At the 2017 GPU Technology Conference NVIDIA announced CUDA 9, the latest version of CUDA’s powerful parallel computing platform and programming model. CUDA 9 is now available as a free download. In this post I’ll provide an overview of the awesome new features of CUDA 9.
- Support for the Volta GPU architecture, including the new Tesla V100 accelerator;
- Cooperative Groups, a new programming model for managing groups of communicating threads;
- A new API (preview feature) for programming Tensor Core matrix multiply and accumulate operations on Tesla V100.
- Faster library routines for linear algebra, image processing, FFTs, and more;
- New algorithms in cuSolver and nvGraph
- New NVIDIA Visual Profiler support for Volta V100 as well as improved Unified Memory profiling features;
- Improved compiler performance;
- Support for C++14 in CUDA device code;
- Expanded developer platform and host compiler support including Microsoft Visual Studio 2017, clang 3.9, PGI 17.1 and GCC 6.x;
The CUDA Toolkit version 9.0 is available as a free download. To learn more you can watch the recording of my talk from GTC 2017, “CUDA 9 and Beyond”.
CUDA 9 Supports the new NVIDIA Volta Architecture
The soul of CUDA 9 is support for the powerful new Volta Architecture, specifically the new Tesla V100 GPU accelerator which was launched at GTC 2017. For full details on V100 and the Volta GV100 GPU, check out the blog post “Inside Volta”.
Tesla V100’s new Streaming Multiprocessor (SM) design provides extreme floating-point and integer performance for Deep Learning and HPC. The new Volta SM is 50% more energy efficient than the previous generation Pascal design, enabling major boosts in FP32 and FP64 performance in the same power envelope. New Tensor Cores designed specifically for deep learning deliver up to 12x higher peak TFLOP/ss for training, and 6x higher peak TFLOP/s for inference. With independent, parallel integer and floating point datapaths, the Volta SM is also much more efficient on workloads with a mix of computation and addressing calculations. Volta’s new independent thread scheduling capability enables finer-grain synchronization and cooperation between parallel threads. Finally, a new combined L1 Data Cache and Shared Memory subsystem significantly improves performance while also simplifying programming.
Keep reading for information on how to program Tensor Cores in CUDA.
Cooperative Groups
In parallel algorithms, threads often need to cooperate to perform collective computations. Building these cooperative codes requires grouping and synchronizing the cooperating threads. CUDA 9 introduces Cooperative Groups, a new programming model for organizing groups of threads.
Historically, the CUDA programming model has provided a single, simple construct for synchronizing cooperating threads: a barrier across all threads of a thread block, as implemented with the __syncthreads( ) function. However, programmers often would like to define groups of threads at smaller than thread block granularities and synchronize within them, in order to enable greater performance, design flexibility, and software reuse in the form of “collective” group-wide function interfaces.
Cooperative Groups introduces the ability to define groups of threads explicitly at sub-block and multiblock granularities, and to perform collective operations such as synchronization on them. This programming model supports clean composition across software boundaries, so that libraries and utility functions can synchronize safely within their local context without having to make assumptions about convergence. It lets developers optimize for the hardware fast path—for example the GPU warp size—using flexible synchronization in a safe, supportable way that makes programmer intent explicit. Cooperative Groups primitives enable new patterns of cooperative parallelism within CUDA, including producer-consumer parallelism, opportunistic parallelism, and global synchronization across the entire Grid.
Cooperative Groups also provides an abstraction by which developers can write flexible, scalable code that will work safely across different GPU architectures, including scaling to future GPU capabilities. Thread groups may range in size from a few threads (smaller than a warp) to a whole thread block, to all thread blocks in a grid launch, to grids spanning multiple GPUs.
While Cooperative Groups works on all GPU architectures, certain functionality is inevitably architecture-dependent as GPU capabilities have evolved. Basic functionality, such as synchronizing groups smaller than a thread block down to warp granularity, is supported on all architectures, while Pascal and Volta GPUs enable new grid-wide and multi-GPU synchronizing groups. In addition, Volta’s independent thread scheduling enables significantly more flexible selection and partitioning of thread groups at arbitrary cross-warp and sub-warp granularities. Volta synchronization is truly per thread: threads in a warp can synchronize from divergent code paths.
The Cooperative Groups programming model consists of the following elements:
- Data types for representing groups of cooperating threads;
- Default groups defined by the CUDA launch API (e.g., thread blocks and grids);
- Operations for partitioning existing groups into new groups;
- A barrier operation to synchronize all threads within a group;
- Operations to inspect the group properties as well as group-specific collectives.
Some basic Cooperative Groups operations are illustrated in the following simple example.
__global__ void cooperative_kernel(...)
{
// obtain default "current thread block" group
thread_group my_block = this_thread_block();
// subdivide into 32-thread, tiled subgroups
// Tiled subgroups evenly partition a parent group into
// adjacent sets of threads - in this case each one warp in size
thread_group my_tile = tiled_partition(my_block, 32);
// This operation will be performed by only the
// first 32-thread tile of each block
if (my_block.thread_rank() < 32) {
…
my_tile.sync();
}
}
Cooperative Groups uses C++ templates to provide types and API overloads to represent groups whose size is statically determined for even greater efficiency. The language-level interface is supported by a set of PTX assembly extensions that provide the substrate for the CUDA C++ implementation. These PTX extensions are also available to any programming system that wants to provide similar functionality. Finally, the race detection tool in cuda-memcheck and the CUDA debugger are compatible with the more flexible synchronization patterns permitted by Cooperative Groups, to make it easier to find subtle parallel synchronization bugs such as Read After Write (RAW) hazards.
Cooperative Groups allows programmers to express synchronization patterns that they were previously unable to express. When the granularity of synchronization corresponds to natural architectural granularities (warps and thread blocks), the overhead of this flexibility is negligible. Libraries of collective primitives written using Cooperative Groups often require less complex code to achieve high performance.
Consider a particle simulation, where we have two main computation phases in each step of the simulation. First, integrate the position and velocity of each particle forward in time. Second, build a regular grid spatial data structure to accelerate finding collisions between particles. Figure 2 shows the two phases.
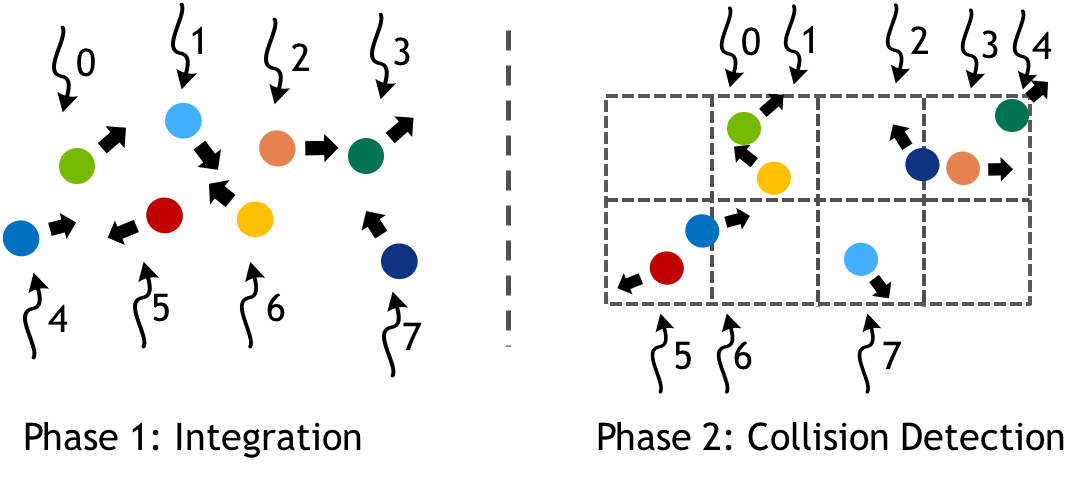
Before Cooperative Groups, implementing such a simulation required multiple kernel launches, because the mapping of threads changes from phase 1 to phase 2. The process of building the regular grid acceleration structure reorders particles in memory, necessitating a new mapping of threads to particles. Such a remapping requires synchronization among threads. The implicit synchronization between back-to-back kernel launches satisfies this requirement, as the following CUDA pseudocode shows.
// threads update particles in parallel integrate<<<blocks, threads, 0, s>>>(particles); // Note: implicit sync between kernel launches // Collide each particle with others in neighborhood collide<<<blocks, threads, 0, s>>>(particles);
Cooperative Groups provides flexible and scalable thread group types and synchronization primitives enable parallelism remapping in situations like the above example within a single kernel launch. The following CUDA kernel provides a sketch of how the particle system update could be updated in a single kernel. The use of this_grid() defines a thread group comprising all threads of the kernel launch, which is then synchronized between the two phases.
__global__ void particleSim(Particle *p, int N) {
grid_group g = this_grid();
// phase 1
for (i = g.thread_rank(); i < N; i += g.size())
integrate(p[i]);
g.sync() // Sync whole grid
// phase 2
for (i = g.thread_rank(); i < N; i += g.size())
collide(p[i], p, N);
}
This kernel is written in such a way that it is trivial to extend the simulation to multiple GPUs, using Cooperative Groups this_multi_grid() to define a thread group spanning all threads of a kernel launch across multiple GPUs, which can be synchronized in the same way. Note that in both cases, the thread_rank() method provides a linear index of the current thread within the thread group, which the kernel uses to iterate over the particles in parallel in case there are more particles than threads.
__global__ void particleSim(Particle *p, int N) {
multi_grid_group g = this_multi_grid();
// phase 1
for (i = g.thread_rank(); i < N; i += g.size())
integrate(p[i]);
g.sync() // Sync whole grid
// phase 2
for (i = g.thread_rank(); i < N; i += g.size())
collide(p[i], p, N);
}
To use groups that span multiple thread blocks or multiple GPUs, applications must use the cudaLaunchCooperativeKernel() or cudaLaunchCooperativeKernelMultiDevice() API, respectively. Synchronization requires that all thread blocks are simultaneously resident, so the application must also ensure that the resource usage (registers and shared memory) of the thread blocks launched does not exceed the total resources of the GPU(s).
Faster Libraries and New Algorithms
CUDA Libraries offer highly optimized, GPU-accelerated algorithms for deep learning, image, video and signal processing, and linear systems, and graph analytics. The libraries continue to drive performance leaps over multi-core CPU alternatives, and focus on strong scaling across multi-GPU dense systems. Here are the key highlights of CUDA 9 libraries.
Volta architecture support: CUDA Libraries are optimized to get the best performance on the Volta platform. Built for Volta and accelerated by Tesla V100 Tensor Cores, cuBLAS GEMMs (Generalized Matrix-Matrix Multiply) achieve up to a 9.3x speedup on mixed-precision computation (SGEMMEx with FP16 input, FP32 computation), and up to 1.8x speedup on single precision (SGEMM). Other CUDA libraries are also optimized to deliver out-of-the-box performance on Volta. A detailed performance report on CUDA 9 libraries will be available in the future.
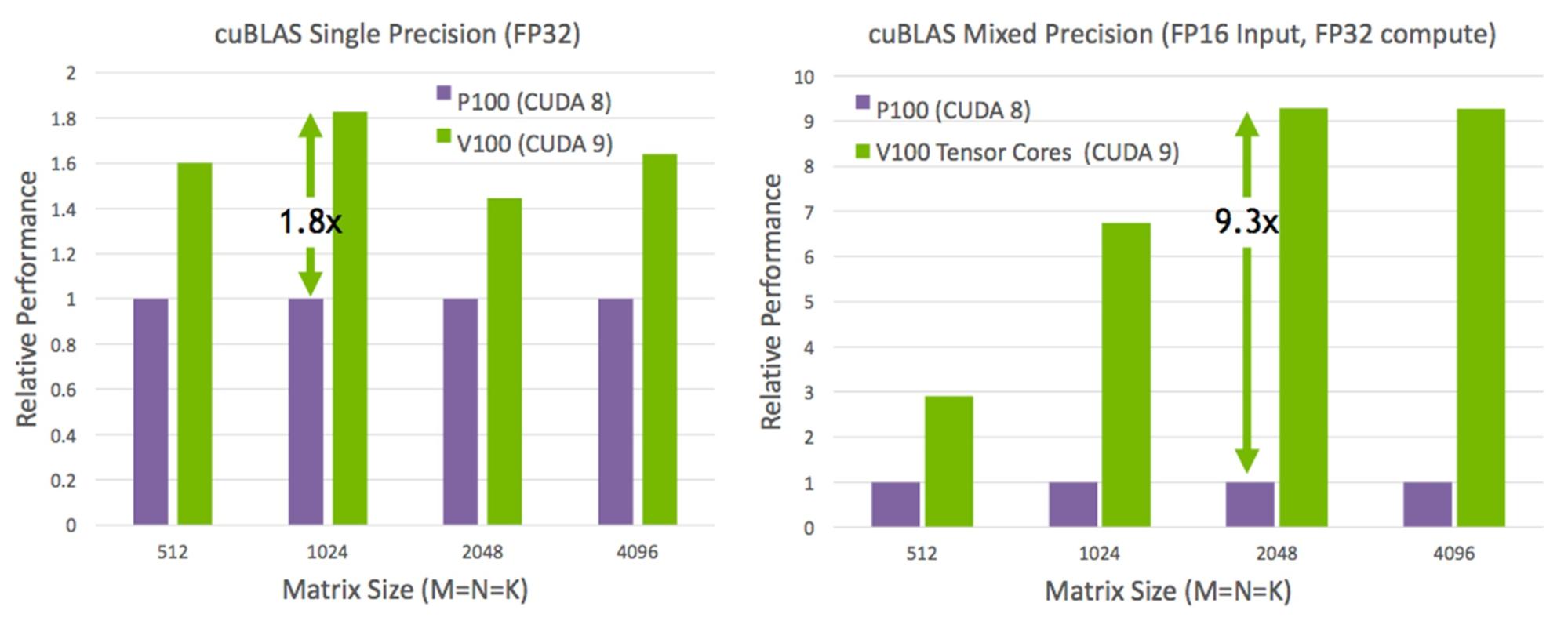
Performance Enhancements: cuBLAS in CUDA 9 includes performance improvements for GEMM (matrix-matrix multiplication) operations that are primarily used in recurrent neural networks (RNNs) and fully connected neural networks (FCNs). This includes optimizations for small matrices and batch sizes, OpenAI GEMM kernels, and heuristics to choose the most optimized GEMM kernel for the inputs.
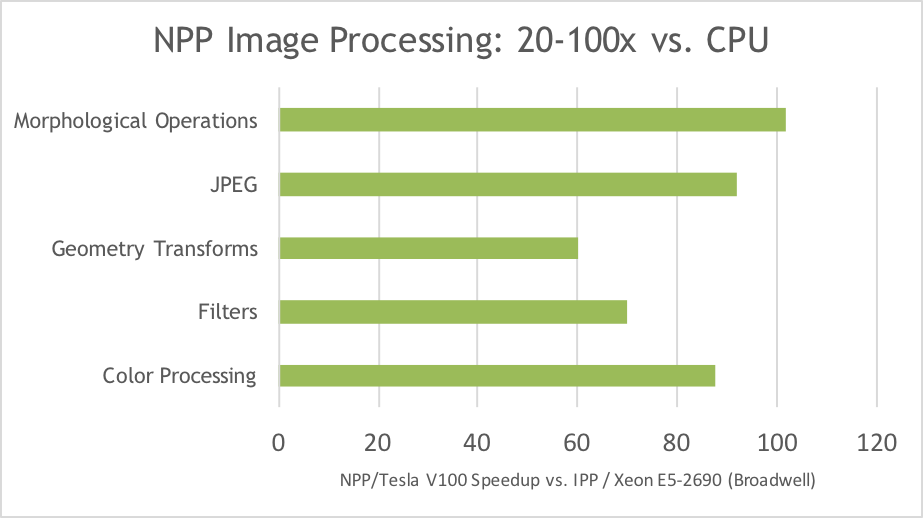
The newly redesigned NPP (NVIDIA Performance Primitives) library in CUDA 9 offers 80-100x speedup over Intel IPP (Figure 4) on image and signal processing functions. New primitives have been added, including support for image batching to boost overall application throughput. NPP has been separated into smaller functional group libraries to reduce the memory footprint in typical usage. CUDA 9 also includes performance improvements in the cuFFT library across various input sizes on single and multi-GPU environments.
New Algorithms: nvGRAPH offers new algorithms that help solve key performance challenges for graph analytics applications. Breadth-first search (BFS) can be used to detect or validate connected components in a graph or to find shortest paths between nodes. nvGRAPH also enables analysis of graphs using maximum modularity clustering. In addition, nvGRAPH supports triangle counting, and graph extraction and contraction for various applications such as community detection, cyber security, and ad tech.
The cuSOLVER library in CUDA 9 includes support for dense eigenvalue and singular value decomposition (SVD) based on the Jacobi Method, as well as sparse Cholesky and LU factorization. Developers of scientific and engineering applications can now use cuSOLVER to quickly and accurately solve eigenvalue problems with a user-specified tolerance.
The cuSPARSE library now supports dense and sparse matrix pruning to allow deep learning networks to safely omit a small percentage of values to improve performance without impacting the overall accuracy.
Improved User Experience: CUDA 9 includes a new install package that allow users to install only library components without installing the entire CUDA toolkit or the driver. These new meta packages provide simple and clean installation of CUDA libraries for deep learning and scientific computing (OpenACC, for example) users that primarily rely on CUDA libraries.
Developer Tools Updates
CUDA 9 includes a number of updates to developer tools to make you more productive in developing accelerated applications. The profiling tools including the NVIDIA Visual Profiler have been updated with support for the Volta architecture. Significantly, profiling applications that use Unified Memory is much easier, thanks to two important features.
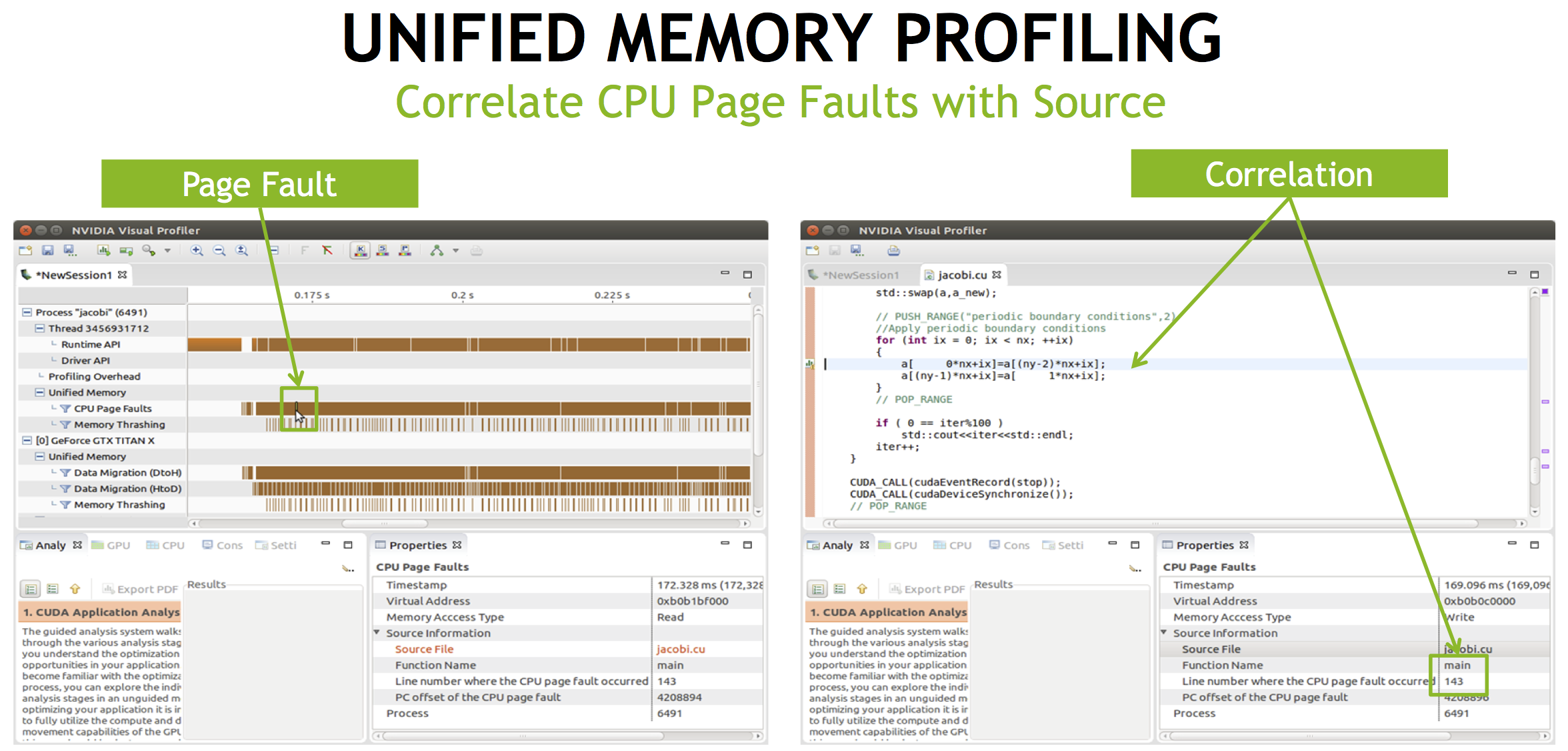
CPU page fault source correlation shows you the exact lines in your source code where CPU accesses to Unified Memory result in page faults, as Figure 5 shows. This can happen when memory regions that reside in device memory are accessed from the host CPU.
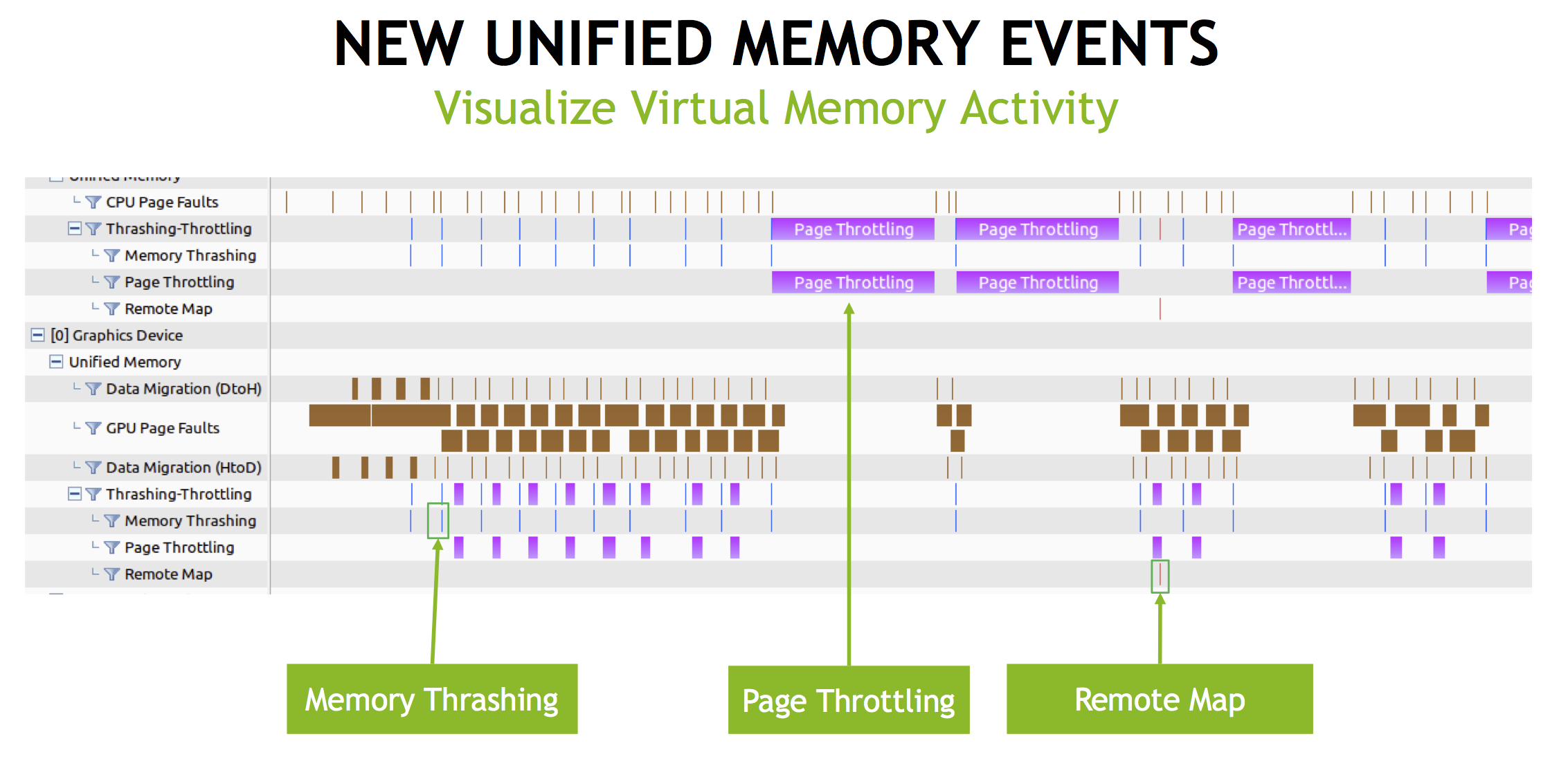
Second, there are three new types of Unified Memory events on the profiler timeline, as Figure 6 shows.
- Page throttling events occur when one of processor has been blocked on a page so that another processor can access the page without interruption.
- Memory thrashing events indicate that two or more processors are “fighting” for a memory region in the virtual address space. Both are accessing the region, causing it to migrate back and forth between the processors’ memories.
- A remote map event occurs when a memory region in the virtual address space has been mapped from one processor to another processor. This is usually done to prevent further thrashing or when no more memory is available on the processor.
Compiler and Language Improvements
With CUDA 9, the nvcc compiler adds support for C++14, which includes new features such as
- Generic lambda expressions, where the
autokeyword is used in place of parameter types;auto lambda = [](auto a, auto b) { return a * b; }; - Return type deduction for functions (using the
autokeyword for the return type as in the preceding example; - Fewer restrictions on what can be included in
constexprfunctions, including variable declarations,if,switch, and looping.
NVCC in CUDA 9 is also faster, reducing compile time on average by 20% and up to 50% compared to CUDA 8.
Programming Tensor Cores
Tesla P100 delivered considerably higher performance for training neural networks compared to the prior generation NVIDIA Maxwell and Kepler architectures, but the complexity and size of neural networks have continued to grow. New networks that have thousands of layers and millions of neurons demand even higher performance and faster training times.
New Tensor Cores are the most important feature of the Volta GV100 architecture to help deliver the performance required to train large neural networks. Tesla V100’s Tensor Cores deliver up to 120 Tensor TFLOPS for training and inference applications. Tensor Cores provide up to 12x higher peak TFLOPS on Tesla V100 for deep learning training compared to P100 FP32 operations, and for deep learning inference, up to 6x higher peak TFLOPS compared to P100 FP16 operations. The Tesla V100 GPU contains 640 Tensor Cores: 8 per SM.
Matrix-Matrix multiplication (BLAS GEMM) operations are at the core of neural network training and inferencing, and are used to multiply large matrices of input data and weights in the connected layers of the network. As Figure 3 shows, Tensor Cores in the Tesla V100 GPU boost the performance of these operations by more than 9x compared to the Pascal-based GP100 GPU.
Tensor Cores and their associated data paths are custom-crafted to dramatically increase floating-point compute throughput at only modest area and power costs. Clock gating is used extensively to maximize power savings.
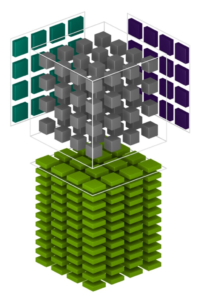
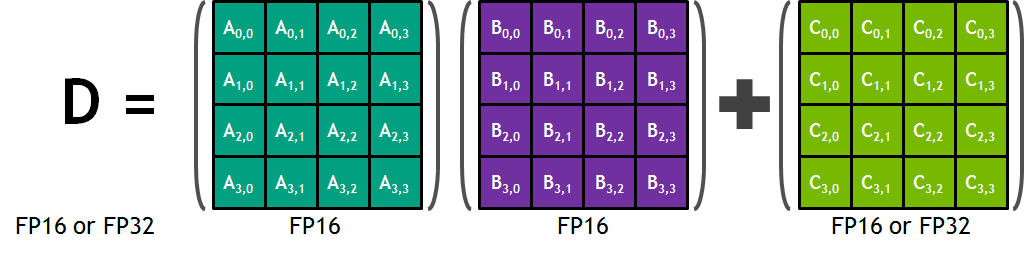
Each Tensor Core provides a 4x4x4 matrix processing array which performs the operation D = A × B + C, where A, B, C, and D are 4×4 matrices as Figure 8 shows. The matrix multiply inputs A and B are FP16 matrices, while the accumulation matrices C and D may be FP16 or FP32 matrices.
Each Tensor Core performs 64 floating point FMA mixed-precision operations per clock (FP16 input multiply with full precision product and FP32 accumulate, as Figure 8 shows) and 8 Tensor Cores in an SM perform a total of 1024 floating point operations per clock. This is a dramatic 8X increase in throughput for deep learning applications per SM compared to Pascal GP100 using standard FP32 operations, resulting in a total 12X increase in throughput for the Volta V100 GPU compared to the Pascal P100 GPU. Tensor Cores operate on FP16 input data with FP32 accumulation. The FP16 multiply results in a full precision result that is accumulated in FP32 operations with the other products in a given dot product for a 4x4x4 matrix multiply, as Figure 9 shows.
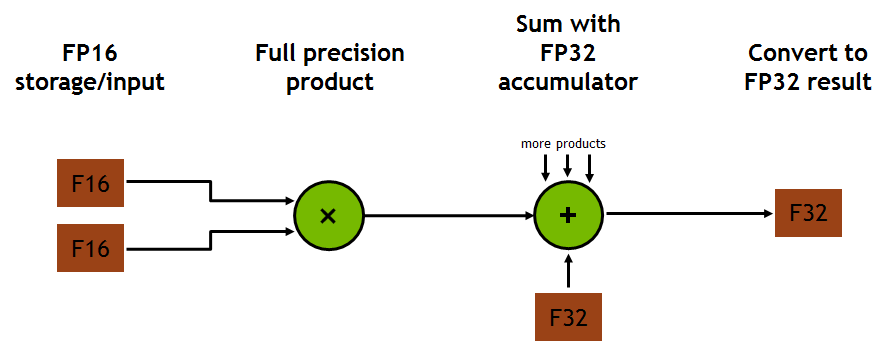
During program execution, multiple Tensor Cores are used concurrently by a full warp of execution. The threads within a warp provide a larger 16x16x16 matrix operation to be processed by the Tensor Cores. CUDA 9 includes a CUDA C++ API for warp-level matrix-multiply and accumulate as a preview feature. These C++ interfaces provide specialized matrix load, matrix multiply and accumulate, and matrix store operations to efficiently utilize Tensor Cores in CUDA C++ programs.
In addition to CUDA C++ interfaces to program Tensor Cores directly, CUDA 9 cuBLAS and cuDNN libraries include new library interfaces to make use of Tensor Cores for deep learning applications and frameworks. NVIDIA has worked with many popular deep learning frameworks such as Caffe2 and MXNet to enable the use of Tensor Cores for deep learning research on Volta GPU based systems. NVIDIA continues to work with other framework developers to enable broad access to Tensor Cores for the entire deep learning ecosystem.
CUDA 9: Powerful Programming for Volta and Beyond
CUDA 9 includes some of the biggest ever advances in GPU programming, including Volta support, the new Cooperative Groups programming model, and much more.
CUDA 9 is now available. Download it today from NVIDIA Developer. For Linux users, NVIDIA provides various installation meta packages to make it easy to install CUDA and the appropriate NVIDIA driver using your Linux package manager (such as yum or APT).
Register for the NVIDIA developer program to get updated on the release and for access to release candidates.