DIGITS is an interactive deep learning development tool for data scientists and researchers, designed for rapid development and deployment of an optimized deep neural network. NVIDIA introduced DIGITS in March 2015, and today we are excited to announce the release of DIGITS 2, which includes automatic multi-GPU scaling. Whether you are developing an optimized neural network for a single data set or training multiple networks on many data sets, DIGITS 2 makes it easier and faster to develop optimized networks in parallel with multiple GPUs.
Deep learning uses deep neural networks (DNNs) and large datasets to teach computers to detect recognizable concepts in data, to translate or understand natural languages, interpret information from input data, and more. Deep learning is being used in the research community and in industry to help solve many big data problems such as similarity searching, object detection, and localization. Practical examples include vehicle, pedestrian and landmark identification for driver assistance; image recognition; speech recognition; natural language processing; neural machine translation and mitosis detection.
This is a short sample clip promoting a 7 minute introduction to the DIGITS 2 deep learning training system. Watch the full-length video.
DNN Development and Deployment with DIGITS
Developing an optimized DNN is an iterative process. A data scientist may start from a popular network configuration such as “AlexNet” or create a custom network, and then iteratively modify it into a network that is well-suited for the training data. Once they have developed an effective network, data scientists can deploy it and use it on a variety of platforms, including servers or desktop computers as well as mobile and embedded devices such as Jetson TK1 or Drive PX. Figure 1 shows the overall process, broken down into two main phases: development and deployment.
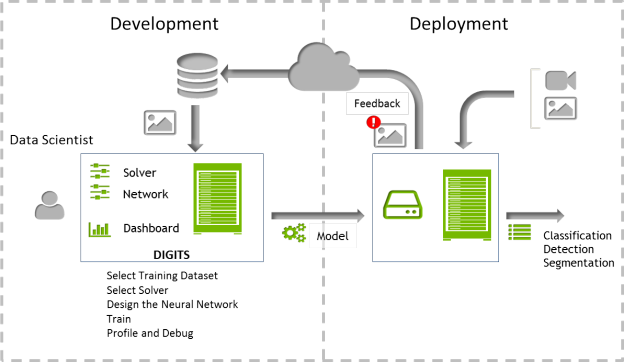
DIGITS makes it easy to rapidly develop an optimized DNN, by providing interactive adjustments for the network parameters needed to develop and train the best DNN for your dataset. With DIGITS it is easy to create new datasets and select them for training; during the DNN development process, DIGITS lets you append new data to a dataset or inflate the data to account for variations in object orientation or other distortions that may occur in the model’s deployed environment.
Solver parameters such as learning rate and policy are also easy to adjust, and the batch size and cadence of the accuracy test can be quickly modified. DIGITS provides the flexibility to train with a standard network, to modify or fine tune an existing network, or to create a custom network from scratch. Once configuration is complete, you’re ready to start training. While training, DIGITS displays the accuracy of the network, helping you make decisions about its performance in real time, and if needed, terminate the training and reconfigure the network parameters.
Once you have developed an effective network, DIGITS can bundle all of the network files into a single download. This makes it easy to deploy an optimized network to any device. If there are misclassifications or a new category needs to be added in the future, it is easy to adjust the network, retrain and then redeploy it.
Let’s take a look at the new features in DIGITS 2.
Train Networks Faster with Multiple GPUs
DIGITS 2 enables automatic multi-GPU scaling. With just a few clicks, you can select multiple GPUs. As datasets get larger, training with more GPUs allows networks to ingest more data in less time, saving precious time during the development process. This easy-to-use feature is visible near the bottom of the the New Image Classification Model page, shown in Figure 2.
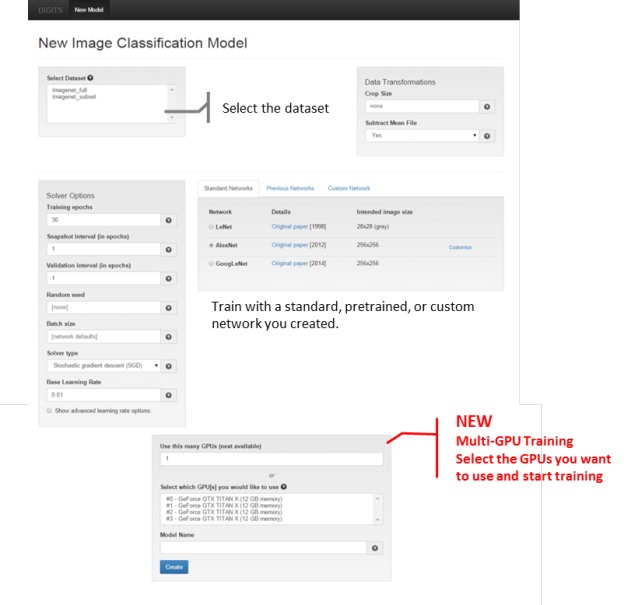
DIGITS can train multiple networks on the same data set in parallel, or train the same network on multiple datasets in parallel. With the GPU selection option, you can select the GPUs to use for training each data set, making it easier to multi-task with your hardware.
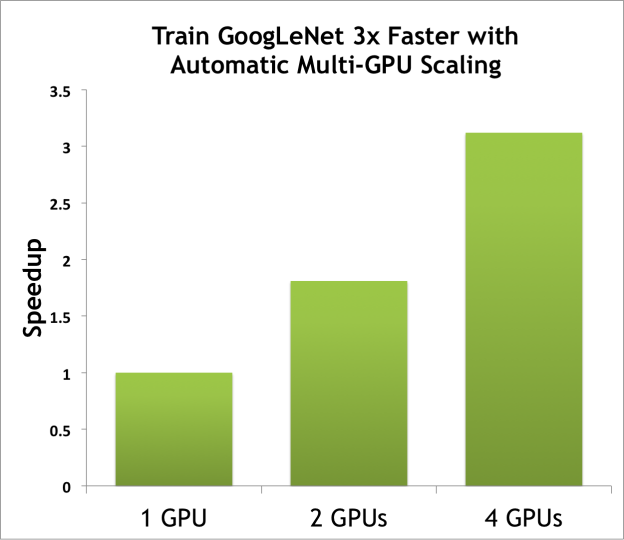
Figure 3 shows how using multiple GPUs can reduce training time. The graph plots the speedup for training GoogleNet on 1, 2 and 4 GPUS with a batch size of 128. These results were obtained with a DIGITS DevBox using GeForce TITAN X GPUs and the Caffe framework.
New Solvers
DIGITS 2 adds two new solvers: adaptive gradient descent (ADAGRAD) and Nesterov’s accelerated gradient descent (NESTEROV). These are selectable along with standard stochastic gradient descent from the Solver Type drop-down menu on the left hand side of the New Image Classification Model window.
The Solver Options pane, shown in Figure 2, lets you configure the snapshot interval, validation interval, batch size, and learning rate policies for the solver.
GoogLeNet Standard Network
GoogLeNet won the classification and object recognition challenges in the 2014 ImageNet LSVRC competition. This standard network is listed with the two others, LeNet and AlexNet, in the Standard Networks pane shown in Figure 2. Some users like to begin their network optimization process with a standard network, and then customize it based on results. Like the other standard networks, LeNet and AlexNet, GoogleNet is a great starting place for developing the optimum DNN for a data set.
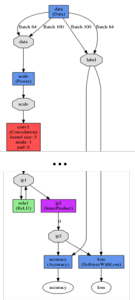
The Custom Network edit box (Figure 2) has settings for the layers, activation function (ReLU, TANH, or sigmoid), and bias value. Selecting the Visualization button on the Custom Network tab is a quick and easy way to view modifications before training. Figure 4 shows the visualization of the standard LeNet network.
Improved Visualization and Monitoring
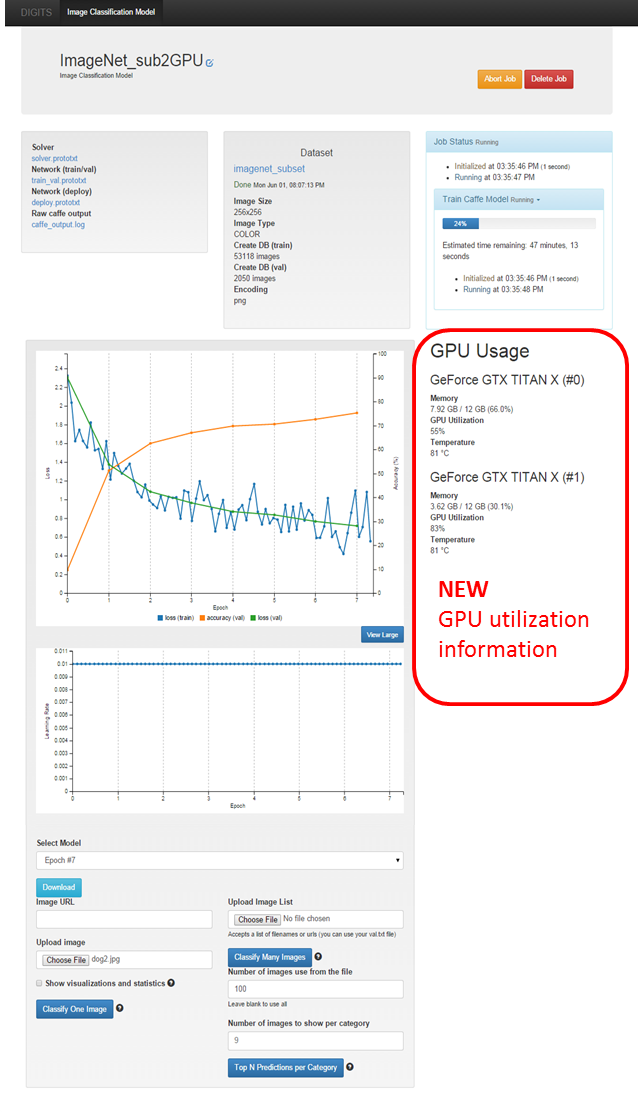
During training, DIGITS 2 now shows the utilization of all GPUs in use in the training window as Figure 5 shows. The utilization, memory, and temperature of the GPU are posted in the training window next to the network performance plot. This allows you to monitor GPU usage in real time during training, even without direct access to the host machine DIGITS is running on. You can easily halt training if you find that the GPUs are under-utilized, and go back to the New Image Classification Model window and adjust network parameters such as batch size.
Classification During Training
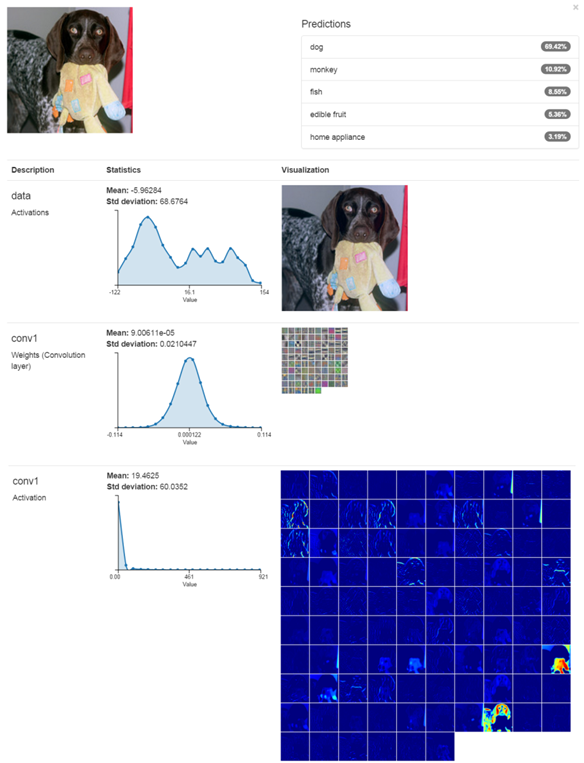
DIGITS can quickly perform classification during the training process with the Classify One Image button at the bottom of the training window (Figure 5). With Show Visualizations and Statistics selected, DIGITS plots the weights and responses of the network from the input image. Figure 6 shows example output from the first layer. In addition to the network responses, DIGITS now plots statistical information alongside each layer parameter, including the frequency, mean, and standard deviation. This helps you understand the overall response of the network from the input image. The classification results displayed along the left hand side show the input image and response from the first convolutional layer including the weights, activations, and statistical information.
Deploying with DIGITS
It’s easy to download a trained network and deploy on another system. Use the Download button near the bottom of the trained model window to get a copy of all the necessary network files needed for deploying a model to new hardware. There are two new example scripts provided with DIGITS 2 under ${DIGITS_ROOT}/examples/classification. One works directly with the .tar.gz file downloaded from DIGITS, and another that allows specification of the network files to use. Example commands for these scripts are shown below.
./use_archive.py DIGITS_Network_files.tar.gz path/to/image.jpg
./example.py network_snapshot.caffemodel deploy.prototxt image.jpg -l labels.txt -m mean.npy
Get Started with DIGITS 2 Today
A preview build of DIGITS 2 that includes all capabilities described in this post is available today. Convenient installation packages are available on the NVIDIA developer website.
The full list of features and changes is in the DIGITS release notes. To learn more about DIGITS, sign up for the upcoming webinar, “Introducing DIGITS 2”. You can also read my post about the first DIGITS release.
To access the DIGITS source code or contribute to the DIGITS project, please visit the open source repository at on GitHub. For questions, feedback and interaction with the DIGITS user community, please visit the DIGITS mailing list or email digits-users@googlegroups.com.