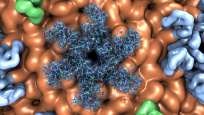
HPC looks very different today than it did when I was a graduate student in the mid-90s. Today’s supercomputers are many orders of magnitude faster than the machines of the 90s, and GPUs have helped push arithmetic performance on several leading systems to stratospheric levels. Unfortunately, the arithmetic performance wrought by two decades of supercomputer design has created tremendous I/O and visualization challenges that must be overcome, reflected by the famous statement:
“A supercomputer is a device for turning compute-bound problems into
I/O-bound problems.” — Ken Batcher
Molecular visualization with VMD
Since 1998, I’ve been leading the development of VMD, a popular molecular visualization and analysis application that is used by scientists all over the world. Among similar programs, VMD is particularly focused on capabilities that support large-scale molecular dynamics simulations and cellular modeling.
The movies in this article are examples of the kind of visualizations we regularly produce with parallel VMD visualization runs that use OptiX and/or OpenGL running on the Tesla GPUs in the Blue Waters and Titan supercomputers. These example movies highlight the science done by my colleagues in the Theoretical and Computational Biophysics Group, led by Prof. Klaus Schulten at U. Illinois.
Some key areas of our ongoing VMD development involve the continued adaptation of the program for petascale and exascale supercomputers, advancing the molecular visualization state-of-the-art with parallel and interactive ray tracing techniques, exploiting massively parallel GPU accelerators for both visualization and analysis tasks, and supporting remote visualization and collaboration on HPC platforms. The combination of these VMD development tracks and current technological progress in HPC, GPUs, and visualization algorithms is leading in a very exciting direction.
Petascale Computing, Big Datasets, and Visualization without Data Transfers
Visualization is a crucial component in many HPC simulation campaigns, and it is often involved in all phases of a project starting with model building, simulation preparation, and testing, and continuing through production simulation, final analysis, and dissemination of results. In the past, researchers often performed these tasks on high-end workstations, requiring key data to be transferred to and from off-site supercomputers throughout the various stages of a project. Large-scale visualization and analysis jobs were often run on institutional or departmental clusters, and file transfer and disk I/O were both a nuisance, but manageable.
Fast forward to the petascale supercomputers and simulation sizes of today, and off-site transfers that were formerly manageable with previous generation science workloads now take days, or weeks to complete for state-of-the-art problem sizes and simulation time scales, making these approaches increasingly untenable.
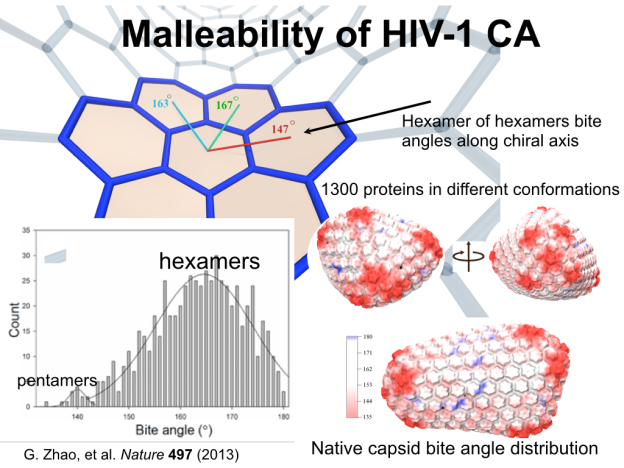
The recent incorporation of Tesla GPUs in several of the world’s most powerful supercomputers has created an exciting opportunity to use them for large scale parallel visualization tasks, bringing full compatibility with a variety of high-performance graphics and visualization APIs typically available only on desktop workstations. The chief benefit of downloading data to off-site workstations was that a panoply of visualization and analysis tools could be used, and interactive visualizations could be performed, rather than much more limiting batch-mode workflows. By using the Tesla GPUs already present in leading HPC systems for visualization as well as simulation and analysis, HPC applications can exploit the same state-of-the-art OpenGL graphics APIs available on workstations, without unimplemented functionality or performance shortfalls that can be associated with Mesa software rasterization.
The high performance of GPU-accelerated rasterization and ray tracing reduces the run-time cost of in-situ visualization techniques that directly couple visualization to running simulations, visualizations coupled to large scale parallel analysis, and for high-fidelity image and movie renderings for publication and dissemination. GPU-accelerated OpenGL rasterization performance is often high enough that visualization tasks can be run “piggyback” on data analysis jobs, overlapping rendering with I/O and other computations, to provide additional visualization almost “for free”.
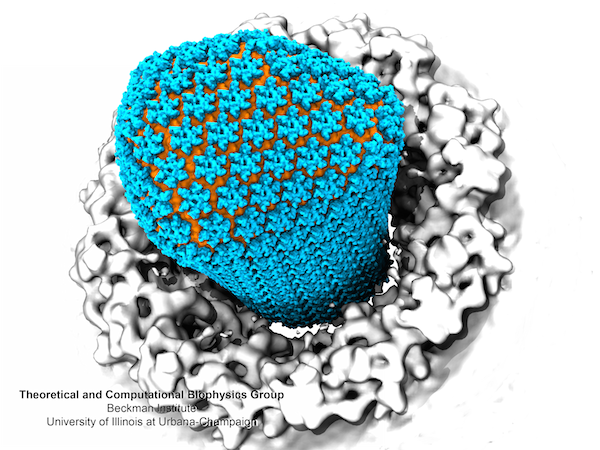
Another important benefit associated with visualization performance gains is that fewer compute nodes are required, which typically reduces job start wait times that are of particular concern for many conceptual, exploratory, and interactive visualization tasks. The two HIV capsid figures exemplify the kinds of visualizations of large simulations that scientists need to make every day.
Remote visualization
Thanks to the widespread popularity of network video streaming for home entertainment, modern GPUs contain dedicated hardware acceleration for graphics capture, and video encoding and decoding. Libraries such as the GRID SDK and the NVENC SDK make video encoding hardware available to application software, enabling fast movie encoders and making a variety of interactive remote visualization capabilities possible.
The availability of remote visualization, either implemented within visualization applications themselves, or through server software such as NICE DCV, eliminates the need for off-site file transfers and allows HPC users to run a broad range of visualization tools in-place on the supercomputer where the data resides.
Looking ahead towards systems such as the DOE’s upcoming Summit and Sierra systems at Oak Ridge National Laboratory and Lawrence Livermore National Laboratory, there appear to be many exciting new visualization opportunities arising from much larger compute node host memory, multiple GPUs per compute node, direct host memory access by GPUs, and high-bandwidth peer-to-peer GPU memory transfers via NVLink.
Configuring Tesla GPUs for Visualization
Although they lack video outputs, when properly configured, Tesla GPUs are fully capable of supporting the same graphics APIs and visualization capabilities as their GeForce and Quadro siblings. Below I list some of the basic requirements to enable graphics on Tesla GPUs, and steps for accomplishing this in the most common cases. My examples below assume a conventional Linux-based x86 compute node, but they would likely be applicable to other node architectures as well.
Set the GPU operation mode to ALL_ON
One of the first requirements for enabling graphics on Tesla hardware is to ensure that the GPU operation mode is set to ALL_ON, which enables both graphics and compute operation. The GPU operation mode is set to ALL_ON by default on the latest NVIDIA Tesla GPUs, but on earlier Tesla K20 and K20X GPUs, the GPU is set to COMPUTE mode and must be switched to ALL_ON.
The ALL_ON operation mode is set using the nvidia-smi utility with the --gom=0 flag, and typically requires a subsequent system reboot in order to take full effect. We describe the issue in more detail as it pertains to Cray systems in a short paper here.
Enable the windowing system for full use of graphics APIs
Once the GPU operation mode is properly set, the next requirement for full graphics operation is a running a windowing system. At present, the graphics software stack supporting OpenGL and related APIs depends on initialization and context creation facilities provided in cooperation with a running windowing system. A full windowing system is needed when supporting remote visualization software such as NICE DCV, VNC, or Virtual GL.
Currently, a windowing system is also required for large scale parallel HPC visualization workloads, even though off-screen rendering (e.g. OpenGL FBOs or GLX Pbuffer rendering) is typically used exclusively.
It is desirable to prevent the X Window System X11 server and related utilities from looking for attached displays when using Tesla GPUs. The UseDisplayDevice configuration option in xorg.conf can be set to none, thereby preventing any attempts to detect display, validate display modes, etc. The nvidia-xconfig utility can be told to set the display device to none by passing it the command line flag --use-display-device=none when you run it to update or generate an xorg.conf file.
One of the side effects of enabling a windowing system to support full use of OpenGL and other graphics APIs is that it generally also enables a watchdog timer that will terminate CUDA kernels that run for more than a few seconds. This behavior differs from the compute-only scenario where a Tesla GPU is not graphics-enabled, and will allow arbitrarily long-running CUDA kernels. For HPC workloads, it is usually desirable to eliminate such kernel timeouts when the windowing system is running, and this is easily done by setting a special "Interactive" configuration flag to "false", in xorg.conf in the "Device" block for each GPU. The following is an example "Device" section from an HPC-oriented xorg.conf file (see NVIDIA README X Config Options section for details).
Section "Device"
Identifier "Device0"
Driver "nvidia"
VendorName "NVIDIA Corporation"
BusID "PCI:132:0:0"
##
## disable display probing, display mode validation, etc.
##
Option "UseDisplayDevice" "none"
##
## disable watchdog timeouts for long-running CUDA kernels
##
Option "Interactive" "false"
EndSection
The xorg.conf configuration example snippet shown above is what I use for the NVIDIA Tesla K80 cards on a headless remote visualization server running the NICE DCV software, but is also very similar to what is used on the Blue Waters XK7 nodes.
Running X11 on systems without consoles or virtual terminal kernel support
One complication with the requirement for a running windowing system is that HPC clusters and supercomputers may lack console devices required by standard X11 server compilations, which interferes with normal startup of the X11 server. One sure way of solving this problem, if it arises, is to modify and recompile the X11 server from source code, and thereby disable console management logic in question.
The X11 console management code is part of the OS-dependent initialization source file for each target platform, e.g. for Linux, in hw/xfree86/os-support/linux/lnx_init.c. The console management functions of interest are xf86OpenConsole(), xf86CloseConsole(), xf86ProcessArgument(), and xf86UseMsg(). The console routines can either be modified to immediately return, or the entire OS-dependent initialization source file can be replaced by the stub implementation provided in hw/xfree86/os-support/stub/stub_init.c.
This approach eliminates X11 server startup dependencies on console devices and eliminates the need for kernel support for console virtual terminals and other features that may not be available in the system images used on clusters and supercomputers. This is the approach we took to enable the X11 server to run on the NCSA Blue Waters Cray XK7 compute nodes, which lack console hardware and console virtual terminal support in the compute node kernel.
Graphics without a windowing system
While it is relatively straightforward to get an X11 server running to provide complete support for existing graphics APIs, it is best to eliminate the use of a windowing system except when needed to provide a conventional desktop user interface for interactive remote visualization sessions. Eliminating the use of separate windowing system processes simplifies parallel rendering for both HPC end users and system administrators alike, eliminates consumption of limited compute node RAM associated with the windowing system process, and reduces the likelihood of OS jitter affecting message passing performance.
Using OptiX without a windowing system (or OpenGL)
It is possible to use the NVIDIA OptiX ray tracing framework without the need for a running windowing system by providing a handful of empty stub functions that replace X11 functions. I have been using this technique extensively when compiling VMD on the Cray supercomputers that have not yet been modified to allow the use of a full windowing system. The stub functions below provide a workaround for this scenario on such systems, with past versions of OptiX. New versions of OptiX for Linux, beginning with version 3.7, have reduced or eliminated many OpenGL dependencies. The stub workaround may no longer be necessary once affected clusters and supercomputers have been upgraded to the latest NVIDIA system software, thereby enabling use of the latest versions of OptiX.
// John's stub function hack to eliminate several X11
// dependencies for OptiX 2.x and 3.[0-6].x
extern "C" {
typedef struct {
unsigned int sequence;
} xcb_void_cookie_t;
static xcb_void_cookie_t fake_cookie = { 0 };
xcb_void_cookie_t xcb_glx_set_client_info_arb(void) {
return fake_cookie;
}
xcb_void_cookie_t xcb_glx_create_context_attribs_arb_checked(void) {
return fake_cookie;
}
xcb_void_cookie_t xcb_glx_set_client_info_2arb(void) {
return fake_cookie;
}
}
Related GTC’15 Talks and Future Work
There are many interesting sessions scheduled at GTC’15. I will be speaking about VMD in two of my own sessions, S5371 (VMD) and S5386 (VMD+OptiX), and as a guest speaker during David McAllister’s OptiX ray tracing innovations presentation, S5246.
I am currently working with the teams of system engineers that develop and manage Blue Waters at NCSA and Titan at ORNL, and over the coming year I’m hoping to continue to significantly advance the in-situ and remote visualization capabilities of VMD running on these systems and their siblings Piz Daint at CSCS, Big Red II at Indiana U., and architecturally similar GPU-accelerated HPC visualization facilities such as those at TACC, U. Texas Austin.
Links to resources with further information
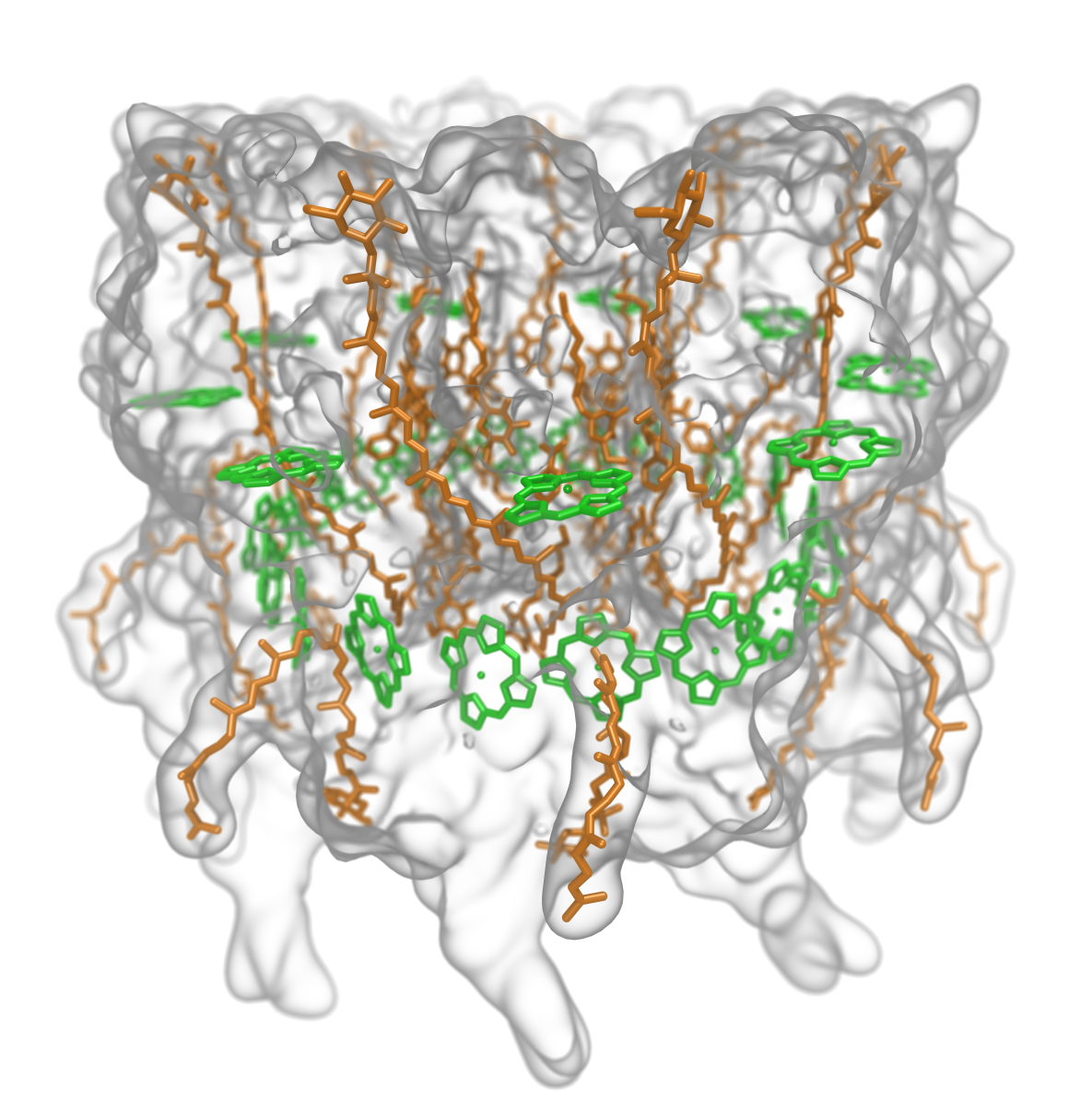
- Visualization of Energy Conversion Processes in a Light Harvesting Organelle at Atomic Detail. Sener et al. SC’14 Visualization and Data Analytics Showcase, 2014.
- GPU-Accelerated Molecular Visualization on Petascale Supercomputing Platforms. John E. Stone, Kirby L. Vandivort, and Klaus Schulten. UltraVis’13: Proceedings of the 8th International Workshop on Ultrascale Visualization, pp. 6:1-6:8, 2013.
- NICE DCV remote visualization software
- Unlocking the Full Potential of the Cray XK7 Accelerator. Mark D. Klein and John E. Stone. Cray Users Group, Lugano Switzerland, May 2014.
- Interactive Supercomputing with In-Situ Visualization on Tesla GPUs
- HPC’s Future Lies in Remote Visualization
- Remote Visualization on Server-Class Tesla GPUs
- NVIDIA Linux driver README 346.35
- Cray XK7-specific patches from the X11 and OpenGL implementation on Blue Waters
- Xorg X11 server source tree browser