Accelerated systems have become the new standard for high performance computing (HPC) as GPUs continue to raise the bar for both performance and energy efficiency. In 2012, Oak Ridge National Laboratory announced what was to become the world’s fastest supercomputer, Titan, equipped with one NVIDIA® GPU per CPU – over 18 thousand GPU accelerators. Titan established records not only in absolute system performance but also in energy efficiency, with 90% of its peak performance being delivered by the GPU accelerators. This week, the U.S. Department of Energy (DoE) announced the award to IBM and NVIDIA to build two new flagship supercomputers, the Summit system at Oak Ridge National Laboratory and the Sierra system at Lawrence Livermore National Laboratory.

A new NVIDIA white paper explores key features of these new supercomputers and the technologies enabled by the Tesla® accelerated computing platform that will drive the U.S. DoE’s push toward exascale. Here’s a description of Summit and Sierra from the white paper.
The Oak Ridge National Laboratory (ORNL) Summit system will be a leadership computing platform for the Office of Science. Delivered in 2017, Summit is expected to reach between 150 and 300 petaFLOPS and is positioned as a precursor to the U.S. DoE’s exascale system.
As the lead federal agency supporting fundamental scientific research across numerous domains, the Office of Science is chartered to meet the insatiable need for computing resources by researchers and scientists. Summit will carry on the tradition set by Titan, ORNL’s current GPU-accelerated supercomputer, which is among the world’s fastest supercomputers today.
The Lawrence Livermore National Laboratory (LLNL) Sierra supercomputer will be the NNSA’s primary system for the management and security of the nation’s nuclear weapons, nuclear nonproliferation, and counterterrorism programs. In support of the complex mission of its Advanced Simulation and Computing program, LLNL has had numerous top-5 supercomputers, including most recently Sequoia, an IBM Blue Gene/Q system. Sierra will replace Sequoia and is expected to deliver more than 100 petaFLOPS, over 5x higher compute performance than its predecessor.
The Importance of Heterogeneous Nodes
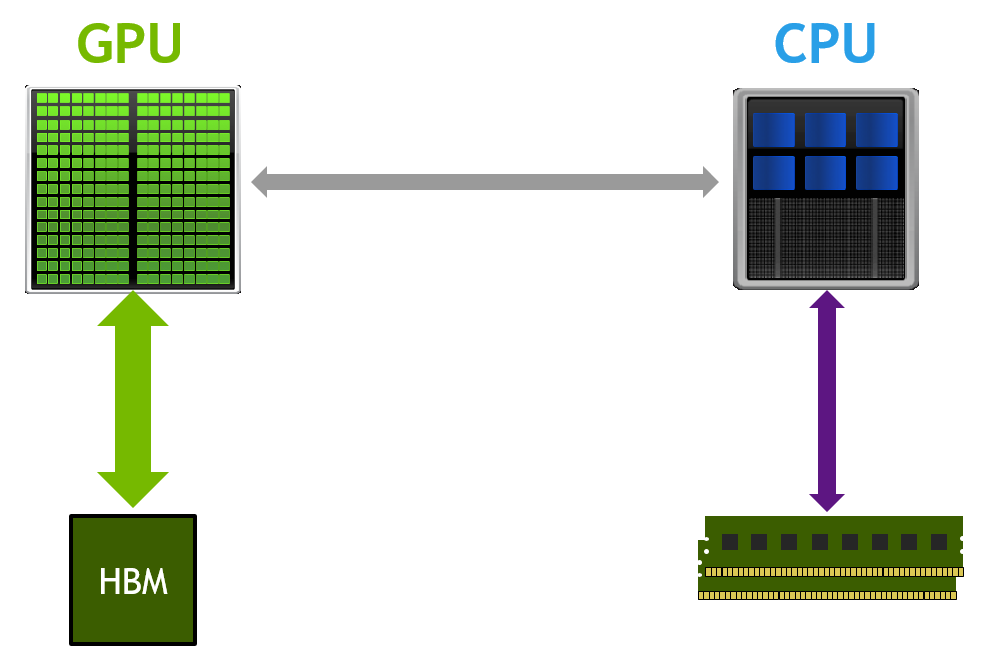
The architectural emphasis on parallelism in GPUs leads to optimization for throughput, hiding rather than minimizing latency. Support for thousands of threads ensures a ready pool of work in the face of data dependencies in order to sustain performance at a high percent of peak. The memory hierarchy design and technology thoroughly reflect optimization for throughput performance at minimal energy per bit.
By contrast, latency-optimized CPU architecture drives completely different design decisions. Techniques designed to compress the execution of a single instruction thread into the smallest possible time demand a host of architectural features (like branch prediction, speculative execution, register renaming) that would cost far too much energy to be replicated for thousands of parallel GPU threads but that are entirely appropriate for CPUs.
The essence of the heterogeneous computing model is that one size does not fit all. Parallel and serial segments of the workload execute on the best-suited processor—latency-optimized CPU or throughput-optimized GPU—delivering faster overall performance, greater efficiency, and lower energy and cost per unit of computation.
ORNL and LLNL chose to build the Summit and Sierra pre-exascale systems around this powerful heterogeneous compute model using technologies from IBM and NVIDIA. IBM’s POWER CPUs are among the world’s fastest serial processors. NVIDIA GPU accelerators are the most efficient general purpose throughput-oriented processors on the planet. Coupling them together produces a highly efficient and optimized heterogeneous node capable of minimizing both serial and parallel sections of HPC codes.
The Growing Multi-GPU Trend
Since Titan, a trend has emerged toward heterogeneous node configurations with larger ratios of GPU accelerators per CPU socket, with two or more GPUs per CPU becoming common as developers increasingly expose and leverage the available parallelism in their applications. Although each of the new DoE systems is unique, they share the same fundamental multi-GPU node architecture.
While multi-GPU applications provide a vehicle for scaling single node performance, they can be constrained by interconnect performance between the GPUs. Developers must overlap data transfers with computation or carefully orchestrate GPU accesses over PCIe interconnect to maximize performance. However, as GPUs get faster and GPU-to-CPU ratios climb, a higher performance node integration interconnect is warranted. Enter NVLink.
NVLink: High-Speed GPU Interconnect
NVLink is an energy-efficient, high-bandwidth path between the GPU and the CPU at data rates of at least 80 gigabytes per second, or at least 5 times that of the current PCIe Gen3 x16, delivering faster application performance. NVLink is the node integration interconnect for both the Summit and Sierra pre-exascale supercomputers commissioned by the U.S. Department of Energy, enabling NVIDIA GPUs and CPUs such as IBM POWER to access each other’s memory quickly and seamlessly. NVLink will first be available with the next-generation NVIDIA Pascal™ GPU in 2016.
In addition to speeding CPU-to-GPU communications for systems with an NVLink CPU connection, NVLink can have significant performance benefit for GPU-to-GPU (peer-to-peer) communications as well. A second new NVIDIA white paper focuses on these peer-to-peer benefits from NVLink, showing how systems with next-generation NVLink-interconnected GPUs are projected to deliver considerable application speedup compared to systems with GPUs interconnected via PCIe.
The white paper analyzes the performance benefit of NVLink for several algorithms and applications by comparing model systems based on PCIe-interconnected next-gen GPUs to otherwise-identical systems with NVLink-interconnected GPUs. GPUs are connected to the CPU using existing PCIe connections, but the NVLink configurations augment this with interconnections among the GPUs for peer-to-peer communication.
The paper examines five multi-GPU algorithms and applications important to HPC: exchange and sort, FFT, AMBER Molecular Dynamics (PMEMD), ANSYS Fluent Computational Fluid Dynamics (CFD), and QUDA Lattice Quantum Chromodynamics (LQCD). Projected results for exchange, sort, and 3D FFT are shown in Figures 1, 2, and 3, respectively.
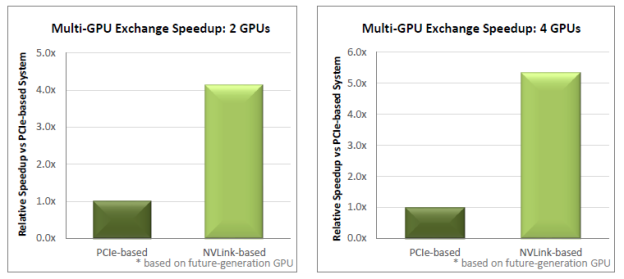
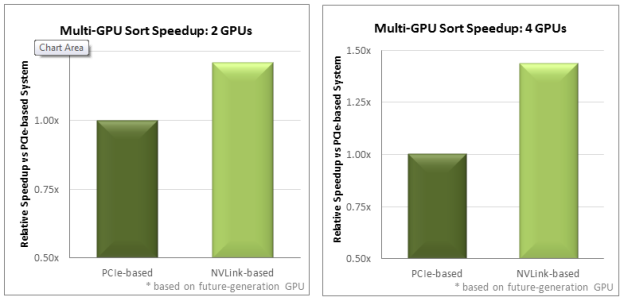
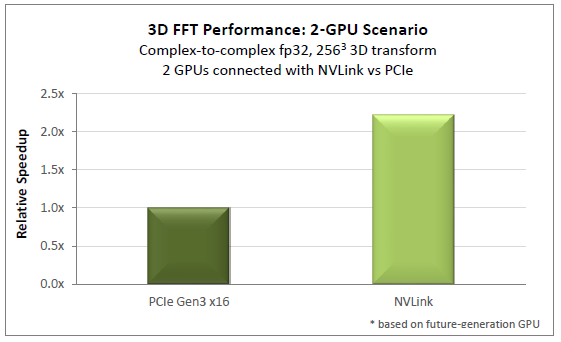
The whitepaper presents the analysis of performance considerations for each application, with the result that NVLink is projected to deliver significant performance boost – up to 2x in many applications – simply by replacing the PCIe interconnect for communication among peer GPUs. This clearly illustrates the growing challenge NVLink addresses: as the GPU computation rate grows, GPU interconnect speeds must scale up accordingly in order to see the full benefit of the faster GPU.
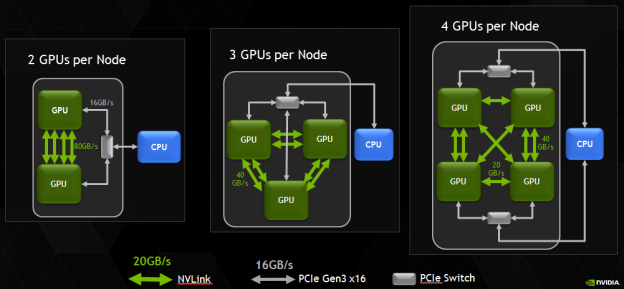
NVLink is a flexible and scalable interconnect technology, enabling a rich set of design options for next-generation servers to include multiple GPUs with a variety of interconnect topologies and bandwidths, as Figure 4 shows.
Faster, Easier Programming
One important result of the higher bandwidth between GPUs provided by NVLink will be that libraries such as cuFFT and cuBLAS can offer much better multi-GPU scalability, scaling onto a greater number of GPUs as well as strong scaling smaller problems where communication is a significant bottleneck today.
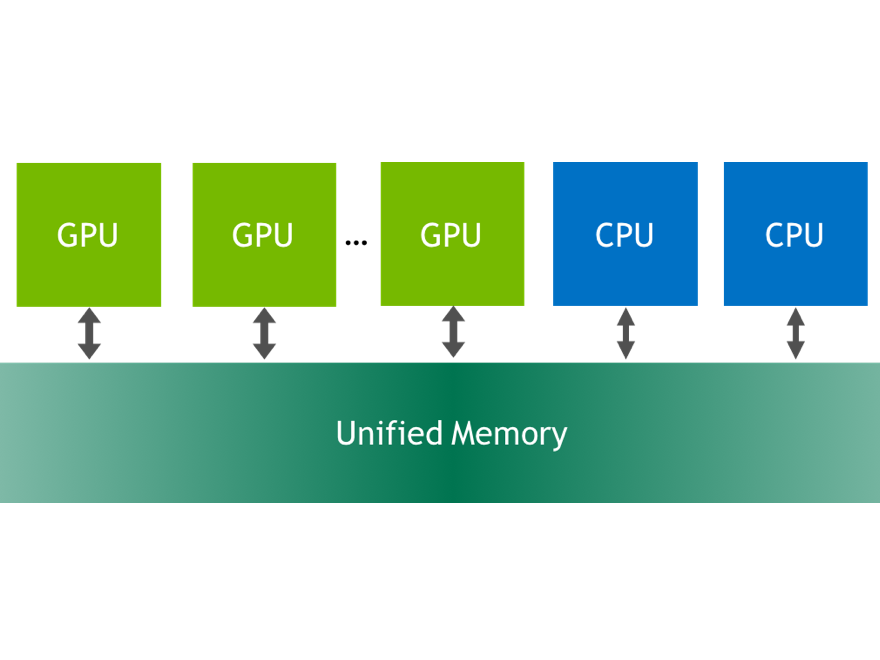
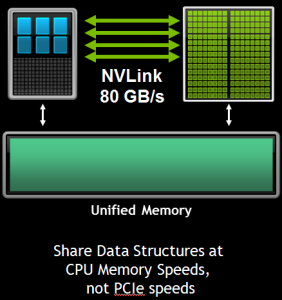
Unified Memory and NVLink represent a powerful combination for CUDA® programmers. Unified Memory provides you with a single pointer to data and automatic migration of that data between the CPU and GPU. With 80 GB/s or higher bandwidth on machines with NVLink-connected CPUs and GPUs, that means GPU kernels will be able to access data in host system memory at the same bandwidth the CPU has to that memory—much faster than PCIe. Host and device portions of applications will be able to share data much more efficiently and cooperatively operate on shared data structure, and supporting larger problem sizes will be easier than ever.
While Summit and Sierra are based on POWER CPUs, CUDA enables common programming approaches across a variety of heterogeneous systems, with support for x86, ARM, and POWER. You can program all of these systems with GPU-accelerated libraries, OpenACC compiler directives, or CUDA-accelerated programming languages. So get started now to get your applications GPU-accelerated and ready to take advantage of NVLink.
For more details on the Summit and Sierra supercomputers and their projected performance, visit www.nvidia.com/object/exascale-supercomputing.html. For more details on NVLink and projected application speedups, visit www.nvidia.com/object/nvlink.html.