Higher Performance for Thrust
![]() CUDA 7 includes a brand-new release of Thrust, version 1.8. Modeled after the C++ Standard Template Library, the Thrust library brings a familiar abstraction layer to the realm of parallel computing, providing efficient and composable parallel algorithms that operate on vector containers.
CUDA 7 includes a brand-new release of Thrust, version 1.8. Modeled after the C++ Standard Template Library, the Thrust library brings a familiar abstraction layer to the realm of parallel computing, providing efficient and composable parallel algorithms that operate on vector containers.
Thrust 1.8 introduces support for algorithm invocation from CUDA __device__ code, support for CUDA streams, and algorithm performance improvements. Users may now invoke Thrust algorithms from CUDA __device__ code, providing a parallel algorithms library to CUDA programmers authoring custom kernels, as well as allowing Thrust programmers to nest their algorithm calls within functors. The thrust::seq execution policy allows you to enforce sequential algorithm execution in the calling thread and makes a sequential algorithms library available to individual CUDA threads. The .on(stream) syntax lets you specify a CUDA stream for kernels launched during algorithm execution.
Thrust 1.8 also includes new CUDA algorithm implementations with substantial performance improvements. Here are some example measured improvements on a Tesla K20c accelerator for large problem sizes (using the CUDA Thrust backend):
thrust::sortis 300% faster for user-defined types and 50% faster for primitive types;thrust::mergeis 200% faster;thrust::reduce_by_keyis 25% faster;thrust::scanis 15% faster.
cuSOLVER: A Powerful New Direct Linear Solver Library
In CUDA 7, a new library joins the growing suite of numerical libraries for accelerated computing. cuSOLVER provides dense and sparse direct linear solvers and Eigen Solvers.
The intent of cuSOLVER is to provide useful LAPACK-like features, such as common matrix factorization and triangular solve routines for dense matrices, a sparse least-squares solver and an eigenvalue solver. In addition cuSOLVER provides a new refactorization library useful for solving sequences of matrices with a shared sparsity pattern.
cuSolver running on a Tesla GPU can provide large speedups compared to running on a CPU, as you can see in Figures 1 and 2.
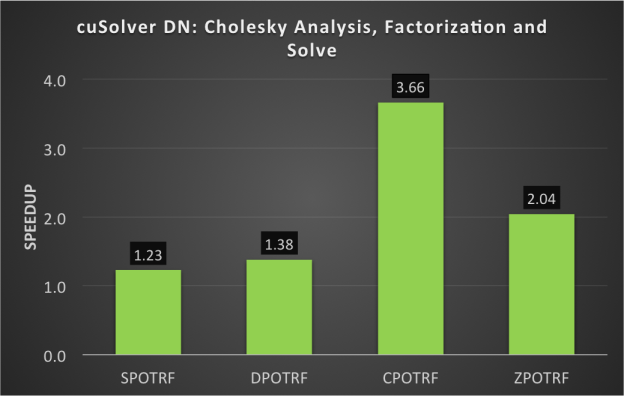
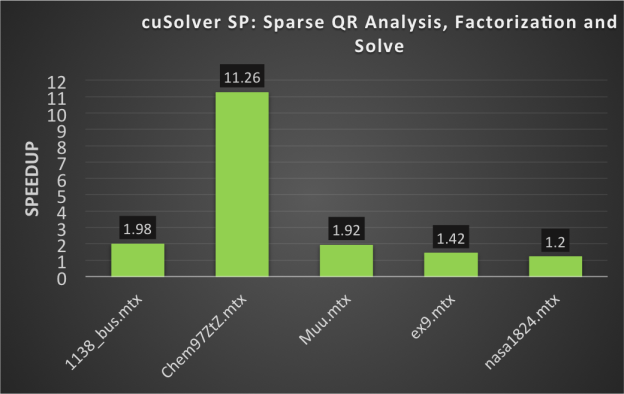
cuFFT Performance Improvements
cuFFT 7.0 improves FFT performance by up to 3.5x for sizes that are composite powers of 2, 3, 5, and 7. Figure 2 shows speedups of cuFFT 7.0 vs. cuFFT 6.5 for 1D FFTs, and Figure 3 shows speedups for 3D FFTs. (Experiments were performed on a Tesla K20c with ECC ON, batched transforms on 32M total elements, input and output data on device.)
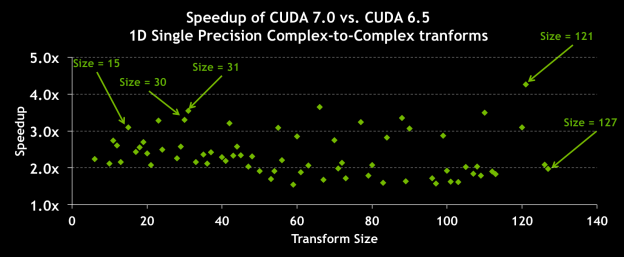
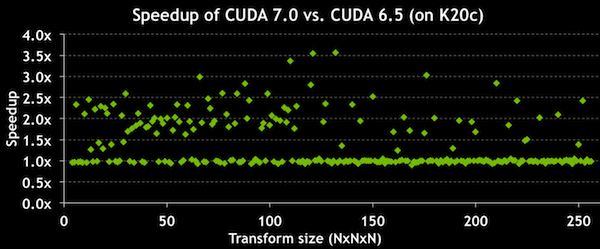
Runtime Compilation
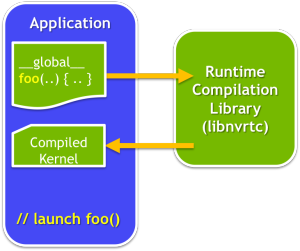
The new Runtime Compilation library (nvrtc) provides an API to compile CUDA-C++ device source code at run time. You can launch the resulting compiled PTX on a GPU using the CUDA Driver API. Runtime Compilation enables run-time code generation, and run-time specialization of CUDA kernel code, with much lower overhead compared to launching nvcc from your application at run time.
Many CUDA developers optimize CUDA kernels using template parameters, which allows them to generate multiple optimized versions of a kernel at compile time for use under different circumstances. Consider the following (simplified) example. Here we have a loop for which the number of iterations depends on the thread block size (a parallel reduction might use this pattern).
__device__ void foo(float *x) {
for (int i = 1; i <= blockDim.x; i *= 2) {
doSomething(x, i);
}
}
If we know the block size at compile time, we can hard code the loop limit, which enables the compiler to unroll the loop. But we might need to support multiple block sizes, so it’s more flexible to use a template parameter.
template <int blocksize>
__device__ void foo(float *x) {
#pragma unroll
for (int i = 1; i <= blocksize; i *= 2) {
doSomething(x, i);
}
}
But template parameter values must be constant at compile time, so to use this code for multiple block sizes, we have to hard-code all of the block sizes we want to support in a switch or if/else block. That’s painful. But with Runtime Compilation, run time is compile time, so we can simply generate and compile the exact version of the kernel we need based on run-time values. This run-time code specialization can result in highly tuned code.
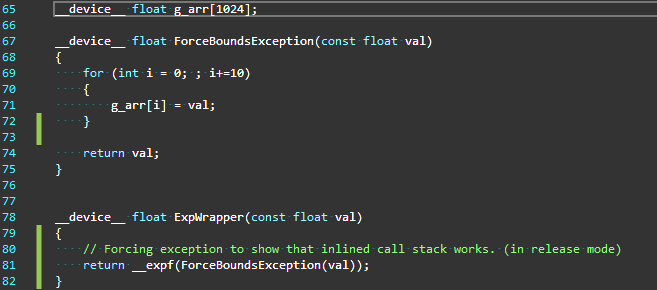
(Note: Runtime Compilation is a preview feature in CUDA 7.0 and any or all parts of this specification are subject to change in the next CUDA release.)
Much More to Explore
This brief look at CUDA 7 should give you a feeling for how powerful this new release is, but we’ve barely scratched the surface. To mention a few other features, CUDA 7 supports GPU Core Dumps for easier remote and cluster debugging; new CUDA Memcheck tools for detecting uninitialized data and improper synchronization; and multi-GPU support in the CUDA multi-process server; and support for new platforms and compilers.
So don’t wait, the CUDA Toolkit version 7 Release Candidate is available right now. It even has a great new network installer that only downloads and installs the CUDA Toolkit components that you need, saving time and bandwidth.
Download CUDA today at https://developer.nvidia.com/cuda-toolkit
Want to learn more about accelerated computing on the Tesla Platform and about GPU computing with CUDA? Come to the GPU Technology Conference, the world’s largest and most important GPU developer conference.