As part of our autonomous driving research, NVIDIA has created a deep-learning based system, known as PilotNet, which learns to emulate the behavior of human drivers and can be deployed as a self-driving car controller. PilotNet is trained using road images paired with the steering angles generated by a human driving a data-collection car. It derives the necessary domain knowledge from data. This eliminates the need for human engineers to anticipate what is important in an image and to foresee all the necessary rules for safe driving. Road tests demonstrated that PilotNet can successfully perform lane keeping in a wide variety of driving conditions, regardless of whether lane markings are present or not.

In order to understand which objects determine PilotNet’s driving decisions we have built visualization tools that highlight the pixels that are most influential for PilotNet’s decisions. The visualization shows that PilotNet learns to recognize lane markings, road edges, and other vehicles even though PilotNet was never explicitly told to recognize these objects. Remarkably, PilotNet learns which road features are important for driving simply by observing human drivers’ actions in response to a view of the road.
In addition to learning the obvious features such as lane markings, PilotNet learns more subtle features that would be hard to anticipate and program by engineers, for example, bushes lining the edge of the road and atypical vehicle classes.
This blog post is based on the NVIDIA paper Explaining How a Deep Neural Network Trained with End-to-End Learning Steers a Car. Please see the original paper for full details.
Training the PilotNet Self-Driving Car System
A previous blog post describes an end-to-end learning system for self-driving cars in which a convolutional neural network (CNN) is trained to output steering commands given input images of the road ahead. This system is now called PilotNet.
The training data consists of images from a front-facing camera in a data collection car coupled with the time-synchronized steering angle recorded from a human driver. The motivation for PilotNet was to eliminate the need for hand-coding rules and instead create a system that learns by observing. Initial results are good, although major improvements are still required before such a system can drive without the need for human intervention.
Explaining PilotNet’s Decisions
To gain insight into how the learned system decides what to do, and thus both enable further system improvements and to create trust that the system is paying attention to the essential cues for safe steering, we developed a simple method for highlighting those parts of an image that are most salient in determining steering angles. We call these salient image sections the salient objects. See our recent paper for the details of the saliency detection method. Several different methods for finding saliency have been described by other authors but we believe the simplicity of our method, its fast execution on our test car’s NVIDIA DRIVE™ PX 2 AI car computer, along with its nearly pixel- level resolution, makes it especially advantageous for our task.
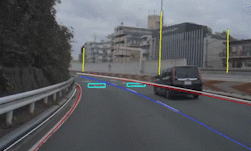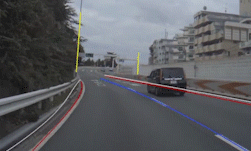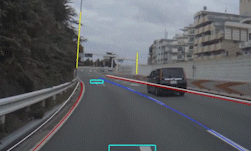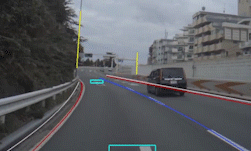
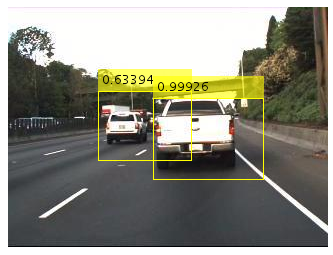
Figures 1 and 2 show results for various input images. Notice that in Figure 1 the bases of cars are highlighted as well as lane-indicator lines (dashed and solid), while a nearly horizontal line from a crosswalk is ignored. In the top image of Figure 2 there are no lanes painted on the road, but the parked cars—which indicate the edge of the drivable part of the road—are highlighted. In the lower image of Figure 2 the grass at the edge of the road is highlighted. Without any coding, these detections show how PilotNet mirrors the way human drivers would use these visual cues.

Figure 3 shows a view inside our test car (left). At the top of the image we see the actual view through the windshield. A PilotNet monitor is at the bottom center displaying diagnostics. Figure 3 further shows a blowup of the PilotNet monitor (right). The top image is captured by the front-facing camera. The green rectangle outlines the section of the camera image that is fed to the neural network. The bottom image displays the salient regions. Note that PilotNet identifies the partially occluded construction vehicle on the right side of the road as a salient object. To the best of our knowledge, such a vehicle, particularly in the pose we see here, was never part of the PilotNet training data.

Analysis
While the salient objects found by our method clearly appear to be ones that should influence steering, we conducted a series of experiments to validate that these objects actually do control the steering. To perform these tests, we segmented the input image that is presented to PilotNet into two classes.
Class 1 is meant to include all the regions that have a significant effect on the steering angle output by PilotNet. These regions include all the pixels that correspond to locations where the visualization mask is above a threshold. These regions are then dilated by 30 pixels to counteract the increasing span of the higher-level feature map layers with respect to the input image. The exact amount of dilation was determined empirically. The second class includes all pixels in the original image minus the pixels in Class 1.
If the objects found by our method indeed dominate control of the output steering angle, we would expect the following: if we create an image in which we uniformly translate only the pixels in Class 1 while maintaining the position of the pixels in Class 2 and use this new image as input to PilotNet, we would expect a significant change in the steering angle output. However, if we instead translate the pixels in Class 2 while keeping those in Class 1 fixed and feed this image into PilotNet, then we would expect minimal change in PilotNet’s output.
Figure 4 illustrates the process described above. The top image shows a scene captured by our data collection car. The next image shows highlighted salient regions that were identified using the method described. The next image shows the salient regions dilated. The bottom image shows a test image in which the dilated salient objects are shifted. The above predictions are indeed born out by our experiments.
 Figure 4. Images used in experiments to show the effect of image-shifts on steer angle.
Figure 4. Images used in experiments to show the effect of image-shifts on steer angle.
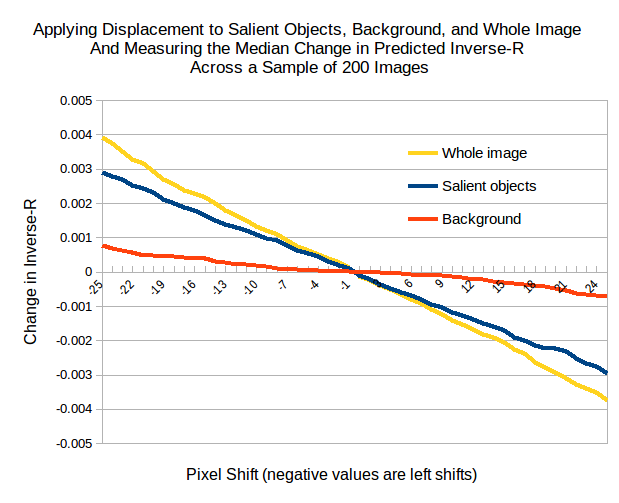
Figure 5 shows plots of PilotNet steering output as a function of pixel shift in the input image. The blue line shows the results when we shift the pixels that include the salient objects (Class 1). The red line shows the results when we shift the pixels not included in the salient objects. The yellow line shows the result when we shift all the pixels in the input image.
Conclusions
These results substantially contribute to our understanding of what PilotNet Learns. Examination of the salient objects shows that PilotNet learns features that “make sense” to a human, while ignoring structures in the camera images that are not relevant to driving. This capability is derived from data without the need of hand-crafted rules. In fact, PilotNet learns to recognize subtle features which would be hard to anticipate and program by human engineers, such as bushes lining the edge of the road and atypical vehicle classes.
For full details please see the paper that this blog post is based on, and please contact us if you would like to learn more about NVIDIA’s autonomous vehicle platform!