The NVIDIA DGX SuperPOD™ simplifies how the world approaches supercomputing, delivering world-record setting performance that can now be acquired by every enterprise in weeks instead of years. NVIDIA sets the bar once again in supercomputing, building a well-balanced system with 96 NVIDIA® DGX-2H™ servers containing 1,536 NVIDIA Tesla® V100 SXM3 GPUs. The DGX SuperPOD has earned the 22nd spot on the June 2019 TOP500 list.
The combination of NVIDIA accelerated compute architecture, Mellanox network fabric, and system management software comes together with the goal of delivering a solution that democratizes supercomputing power, making it readily accessible, installable, and manageable in a modern business setting.
This post describes key aspects of the DGX SuperPOD architecture including how selected component minimized bottlenecks throughout the system, resulting in the world’s fastest DGX supercomputer. We also discuss details on how the NVIDIA DGX POD™ management software enabled rapid deployment, accelerate on-boarding of users, and simplify system management.
Design
The DGX SuperPOD is optimized for multi-node DL and HPC. It was built using the NVIDIA DGX POD reference architecture, and was configured to be a scalable and balanced system providing maximum performance.
Features of the DGX SuperPOD are described in Table 1.
|
Component |
Technology |
Description |
|
Compute Nodes |
96 NVIDIA DGX-2H servers |
1,536 Tesla V100 SXM3 GPUs 144 TB of HBM2 memory 144 petaFLOPS via Tensor Cores |
|
Compute Network |
Two Mellanox InfiniBand CS7500 Director Class switches |
648 EDR/100 Gbps ports per switch Eight connections per DGX-2H node |
|
Storage Network |
Mellanox InfiniBand CS7510 Director Class switch |
384 EDR/100 Gbps ports Two connections per DGX-2H node |
|
Management Networks |
Arista 7060CX2 and 7010 ethernet switches |
Each DGX-2H server has ethernet connections to both switches |
|
High Speed Storage |
IBM Elastic Storage Server (ESS), GS4S model |
552 TB raw storage > 80 GB/s read performance |
|
Management Software |
GPU infrastructure and automation tools |
|
|
User Runtime Environment |
NGC provides the best performance for all DL frameworks |
|
|
Slurm |
Slurm is used for the orchestration and scheduling of multi-GPU and multi-node training jobs |
The first DGX-2H supercomputer (Circe) consisted of 36 DGX-2H servers and went from concept to results in just three weeks. Its successor, the DGX SuperPOD, represents the buildout of the original DGX-2H supercomputer to 96 servers. Initial system testing used the TOP500 benchmark (HPL) to measure performance and ensure system stability. NVIDIA researchers then ran the MLPerf v0.5 benchmark suite on the system prior to it being put into production. Since then, the latest MLPerf v0.6 has been released.
The system achieved the following results from the HPL and the latest MLPerf v0.61 benchmarks:
- The DGX SuperPOD hit 9.444 petaFLOPS out of 11.311 petaFLOPS peak on the HPL benchmark, making it the 22nd fastest system in the world based on the June 2019 TOP500 list.
- The DGX SuperPOD was used extensively in the NVIDIA submissions for MLPerf v0.6 published in July 2019, where NVIDIA set eight new performance records – three at scale and five in per-accelerator comparisons. You can see all the latest results here.
Network Architecture
The DGX SuperPOD has four networks:
- Compute network. A high-performance network used for scaling DL workload. It contains eight links per node providing 800 Gbps of full-duplex bandwidth.
- Storage network. A high-performance network which provide extra-fast access storage, supporting I/O rates up 200 Gbps per node. It has two links per DGX-2H server.
- In-band management network. An Ethernet-based network provides connectivity between the compute nodes, management nodes, and external network.
- Out-of-band management network. An Ethernet-based network that supports BMC and IPMI.
Figure 1 highlights details of the four networks. We’ll take a look at network details in the following sections.

Compute Network
The high-performance compute network, shown in figure 2, is a 100 Gbps/EDR InfiniBand-based network using Mellanox CS7500 Director Switches. The single CS7500 switch provides a non-blocking network of up to 648 ports. Each DGX-2H server uses eight connections for the compute network. The 96 DGX-2H compute nodes and management servers require nearly 800 ports, requiring two CS7500 switches given the size of the system. Designers carefully considered the network design, maximizing network performance for typical communications traffic of AI workloads, providing some redundancy in the event of network hardware failures, and minimizing cost.
Each GPU has access to two local network ports of the eight connections used for the compute fabric. “Local” means the GPU can reach the network port directly over the PCIe. One of the two ports is a primary port where traffic only traverses a single PCIe switch. The other port can be reached but traverses multiple PCIe switches. It’s ideal to use the network port that is closest, but the other port can be used in the event of a hardware failure on the node or the switching fabric.
The NVIDIA Collective Communications Library (NCCL) is the main communications library for deep learning. It uses rings and trees to optimize the performance of common collective communication operations used by deep learning applications. When communicating with GPUs between hosts, NCCL ensures only GPUs of the same local rank communicate between each other. For example, local rank 2 on one node will only talk to local rank 2 on another node. Consistent mapping of GPUs to local ranks and network ports to GPUs makes sure traffic between processes with the same local rank uses the same network port.
We designed the DGX SuperPOD compute network around the NCCL communication pattern described above to maximize performance, minimize congestion, and be cost efficient. The topology design connects half of the compute network ports to one CS7500 switch and the other half network ports connected to the other CS7500, alternating between ports in order of enumeration. The odd numbered ports connect to one switch and the even numbered ports to the other switch.
Each switch internally is a full-fat tree providing the necessary bandwidth for each rail of the network. One third of the total ports directly connect between each switch to provide connectivity for general HPC application traffic.
The benefits of the topology above are:
- Communication on an individual port stays local to the switch.
- Communication continues in the event of a switch failure.
- HPC-style applications with general communications patterns are still supported with the top-level of the tree oversubscribed at 2-to-1. However, the overall bisection bandwidth of the network is better than this as traffic between odd-to-odd or even-to-even network ports stays local to the switch.
- The system supports up to 108 DGX-2H nodes.
Storage Network
The high-performance storage network consists of a 100 Gbps/EDR InfiniBand-base network using the Mellanox CS7510 Director Switch. Separating the storage traffic on its own network removes network congestion that could reduce application performance and removed the need to purchase a larger switch to support both compute communication and storage needs. The storage network requires approximately 220 ports to support the two connections from each compute node, 28 ports from the ESS nodes, and several additional ports from the management nodes. The CS7510 allows for future upgrades and let other DGX servers connect to the ESS nodes.
Management Networks
The in-band Ethernet network provides several important functions. First, it provides connectivity of all services that manage the cluster. Second, access to the home filesystem and storage pool are provided over the Ethernet network via the NFS protocol. In addition, the ethernet network enables connectivity for in-cluster services such as Slurm and Kubernetes plus other services outside of the cluster, such as the NVIDIA GPU Cloud registry, code repositories, and data sources.
Each DGX-2H server node, IBM Spectrum Scale server nodes, and login/management nodes have one uplink to the In-Band Ethernet network. The In-band network uses Arista 7060CX2 port switches running at 100 Gbps. Two uplinks from each switch connect to the datacenter core switch. Connectivity to external resources and the internet connect from the datacenter core switch.
The out-of-band network handles system management via the BMC as well as providing connectivity to manage all networking equipment. Providing out-of-band management is critical to the operation of the cluster, supplying low usage paths to eliminate conflicts between management traffic and other cluster services. The out-of-band management network uses a single one Gbps Arista 7010 switch. These switches connect directly to the datacenter core switch. In addition, all Ethernet switches connect via serial connections to existing Opengear console servers in the datacenter. These connections provide a means of last resort connectivity to the switches in the event of a network failure.
Storage Architecture
Optimized DL training performance requires a flexible storage architecture. Different filesystem technologies excel at different data access patterns. Local RAM maximizes re-read performance by caching training data. While the fastest option, it is much more expensive than non-volatile storage technologies. Local memory can provide high bandwidth and metadata performance; however, it cannot be shared between multiple nodes.
The DGX SuperPOD uses a hierarchical storage architecture extending from local RAM to long-term storage to balance performance needs and cost of the system. Ideally, all the training data would fit in RAM, maximizing the re-read performance critical to fast DL training. If the training data does not fit into RAM, local storage can be used to store a copy of the training data. While this requires duplication of data across nodes, training performance can still be maximized if the dataset fits in the local storage.
ESS nodes running IBM Spectrum Scale software store active training and other working data. If the internal storage is too small, training can be run effectively from the IBM Spectrum Scale parallel file system. A parallel file system can provide performance often not achievable from other network filesystems. Important differentiators of the IBM Spectrum Scale parallel file system include single-node read bandwidth more than 20 GB/s and single-stream read bandwidth over 5 GB/s. The specific configuration of the Spectrum Scale deployment is:
- 554 TB total flash storage
- Eight storage disk shelves and two ESS nodes
- One management server
- Total of 26 IB ports allocated to the management server and ESS nodes for client data and inter cluster traffic
- One 100 Gbps port allocated on the management server.
- Total of six one Gbps or 10 Gbps ethernet ports allocated for BMC/XCAT.
Note: this is an allocation on internal switch for the appliance.
A long-term storage system archives datasets and older results. Important scripts, source code ,and small data files (typically output and restart files) are stored on the Home filesystem. The Home filesystem is typically configured with a full set of features of the different storage tiers. All data are backed up regularly and advanced features like snapshots allow users to manage their data.
Table 2 summarizes the storage/caching hierarchy. Depending on data size and performance needs, each tier of the hierarchy can be leveraged to maximize application performance.
|
Storage Hierarchy Level |
Technology |
Total Capacity |
Read Performance |
|
RAM |
DDR4 |
1.5 TB per node |
> 100 GB/s |
|
Internal Storage |
NVMe |
30 TB per node |
> 15 GB/s |
|
High-Speed Storage |
IBM SPECTRUM SCALE using SSD |
552 TB |
> 80 GB/s aggregate > 15 GB/s per node |
|
Long Term Storage |
NFS using SSD |
> 1 PB |
10 GB/s aggregate 1 GB/s per node |
|
Home |
NFS using NVMe |
30 TB |
N/A |
AI Software Stack
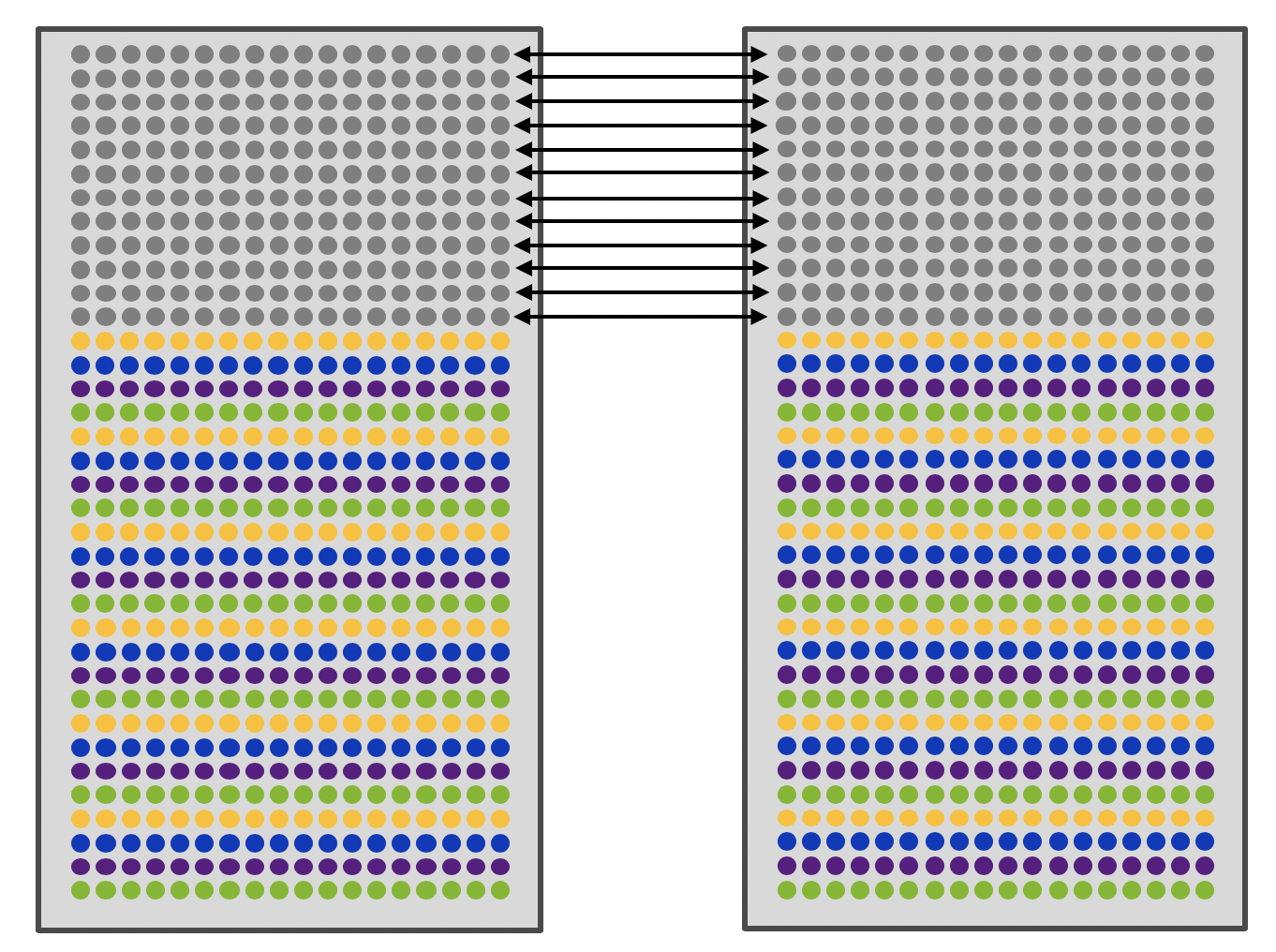
The NVIDIA AI software shown in figure 3 running on the DGX SuperPOD provides a high-performance DL training environment for large scale multi-user AI software development teams. It includes:
- The DGX operating system (DGX OS)
- Cluster management, orchestration tools and workload schedulers (DGX POD management software)
- NVIDIA libraries and frameworks and optimized containers from the NGC container registry.
The DGX POD management software includes third-party open-source tools recommended by NVIDIA which have been tested to work on DGX-2 POD racks with the NVIDIA AI software stack to provide additional functionality. Support for these tools can be obtained directly through third-party support structures.

The DGX OS is the foundation of the NVIDIA AI software stack, built on an optimized version of the Ubuntu Linux operating system and tuned specifically for the DGX hardware. The DGX OS software includes certified GPU drivers, a network software stack, pre-configured NFS caching, NVIDIA datacenter GPU management (DCGM) diagnostic tools, GPU-enabled container runtime, NVIDIA CUDA® SDK, cuDNN, NCCL and other NVIDIA libraries, plus support for NVIDIA GPUDirect™ technology.
Figure 4 shows The DGX POD management software, which is composed of various services running on the Kubernetes container orchestration framework for fault tolerance and high availability. Services provided include network configuration (DHCP) and fully-automated DGX OS software provisioning over the network (PXE). The DGX OS software can be automatically re-installed on demand by the DGX POD management software.
The DGX POD management software leverages the Ansible configuration management tool. Ansible roles install Kubernetes on the management nodes, install additional software on the login and DGX servers, configure user accounts, configure external storage connections, install Kubernetes and Slurm schedulers. These roles also perform day-to-day maintenance tasks, such as new software installation, software updates, and GPU driver upgrades.
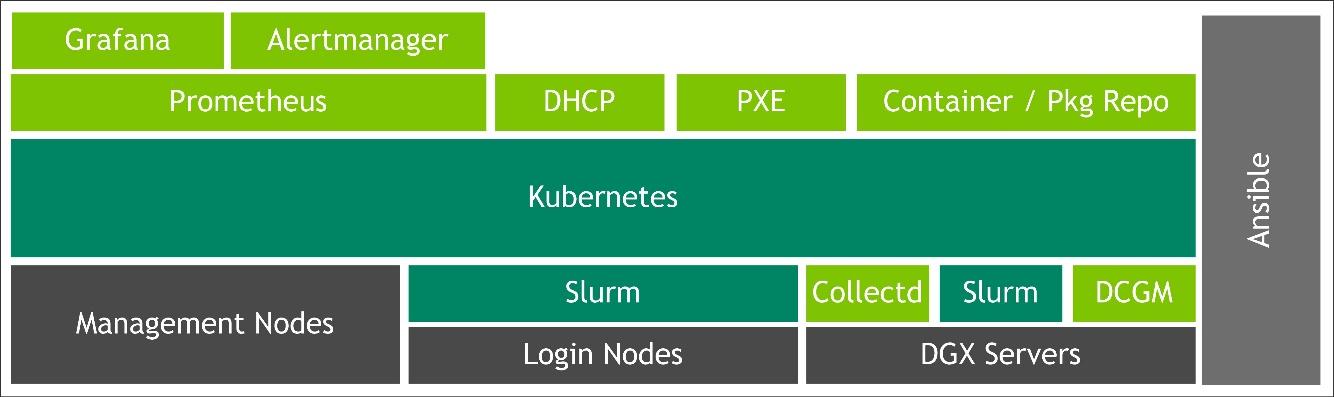
DGX SuperPOD monitoring utilizes Prometheus for server data collection and storage in a time-series database. Alertmanager configures cluster-wide alerts and the Grafana web interface displays system metrics. For sites required to operate in an air-gapped environment or needing additional on-premises services, a local container registry mirroring NGC containers, as well as Ubuntu and Python package mirrors, can be run on the Kubernetes management layer to provide services to the cluster.
Kubernetes runs management services on management nodes. Slurm runs user workloads and is installed on the login node as well as the DGX compute nodes. Slurm provides advanced HPC-style batch scheduling features including multi-node scheduling.
You can find the software management stack and documentation as an open source project on GitHub.
User workloads on the DGX SuperPOD primarily employ containers from NGC, as figure 5 shows. These containers provides researchers and data scientists with easy access to a comprehensive catalog of GPU-optimized software for DL, HPC applications, and HPC visualization that take full advantage of the GPUs. The NGC container registry includes NVIDIA tuned, tested, certified, and maintained containers for the top DL frameworks such as TensorFlow, PyTorch, and MXNet. NGC also has third-party managed HPC application containers, and NVIDIA HPC visualization containers.

Users access the system via a login node. The login node supplies a user environment to edit code, access external code repositories, compile code as needed, and build containers. Training jobs are management via Slurm. Training jobs run in containers, but the system also supports bare metal jobs.
Installation and Management
The DGX-2H supercomputer deployment is similar to deploying traditional servers and networking in a rack. However, the high-power consumption and corresponding cooling needs, server weight, and multiple networking cables per server, need additional care and preparation for a successful deployment. As with all IT equipment installation, it is important to work with the datacenter facilities team to ensure the environmental requirements can be met.
The supercomputer consists of 32 racks:
- Compute-1: 15 racks, with each having four DGX-2H servers
- Compute-2: 12 racks, with each having three DGX-2H servers
- Storage: one rack for the IBM ESS nodes
- InfiniBand Compute: two racks for the two Mellanox CS 7510 InfiniBand switches
- InfiniBand Storage: one rack for the Mellanox CS 7500 InfiniBand switch. The InfiniBand storage rack also contains management servers and ethernet networking switches.
- Utility: One rack for the management servers and ethernet networking switches
Compute racks were distributed such that no more than three were on a given power bus.
Figure 6 shows the rack placement.
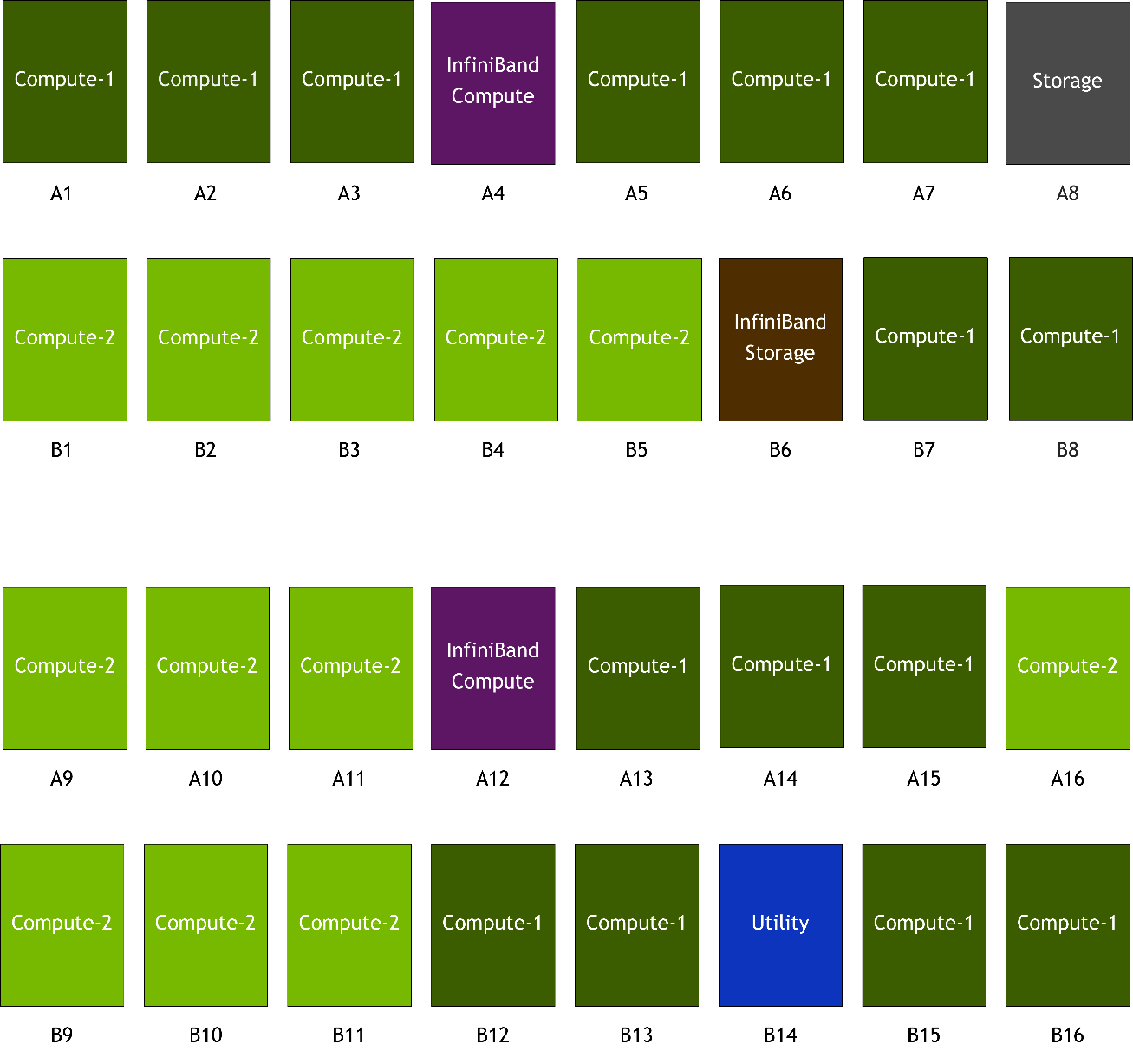
Table 3 contains power requirements for the specified rack elevations. Additional DGX site requirements are detailed in the NVIDIA DGX-2 Server User Guide.
|
Description |
Rack Position |
Number of Racks |
Power Consumed (kW) |
|
| Per Rack | Total | |||
|
Compute-1 4 DGX-2H servers |
A1-A3, A5-A7, A9=A11,A16 B7-B8, B12-B13, B5- B16 |
15 |
44 |
660 |
|
Compute-2 3 DGX-2H servers |
A9-A11, A16 B1-B5, B9-B11 |
12 |
33 |
396 |
|
Storage |
A8 |
1 |
11.6 |
11.6 |
|
InfiniBand Compute |
A4, A12 |
2 |
18.7 |
37.4 |
|
InfiniBand Storage |
B6 |
1 |
16.2 |
16.2 |
|
Utility |
B14 |
1 |
4.6 |
4.6 |
|
Total |
1,125.8 | |||
The racks are air-cooled (without liquid assist). The deployment uses 48U racks to accommodate four DGX-2H servers and minimize the effects of dynamic (velocity) pressure for the power-dense racks.
The design guidelines above can be modified to meet local datacenter requirements. Options include reducing the number of DGX-2H servers per rack, adding additional in-rack fans, and adding rear-door (liquid) heat exchangers.
Summary
NVIDIA DGX SuperPOD based on the DGX-2H server marks a major milestone in the evolution of supercomputing, offering a solution that any enterprise can acquire and deploy to access massive computing power to propel business innovation. As demonstrated by its TOP500 and record-breaking MLPerf v0.6 results, organizations now have a modular, cost-effective and scalable approach that eliminates the design complexity and protracted deployment cycle associated with traditional supercomputing technology.
References
1MLPerf v0.6 submission information: Per accelerator comparison using reported performance for NVIDIA DGX-2H servers (16 Tesla V100 GPUs) compared to other submissions at same scale except for MiniGo where the NVIDIA DGX-1 servers (eight Tesla V100 GPUs) submission was used.
MLPerf ID Max Scale: Mask R-CNN: 0.6-23, GNMT: 0.6-26, MiniGo: 0.6-11 | MLPerf ID Per Accelerator: Mask R-CNN, SSD, GNMT, Transformer: all use 0.6-20, MiniGo: 0.6-10. See mlperf.org for more information.