What is dark matter? We can neither see it nor detect it with any instrument. CERN is upgrading the LHC (Large Hadron Collider), which is the world’s largest and most powerful particle accelerator ever built, to explore the new high-energy frontier.
What is dark matter? We can neither see it nor detect it with any instrument. CERN is upgrading the LHC (Large Hadron Collider), which is the world’s largest and most powerful particle accelerator ever built, to explore the new high-energy frontier.
The most technically challenging aspects of the upgrade cannot be done by CERN alone and requires collaboration and external expertise. There are 7,000 scientists from over 60 countries working to extend the LHC discovery potential; the accelerator will need a major upgrade around 2020 to increase its luminosity by a factor of 10 beyond the original design value.
Ph.D. student Adrian Oeftiger attends EPFL (École Polytechnique Fédérale de Lausanne) in Switzerland which is one of the High Luminosity LHC beneficiaries. His research group is working to parallelize their algorithms to create software that will offer the possibility of new kinds of beam dynamics studies that have not been possible with the current technology.
Brad: How is your research related to the upgrade of the LHC?
Adrian: My world is all about luminosity; increasing the luminosity of particle beams. It is all about making ultra-high-energy collisions of protons possible, and at the same time providing enough collisions to enable fundamental particle physics research. That means increasing the luminosity. I’m doing my Ph.D. in beam dynamics in the field of accelerator physics.
 These days, high-energy particle accelerators are the tools of choice to analyze and understand the fundamental building blocks of our universe. The huge detectors at the Large Hadron Collider (LHC) at CERN, buried about a hundred meters underground in the countryside near Geneva, need ever-increasing collision rates (hence luminosity!): they gather statistics of collision events to explore new realms of physics, to detect extremely rare interaction combinations and the tiniest quantities of new particles, and to find explanations for some of the numerous wonders of the universe we live in. What is the dark matter which makes up 27% of our universe made of? Why is the symmetry between anti-matter and ordinary matter broken, and why do we find only the latter in the universe?
These days, high-energy particle accelerators are the tools of choice to analyze and understand the fundamental building blocks of our universe. The huge detectors at the Large Hadron Collider (LHC) at CERN, buried about a hundred meters underground in the countryside near Geneva, need ever-increasing collision rates (hence luminosity!): they gather statistics of collision events to explore new realms of physics, to detect extremely rare interaction combinations and the tiniest quantities of new particles, and to find explanations for some of the numerous wonders of the universe we live in. What is the dark matter which makes up 27% of our universe made of? Why is the symmetry between anti-matter and ordinary matter broken, and why do we find only the latter in the universe?
CERN is preparing for the High Luminosity LHC, a powerful upgrade of the present accelerator to increase the chances to answer some of these fundamental questions. Increasing the chances translates to: we need more collisions, so we need higher luminosity.
In order to further increase the collision rate, the whole chain of accelerators that provides particle beams to the LHC needs to be upgraded. One way to increase the luminosity is to boost the beam intensity (the number of particles in the beam). I am involved in pushing the limit of acceptable beam intensities in the LHC injector rings. My research focuses on modeling space charge effects of particle beams, so I design and tweak the sort of N-body simulations you also find a lot in celestial mechanics. The tracking software we develop in our section at CERN is called PyHEADTAIL, to which I devoted a good part of my Ph.D.
B: What are some of the biggest challenges with computing beam dynamics?
A: Particles within a beam oscillate in all three dimensions, but with different time scales. Since they interact with the electromagnetic fields of the beam itself, their motion can be strongly influenced depending on the distribution and intensity of the beam. Some particles may undergo resonant motion. Therefore, collective effects of the particles can lead to potential beam blow-up. We need self-consistent space charge models that are sensitive enough to changes within the beam distribution to resolve these nonlinear beam dynamics. On the other hand, we need to run simulations for thousands of turns around the circular accelerators to make solid statements on beam stability. A turn takes somewhere between 0.5 to 100 microseconds while the cycles in the injector machines to the LHC are of the order of up to tens of seconds.
So, capturing enough detail of the physics in the model and performing parameter scans while running each simulation for a hundred thousand turns requires careful design strategies for our code. The biggest challenge is to simultaneously keep the efforts to include additional physics as simple as possible. In essence, we need to facilitate extending the PyHEADTAIL modules for us physicists while using the hardware effectively. We tackle this by designing the algorithms in Python, transparently interfacing the data handling to CUDA and processing it (behind the scenes) on the GPU.
B: What made you start using GPUs?
A: I started to dig into GPU computing last year. During a project at my university, I achieved huge speed-ups for a simple tracking code. When I heard about Andreas Klöckner, who designed PyCUDA as an interface from Python to CUDA, I got really excited. Being able to unite the development effectiveness of Python with the raw computational power of NVIDIA GPUs proved to be a huge increase in my personal productivity.
I have dived into my Ph.D. with a pure longitudinal scenario to create exotic beam distributions. My simulations would take somewhere around half a day until I recently transferred the data back-end to the GPU with PyCUDA. Now it runs somewhere between ten minutes to half an hour (speed-up of 14): I can now explore parameter spaces much more effectively!

GPU computing also proves to be a huge support during measurements in the CCC (CERN Control Centre) to be able to just run a quick simulation in order to see where we are makes life so much easier. On-the-fly predictions from the immensely sped-up simulations can guide the measurement strategies in the right direction without much trial and error, thus avoiding high beam losses in the real machines.
B: What NVIDIA technologies are you using?
A: In our group at CERN, we have a server station with four NVIDIA Tesla C2075 cards which we use for development, single simulations, and low-scale parameter scans. Currently, I am testing the HPC cluster from CNAF in Bologna – their equipment includes seven Tesla K20 GPUs and eight Tesla K40 GPUs which would facilitate some large-scale parameter scans that are coming up soon for us.
B: Which CUDA features and GPU-accelerated libraries are you taking advantage of?
A: Our library PyHEADTAIL per se is entirely designed in Python. There are two layers which we need to adapt for GPU use: (1) the NumPy arrays with all elementary operations need to be transferred to the GPU and (2) the used libraries need to be replaced by GPU equivalents.
To solve (1), we use PyCUDA to transfer the data handling to CUDA. PyCUDA provides an interface to CUDA with an API that mimics the NumPy API, Python’s fundamental numerical computation library. This essentially translates all usage of arrays to the GPU for free – only the initialization and the data dumping need to be custom tailored. That means a major part of PyHEADTAIL can be left as is!
To address (2), we interface CUDA libraries either with scikit-cuda (by Lev Givon) or via Python’s ctypes. We are using FFTW, the SuperLU and KLU libraries and certain NumPy/SciPy functionalities for PyHEADTAIL on the CPU.
- Replacing FFTW by cuFFT gives us a factor of 35. cuFFT is interfaced by scikit-cuda and is straightforward to use.
- Our sparse discrete Poisson solver for arbitrarily shaped boundaries is based on SuperLU or KLU. For the GPU, we use cuSPARSE and cuSOLVER. The Laplace matrix is very sparse but has a quite serial pattern; we are yet to speed up the solving part. The NVIDIA-developed cuSOLVER comes with the CUDA Toolkit, which makes it more attractive to us than alternatives like CULA Sparse since there are no additional libraries to be installed on the GPU cluster.
- We have written our own custom CUDA kernels for gradients, smoothing, and particle-to-mesh deposition and mesh-to-particle interpolation.
For our particle-in-cell algorithm, we use the Thrust library to sort the particles according to their cell IDs and determine the cell boundaries with thrust::lower_bound. This deposition algorithm is more than a factor 3 faster than the alternative approach with a global atomicAdd. For more than 500,000 macro-particles, we achieve better results on the GPU versus CPU for the particle-mesh part of the code.
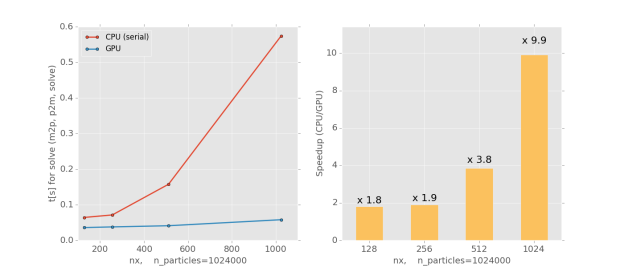
B: What types of parallel algorithms are you implementing?
A: We model the proton beams with macro-particle distributions. PyHEADTAIL pushes the beam through the accelerator elements. Each turn, collective effects are modeled at many interaction points (IP). The drift-kick mechanism advances the particles between them while the integrated interaction between the macro-particles (and of macro-particles with the walls and impedances) is applied in the form of kicks at each IP.
Self-consistent space charge effects are modeled with particle-in-cell algorithms. The charge distribution of the particles is lumped on a regular mesh in the beam Lorentz frame. Then we solve the discretized Poisson equation on the mesh for the electrostatic potential with Finite Difference (FD) methods or Fast Fourier Transform (FFT) methods via integrated Green functions. The gradient of the potential gives the electric field in the beam frame which is interpolated back to the particles. Lorentz-transforming back to the laboratory frame finally yields the kicks to be applied to the particles.
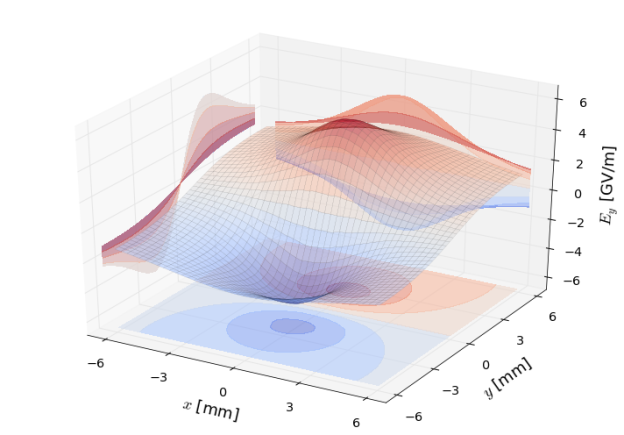
For the more energetic accelerator stages, so-called 2.5D space charge models are sufficient. Imagine slicing the beam into many disks along the direction of motion. At high energies, the electromagnetic fields of an arbitrary beam slice extend transversely while their longitudinal influence shrinks drastically. Hence, the fields assume a disk-like shape. This fact allows slicing the beam up along the direction of motion and treating the longitudinal and transverse planes separately.
On the other hand, the low-energy rings in the upstream part of the accelerator chain may require consistent 3D space charge models to account for the wide longitudinal opening angle of the comparatively slow beams. In order to model certain interactions of the beam with lattice resonances of the accelerator to sufficient detail, the mesh requires at least 128 x 128 x 64 nodes, usually more.
B: What do you think is most interesting for developers to learn from your project?
A: The busy CERN accelerator schedules, demands on our tracking software, and continuously changing physics model entail dynamic and active development by a broad community in our section. I think our approach of using Python as the high-level implementation of the library while the data handling itself is done with CUDA to achieve high performance can be very attractive to other projects with a similar user/developer situation.
B: Any tips for beginning GPU developers?
A: At the beginning, I spent too much time working with high-level frameworks on top of CUDA (such as PyCUDA) – it was too early during my learning process. This often resulted in long detours of trial-and-error until I sat down each time, programming the algorithm in CUDA kernels by myself in the end.
It helped me tremendously to invest more into
- Understanding the GPU architecture,
- Sticking my head into CUDA’s parallel computing concepts, and
- Devoting much time to programming kernels and optimizing small code parts in CUDA itself. I found that exploiting the GPU capabilities to a satisfying extent (especially with high-level frameworks) in any case requires understanding what happens at the low level.
So make sure to read the NVIDIA documentation, program matrix multiplication and similar “simple” exercises yourself and continuously dive into low-level source code. It pays off hugely to understand what’s going on behind the scenes!
B: What are you most excited about, in terms of advancements over the next decade?
A: PyHEADTAIL targets diverse hardware set-ups ranging from personal laptops (in the CCC) and office PCs over CERN’s general-purpose cluster, “lxplus”, to GPU workstations and InfiniBand interconnected HPC cluster nodes (like at CNAF in Bologna). I’m concerned about keeping the amount of code as low as possible while decently exploiting the respective hardware – this is naturally a rocky road with many trade-offs on the way.
Most of all, I’m looking forward to seeing how CERN’s ambitious LHC injector upgrade goals for higher luminosities will be met and to what extent our GPU-accelerated PyHEADTAIL will help guide the way.