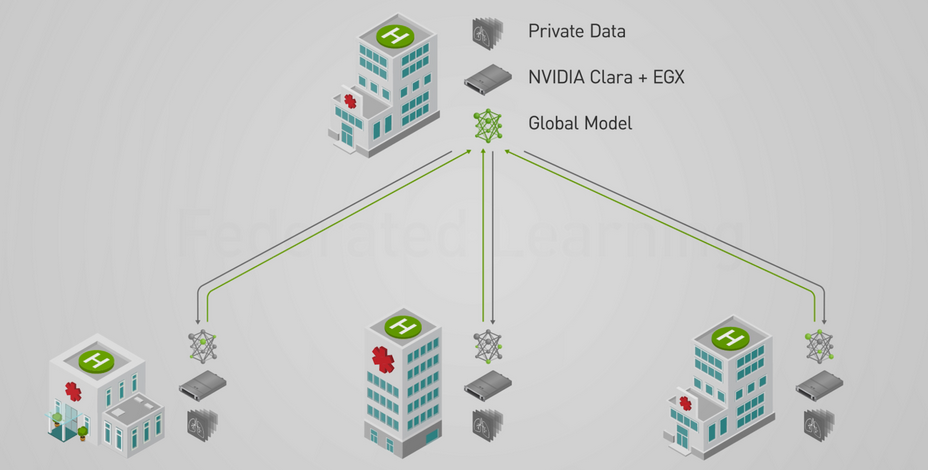
AI requires massive amounts of data. This is particularly true for industries such as healthcare. For example, training an automatic tumor diagnostic system often requires a large database in order to capture the full spectrum of possible anatomies and pathological patterns.
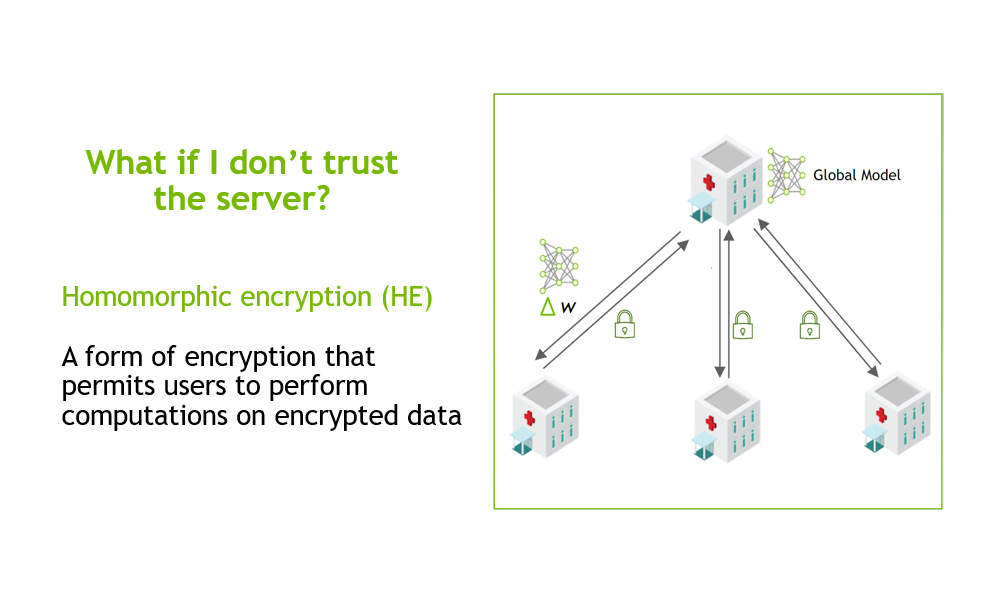
In order to build robust AI algorithms, hospitals and medical institutions often need to collaboratively share and combine their local knowledge. However, this is challenging because patient data is private by nature. It is vital to train the algorithms without compromising privacy.
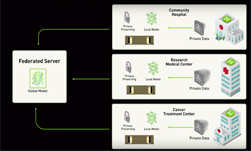
NVIDIA’s latest release of Clara Train SDK, which features Federated Learning (FL), makes this possible with NVIDIA EGX, the edge AI computing platform. The common collaborative learning paradigm enables different sites to securely collaborate, train, and contribute to a global model. Since only partial model weights are shared with the global model from each site, privacy can be preserved and the data is less exposed to model inversion [Paper ref].
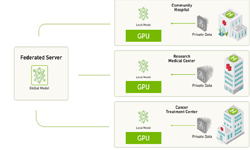
Federated Learning can be implemented in different distributed architectures, including peer-to-peer, to cyclic and server-client. NVIDIA Clara’s implementation is based on a server-client approach, which means that a centralized server acts as a facilitator for the overall federated training with the participation of various clients. The configurable MMAR (Medical Model ARchive) feature of Clara Train SDK makes it possible for developers to bring their own models and components to perform Federated Learning and also have control over whether the local training is run on a single GPU or multiple GPUs.
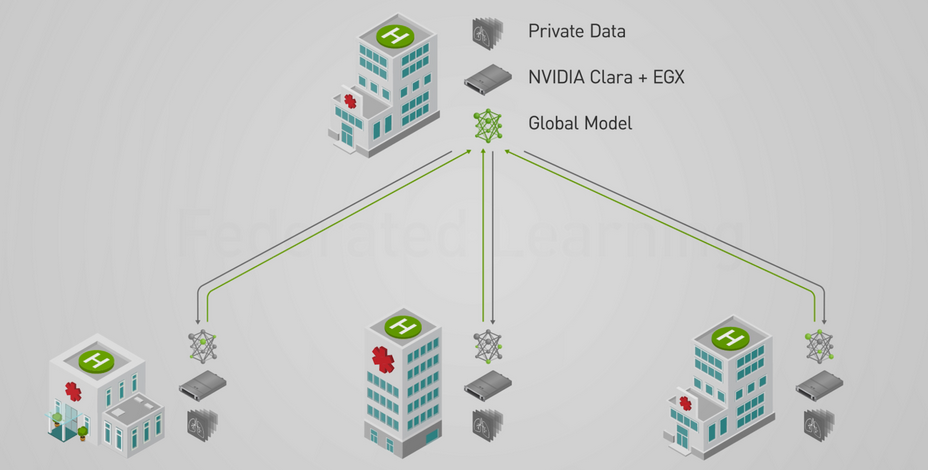
A server manages the overall model training progress and broadcasts the original model to all the participating clients. Model training happens locally on each client’s side so the server doesn’t need access to the training data. Clients only share partial model-weight updates instead of the data. Each client has their own privacy controls on the percentage of the model weights sent to the server for aggregation.
Once the server receives the latest round of models from the clients, it builds its own algorithm on how to aggregate the model. It could be a simple average from all the clients, or based on some weights from the historical contributions from the clients.
The server has overall control of how many rounds of federal learning training to conduct. Participating clients can be added or removed during any round of the training. Federated Learning provides benefits for every participant: a robust, more generalizable centralized model, and more accurate local models.
Federated Learning SYSTEM ARCHITECTURE
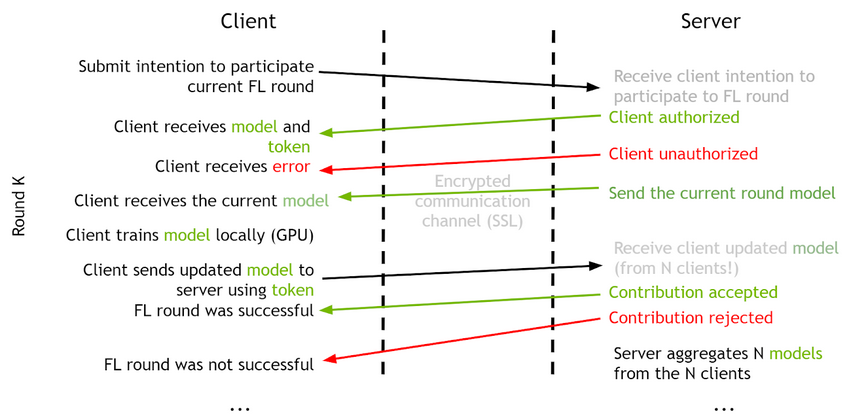
When Federated Learning model training is running, clients must first start a server training service. The server session controls the minimum number of clients needed to start a round of training and the maximum number of clients that can join a round. If a client intends to join a Federated Learning session, they must first submit a login request to apply for training. The server will check the credentials of the client and perform the authentication process to validate the client. If the authentication is successful, the server sends a Federated Learning token back to the client for use in the following client-server communication. If the client can not be authenticated, it sends an authentication rejection.
The clients have control over the number of epochs to run during each round of Federated Learning training. Once the client finishes the current round of training, they can send the updated model to the server using the existing Federated Learning token. After the server receives all the updated models from all the participating clients, it performs the model aggregation based on the weights algorithms and receives the overall updated training model. This completes the current round of the Federated Learning training, the next round is triggered and this continues until the maximum rounds set on the server are completed.
SERVER-CLIENT COMMUNICATION PROTOCOL
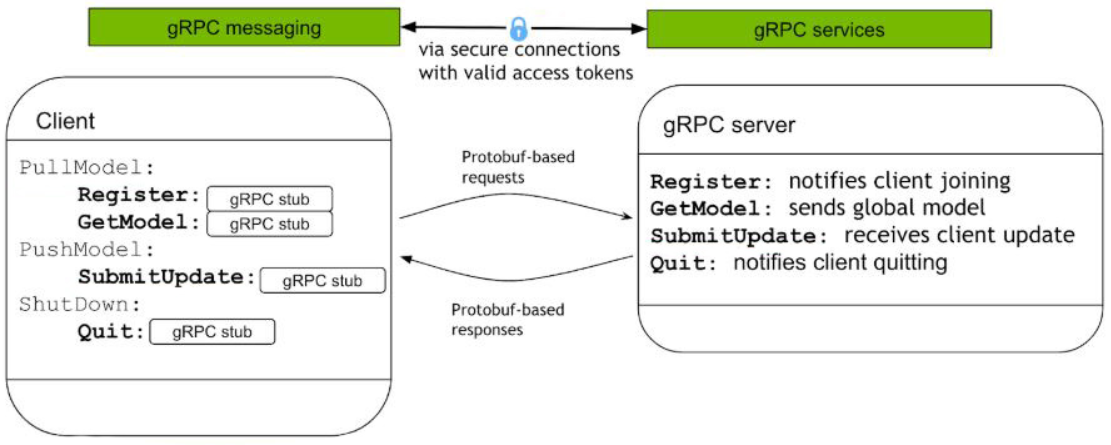
NVIDIA Clara’s Federated Learning uses the gPRC protocol between the server and clients during model training. There are 4 basic commands during the model training session:
| Register | Client notifies the intent to join a Federated Learning training. The server performs the client authentication and returns a Federated Learning token back to the client. |
| GetModel | Acquires the model of the current round from the server. The server checks the token, and sends back the global model to the client. |
| SubmitUpdate | Sends the updated local model after the current round of Federated Learning training to the server for the aggregation. |
| Quit | The command to use when the client decides to quit from the current Federated Learning model training. |
SERVER-SIDE WORKFLOW
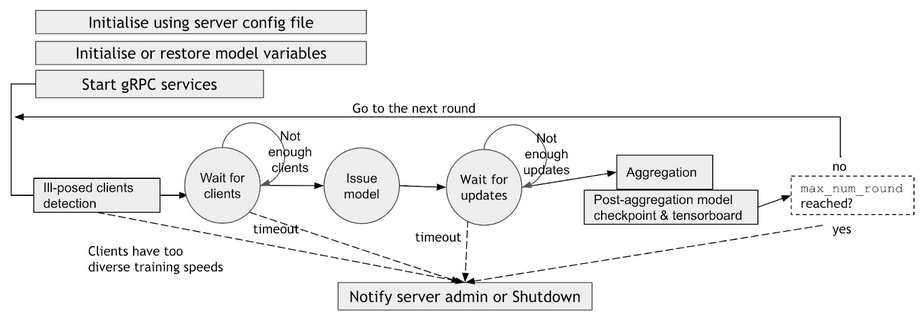
When starting a Federated Learning server-side service, the server side config files, including Federated Learning service name, gPRC communication ports, SSL certificate keys, minimum and maximum number of clients, etc, are used to initialize and restore the initial model and start the Federated Learning service. After initialization, the server enters into a loop, waiting for clients’ joining request, then issues the model to the clients, and waits for the clients to send back the updated models. Once the server receives all the updated models from the clients, it performs the aggregation based on the weighted aggregation algorithm, and updates the current overall model. Then, this updated overall model is used for the next round of model training, a process that’s repeated until the server reaches the maximum rounds of the Federated Learning training.
CLIENT-SIDE WORKFLOW
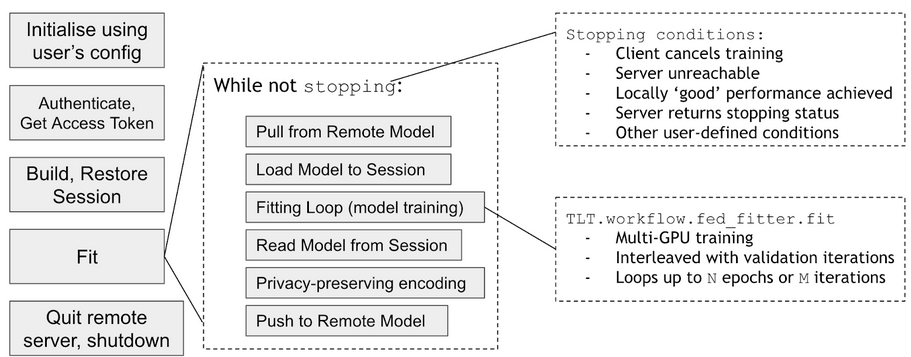
On the client side of Federated Learning training, the client first uses the client configuration to initialize the model. Next, the client uses the client credential to make a login request to the server to get a Federated Learning training token. Once the token is obtained, the client requests the current model from the server. It uses the current global model to build and restore the TensorFlow session to start the local training using the local data to fit the current model. During local training, the client has control over the number of epochs to run for each round of Federated Learning training. They also have control over whether the local training is run on a single GPU or multiple GPUs.
Once the client finishes the current round of the local model training, they can send the updated local model to the server. The client can configure their own privacy preserving policies on how much of the weights to send back to the server for aggregation. Next, the client can request the server for a new global model to start a new round of Federated Learning training.
MODEL QUALITY WITH Federated Learning
When training the multi-modal multi-clas brain tumour segmentation task from our Medical Modal ARchive (MMAR) using the BRATS2018 dataset, Federated Learning achieves a comparable segmentation performance compared to the data centralised training. The following figure shows the segmentation model quality measured by Dice scores on a held-out validation dataset, plotted against the number of training epochs.
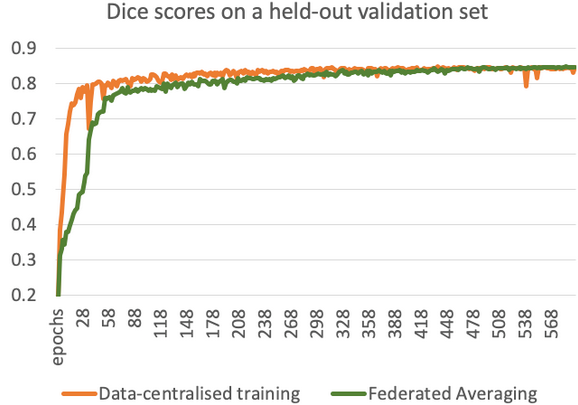
Both of the data-centralized and federated averaging methods adopt the same network architecture and preprocessing steps following our MMAR setup. The key difference between the methods is that, in Federated Averaging, the dataset was split into thirteen clients according to sources where the data were originally acquired, and the clients do not share their training data during the process. From the figure we can conclude that both training process converged to a similar level of performance in terms of Dice score (0.82). This also suggests that the Federated Learning system can effectively extract knowledge from multiple local training sets and aggregate the knowledge via a federated server.
You can find more detailed results in our paper.
Federated Learning MMAR (Medica Model ARchive) INTEGRATION
Federated Learning functions are packaged with the same MMAR (Medical Model ARchive) structure as in Clara Train SDK v1.0 & v1.1. In terms of the model training configurations, Federated Learning model training uses the same transform pipeline solution.
Additionally, there are two server-client configurations to describe Federated Learning behaviors. The server trainer controls the number of Federated Learning training rounds required to conduct for the whole model training process, aggregates the overall models from the participating clients, and coordinates the global model training progress. The client trainer controls how many epochs the model training needs to run for each Federated Learning round, and the privacy protection policy to use when publishing the locally trained model back to the Federated Learning server for aggregation.
When starting a Federated Learning model training, we first start the Federated Learning training service from the server with the server_train.sh command. This service manages the training task identity and gPRC communication service location URLs. During the Federated Learning life cycle, the service listens for the clients to join, broadcasts the global model, and aggregates the updated models from the client.
From the client side, the client uses the client_train.sh command to start a Federated Learning client training task. It gets the token through a login request, gets the global model from the server, trains and updates the local model using protected data locally, and submits the model to the server for aggregation after each round of Federated Learning training.
Federated Learning DATA PRIVACY AND SECURITY
Safeguarding data privacy is a key motivation for Federated Learning. The Federated Learning model training typically involves multiple different organizations. Clara Train’s Federated Learning implementation enables each organization to train the model locally, sharing only the partial model weights, not the private data. However, the client-server communication is also critical to keep the data and model communication secure without being compromised.
In order to achieve Federated Learning security, we use a Federated Learning token to establish trust between the client and server. The Federated Learning token is used throughout the federated training session life cycle. Clients need to verify the server identity and the server needs to verify and authenticate the clients. The client-server data exchanges are based on the HTTPS protocol for secure communication. The self-signed SSL certificates are used to build the client-server trust.
Instructions on how to create the self-signed SSL Certificate Authority and server-clients certificates are included in the documentation.
Federated Learning SERVER AND CLIENT CONFIGURATION
The Federated Learning server configuration file: config_fed_server.json.
Example:
{
"servers": [
{
"name": "prostate_segmentation",
"service": {
"target": "localhost:8002",
"options": [
["grpc.max_send_message_length", 1000000000],
["grpc.max_receive_message_length", 1000000000]
]
},
"ssl_private_key": "resources/certs/server.key",
"ssl_cert": "resources/certs/server.crt",
"ssl_root_cert": "resources/certs/rootCA.pem",
"min_num_clients": 2,
"max_num_clients": 100,
"start_round": 0,
"num_rounds": 300,
"exclude_vars": "dummy",
"num_server_workers": 100
}
]
}
| Variable | Description |
| servers | The list of servers runs the Federated Learning service. |
| name | The Federated Learning model training task name |
| target | FL gRPC service location URL |
| grpc.max_send_message_length | Maximum length of gRPC message send |
| grpc.max_receive_message_length | Maximum length of gRPC message receive |
| ssl_private_key | gRPC secure communication private key |
| ssl_cert | gRPC secure communication SSL certificate |
| ssl_root_cert | gRPC secure communication trusted root certificate |
| min_num_clients | Minimum number of clients required for Federated Learning model training |
| max_num_clients | Maximum number of clients required for Federated Learning model training |
| start_round | FL training starting round number |
| num_rounds | Total number of Federated Learning model training |
| exclude_vars | Excluded variables from the privacy preserving |
| num_server_workers | Maximum number of workers to support the Federated Learning model training |
Federated Learning Client Configuration
The Federated Learning server configuration file: config_fed_client.json.
Example:
{
"servers": [
{
"name": "prostate_segmentation",
"service": {
"target": "localhost:8002",
"options": [
["grpc.max_send_message_length", 1000000000],
["grpc.max_receive_message_length", 1000000000]
]
}
}
],
"client": {
"local_epochs": 20,
"exclude_vars": "dummy",
"privacy": {
"dp_type": "none",
"percentile": 75,
"gamma": 1
},
"ssl_private_key": "resources/certs/client1.key",
"ssl_cert": "resources/certs/client1.crt",
"ssl_root_cert": "resources/certs/rootCA.pem"
}
}
| Variable | Description |
| servers | Same as the server configuration for the Federated Learning training task identification and service location URLs |
| client | The section to describe the Federated Learning client |
| local_epochs | How many epochs to run for each Federated Learning training round |
| exclude_vars | Excluded variables from the privacy preserving |
| privacy | Privacy preserving algorithm |
| ssl_private_key | gRPC secure communication private key |
| ssl_cert | gRPC secure communication SSL certificate |
| ssl_root_cert | gRPC secure communication trusted root certificate |
DOWNLOAD CLARA TRAIN SDK AND GET STARTED
You can download the SDK here. Federated Learning is an open research area and NVIDIA Clara team is committed to exploring and developing new collaborative learning techniques. Contact us at ClaraImaging@nvidia.com to learn more.