The Turing architecture introduces so many cool new features that it’s easy to miss the quiet revolution in GPU programming that it also represents: all of the features introduced with Volta now exist in a GeForce product. This means more programmers than ever have access to a GPU with Independent Thread Scheduling, the PTX6 memory consistency model, and improved Unified Memory. The result is a programming system that’s leaps ahead of what you’re could do with previous generation GPUs. CUDA on Turing represents a major step forward in GPU-accelerated computing.
I presented a simple message for my talk at this year’s CPPCon conference: if you’re a C++ programmer, try CUDA on Turing.
Let’s reflect on the kind of assumptions that programmers tend to make, as table 1 outlines:
| [PEOPLE THINK] GPUS ARE GOOD FOR: |
[PEOPLE THINK] GPUS ARE BAD FOR: |
| Floats, short floats, and doubles
Arrays (may be multi-dimensional) Coalesced memory access Lock-free algorithms |
Strings
Node-based data structures Random memory walks Starvation-free algorithms (spinlocks) |
These assumptions no longer hold true, driving home the point that Volta and Turing mark a new era for accelerator programming. You can see where I’m going with this, I’m sure, but would you expect e.g. trie3 based algorithms to benefit from GPU acceleration? You probably wouldn’t; historically, you would have been right. But GPUs today have fewer limits in what they can do, and do well.
Sequential example
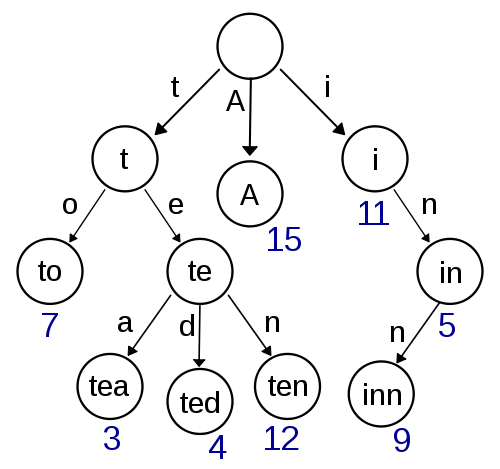
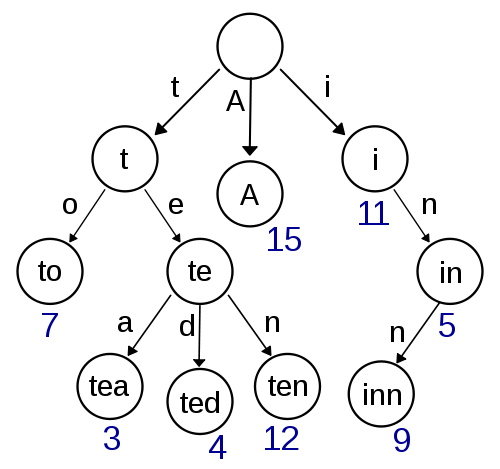
In the world of code samples, a trie is typically a map with a vocabulary of words for keys and the frequency of those words in a text body for values, diagrammed in figure 1.
The code to build this data structure sequentially in C++ is quick and easy to write, as shown below. For brevity, we’ll focus only on the data structure and the build procedure.
struct trie {
// indexed by alphabet (FIXME: add Unicode support ;)
struct ref {
trie* ptr = nullptr;
} next[26];
// mapped value for this position in the tree
int count = 0;
};
int index_of(char c) {
if(c >= 'a' && c <= 'z') return c - 'a';
if(c >= 'A' && c <= 'Z') return c - 'A';
return -1;
};
void make_trie(/* trie to insert word counts into */ trie& root,
/* bump allocator to get new nodes*/ trie*& bump,
/* input */ const char* begin, const char* end) {
auto n = &root;
for(auto pc = begin; pc != end; ++pc) {
auto const index = index_of(*pc);
if(index == -1) {
if(n != &root) {
n->count++;
n = &root;
}
continue;
}
if( n->next[index].ptr == nullptr )
n->next[index].ptr = bump++;
n = n->next[index].ptr;
}
}
Given a text body like public-domain books obtained from Project Gutenberg, we can… try the trie! Let’s see how it performs on a typical server CPU, with results shown in figure 2:
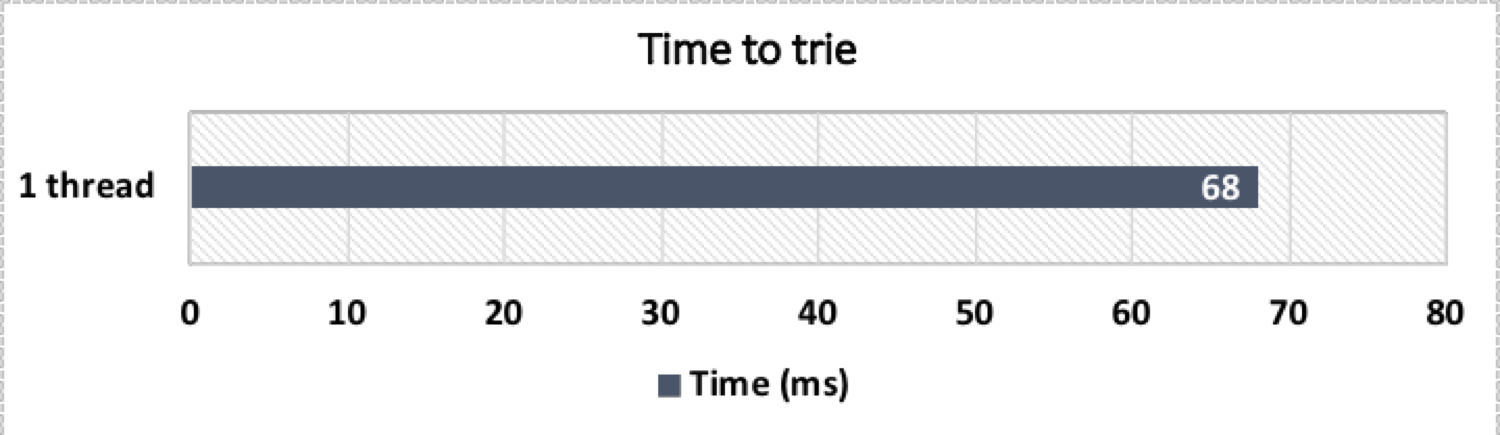
Concurrent example
Scaling this up on a multi-core system takes at least one major change by implementing concurrent insertions into the data structure. Thankfully, modern C++ does much to help in this case. Let’s take a look at a straightforward concurrent version in modern C++.
We apply these modifications to the code (besides launching threads):
- Distribute the input. Perhaps split the range into a number of equal strips using a stride.
- Avoid half-words. Adjust strips to start and end at the nextword (mind the ends).
- Apply sequential version to adjusted strips, except see the code below for insertions.
// every part of the trie will be concurrently accessed struct trie { struct ref { std::atomic<trie*> ptr = ATOMIC_VAR_INIT(nullptr); // the flag will protect against multiple pointer updates std::atomic_flag flag = ATOMIC_FLAG_INIT; } next[26]; std::atomic<int> count = ATOMIC_VAR_INIT(0); }; void make_trie(/* trie to insert word counts into */ trie& root, /* bump allocator to get new nodes*/ std::atomic<trie*>& bump, //< this too /* input */ const char* begin, const char* end, /* thread this invocation is for */ unsigned index, /* how many threads there are */ unsigned domain); // referred above if(n->next[index].ptr.load(std::memory_order_acquire) == nullptr) { if(n->next[index].flag.test_and_set(std::memory_order_relaxed)) // NOTE A while(n->next[index].ptr.load(std::memory_order_acquire) == nullptr); // NOTE B else { auto next = bump.fetch_add(1, std::memory_order_relaxed); n->next[index].ptr.store(next, std::memory_order_release); // NOTE C } } n = n->next[index].ptr.load(std::memory_order_relaxed);
Let’s emphasize a few things in particular:
- This flag’s test-and-set operation indicates which thread is the first to attempt an insertion. That thread proceeds while other threads wait for the insertion to occur.
- The waiting threads wait by spinning. This isn’t a major performance concern because of the low odds of reaching this path and the extremely short duration of the wait.
- The inserting thread must make progress independently from the waiting threads for us to make forward progress at the algorithm level. The block of code shown is equivalent to a spinlock, a starvation-free1 algorithm. (Remember this fact for later.)
This multi-threaded version regresses the single-threaded performance of our test case because atomic operations inhibit some optimizations. Picking up only the multi-threaded results from this version, the performance chart shown in figure 3 using the Xeon CPU becomes:

Concurrent CUDA example
Conceptually, the concurrent version of the algorithm above is the CUDA version also. This is a reasonable expectation because no part of this algorithm necessitates special treatment on modern GPUs, such as Volta and Turing. These GPU designs specifically support starvation-free algorithms and support the memory consistency semantics of C++.
Unfortunately the Standard C++ library does not yet support CUDA. That means the concurrent version won’t simply compile. It minimally needs CUDA support in the freestanding subset of the Standard C++ library. I implemented my own library on Github to show how simple this can be in service of our trie example.
Let’s summarize the C++ support with this library, shown in table 2:
| Host processors can
use alone: |
All processors can
use isolated: |
All processors can use
together: |
| throw catch typeid dynamic_cast thread_local std:: |
virtual functions
function pointers lambdas |
<rest of ISO C++ language>†
simt::std:: freestanding‡ |
†Note some restrictions exist with CUDA support and are documented here. ‡: The restrictions in my version are documented in the Github repo.
Using this library, the CUDA version is virtually unchanged:
// every part of the trie will be concurrently accessed struct trie { struct ref { simt::std::atomic<trie*> ptr = ATOMIC_VAR_INIT(nullptr); // the flag will protect against multiple pointer updates simt::std::atomic_flag flag = ATOMIC_FLAG_INIT; } next[26]; simt::std::atomic<int> count = ATOMIC_VAR_INIT(0); }; __host__ __device__ void make_trie(/* trie to insert word counts into */ trie& root, /* bump allocator to get new nodes*/ simt::std::atomic<trie*>& bump, /* input */ const char* begin, const char* end, /* thread this invocation is for */ unsigned index, /* how many threads there are */ unsigned domain);
We exchanged std:: for simt::std:: in a few places and added some device declarations. Super easy! What was not easy was ensuring that the CUDA C++ programming system would support a program as expressed in such an elegantly simple form as this one.
In particular, support for starvation-free algorithms, noted earlier, with independent thread scheduling is unique to the Volta and Turing generations of GPUs. Add to that the PTX6 memory consistency model that introduced semantics compatible with the ISO C++ memory model, which std::simt::atomic<> depends on. All of this is new since Pascal.
Oh, it’s also significantly faster now. The chart in figure 4 offers an eye-opening perspective on performance.
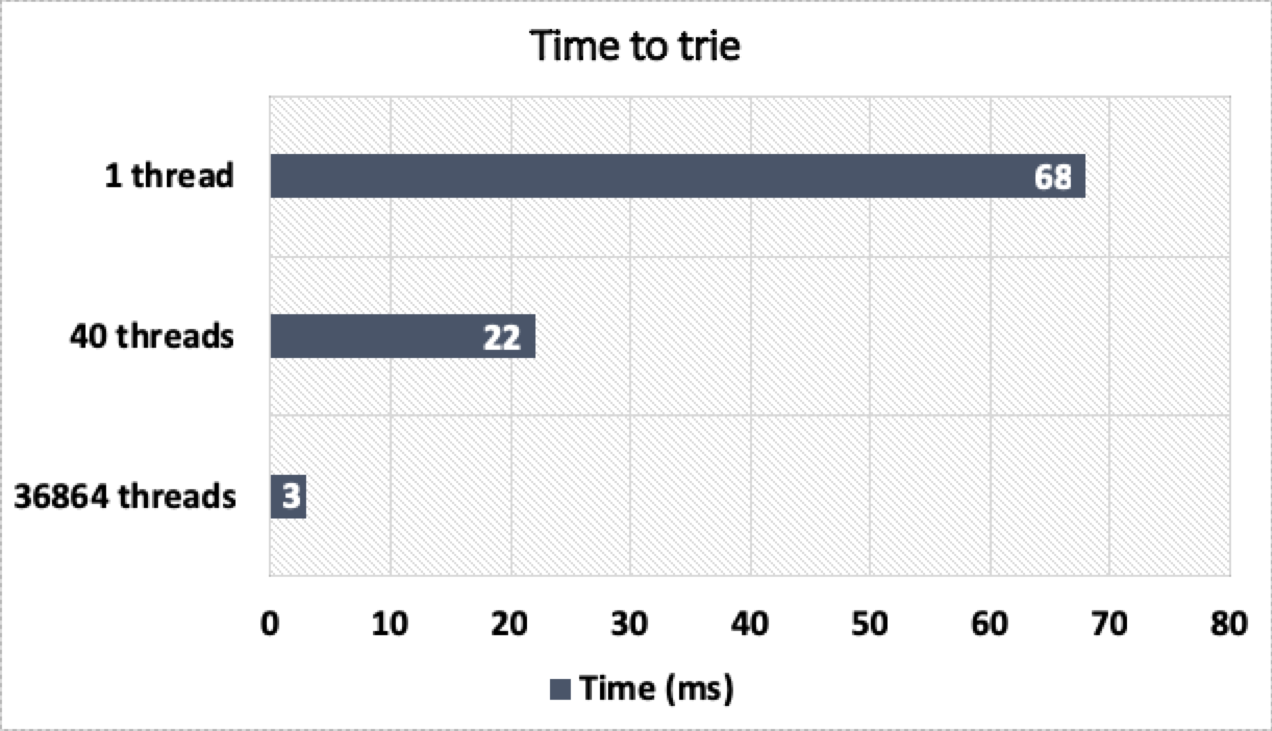
This good result should be unintuitive to most readers. When this algorithm executes, it makes inefficient use of memory and control resources because it heavily diverges. But this procedure also suffers from exposed memory latency—enough for the latency-hiding benefits of the GPU to dominate the more-intuitive downsides.
Conclusion
The kinds of algorithms that Volta and Turing can express and even accelerate are much more varied than previous GPUs.
Independent Thread Scheduling has enabled straightforward implementations of many concurrent algorithms by ensuring progress for algorithms like the spinlock in our example. This not only simplifies concurrent GPU programming but can also improve performance since lock-free algorithms are not always fastest.
Going further, support for the C++ memory consistency model opens the door to CUDA support in Standard C++ library implementations. This support may come in the future, but today you can try my experimental library. All of the code shown above is provided as a sample with this library.
Turing brings the best accelerator programming model to GeForce. You should try it out!
Appendix: CPPCon Presentation
If you’d like to watch the talk I gave at CPPCon, check it out below.
References
[1] Herlihy, M., Shavit, N.: On the nature of progress.