
Deep Neural Networks (DNNs) are a powerful approach to implementing robust computer vision and artificial intelligence applications. NVIDIA Jetpack 2.3, released today, increases run-time performance of DNNs in embedded applications more than two-fold using NVIDIA TensorRT (formerly called GPU Inference Engine or GIE). With up to 20x higher power efficiency than an Intel i7 CPU during inference workloads, NVIDIA’s 1 TFLOP/s embedded Jetson TX1 module can be deployed on board drones and intelligent machines. Jetson and deep learning power the latest advances in autonomy and data analytics, like the ultra high-performance Teal drone shown in Figure 1. JetPack contains comprehensive tools and SDKs that simplify the process of deploying core software components and deep learning frameworks for both the host and embedded target platform.

JetPack 2.3 features new APIs for efficient low-level camera and multimedia streaming with Jetson TX1, alongside updates to Linux For Tegra (L4T) R24.2 with Ubuntu 16.04 aarch64 and Linux kernel 3.10.96. JetPack 2.3 also includes CUDA Toolkit 8.0 and cuDNN 5.1 with GPU-accelerated support for convolutional neural networks (CNNs) and advanced networks like RNNs and LSTMs. To efficiently stream data into and out of algorithm pipelines, JetPack 2.3 adds the new Jetson Multimedia API package to support low-level hardware V4L2 codecs and a per-frame camera/ISP API based on Khronos OpenKCam.
These tools included in JetPack lay the groundwork for deploying real-time deep learning applications and beyond. See below for the full list of software included. To get you started, JetPack also includes deep learning examples and end-to-end tutorials on training and deploying DNNs.
JetPack 2.3 Components
| Linux4Tegra R24.2 | TensorRT 1.0.2 RC | VisionWorks 1.5.2.14 |
| Ubuntu 16.04 64-bit LTS | CUDA Toolkit 8.0.34 | OpenCV4Tegra 2.4.13-17 |
| Jetson Multimedia API R24.2 | cuDNN 5.1.5 | GStreamer 1.8.1 |
| Tegra System Profiler 3.1.2 | Tegra Graphics Debugger 2.3.16 | OpenGL 4.5.0 |
TensorRT
Now available for Linux and 64-bit ARM through JetPack 2.3, NVIDIA TensorRT maximizes run-time performance of neural networks for production deployment on Jetson TX1 or in the cloud. After providing a neural network prototext and trained model weights through an accessible C++ interface, TensorRT performs pipeline optimizations including kernel fusion, layer autotuning, and half-precision (FP16) tensor layout, resulting in higher performance and improved system efficiency. See this Parallel Forall post about the concepts behind TensorRT and its graph optimizations. The benchmark results in Figure 2 compare the inference performance of the GoogleNet image recognition network between GPU-accelerated Caffe and TensorRT, both with FP16 extensions enabled, across a range of batch sizes. (FP16 mode incurs no classification accuracy loss versus FP32.)
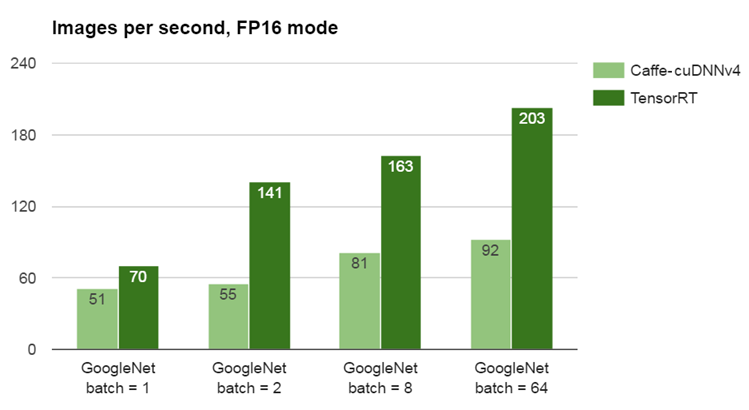
The performance is measured in images per second processed with GoogleNet using either TensorRT or the optimized nvcaffe/fp16 branch of Caffe. The tests used planar BGR 224×224 images and the GPU core clock frequency governor was at the maximum of 998MHz. The batch size indicates how many images are processed by the network at once.
The benchmark results from Figure 2 show greater than 2X improvement in inference performance between TensorRT and Caffe for a batch size of 2, and greater than 30% improvement for single images. Although using batch size 1 offers the lowest instantaneous latency on a single stream, applications that process multiple data streams or sensors simultaneously, or those that perform windowing or region-of-interest (ROI) subsampling, may achieve double the throughput gains with batch size 2. Applications that can support even higher batch sizes (e.g. 8, 64, or 128)—for example datacenter analytics—achieve greater overall throughput.
Comparing power consumption shows another advantage of GPU acceleration. As Figure 3 shows, Jetson TX1 with TensorRT is 18 times more efficient at deep learning inference with GoogleNet than Intel’s i7-6700K Skylake CPU running Caffe and MKL 2017.
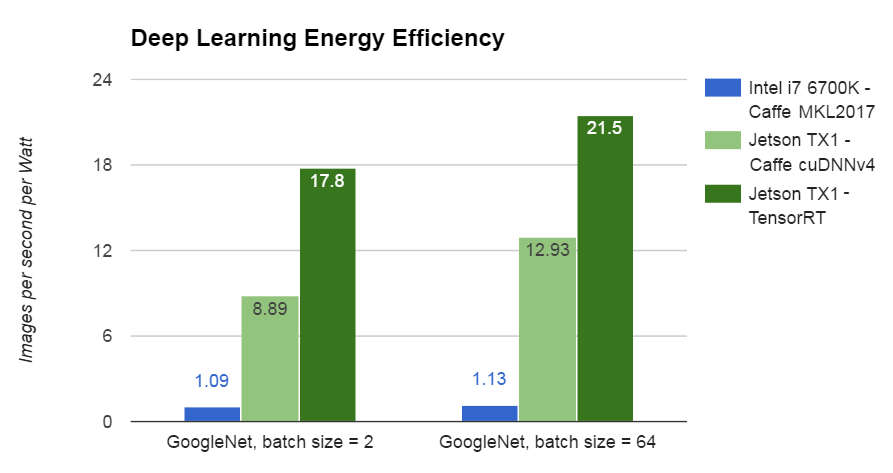
The results from Figure 3 are determined by dividing the measured GoogleNet images processed per second by the processor’s power consumption during the benchmark. These results are used batch size 2, although with batch size 64 Jetson TX1 is capable of 21.5 GoogleNet images/second/Watt. Starting from the network layer specification (the prototxt), TensorRT performs optimizations at the network level and above; for example, fusing kernels and processing more layers per pass, conserving system resources and memory bandwidth.
By connecting TensorRT to cameras and other sensors, deep learning networks can be evaluated in real time on board with live data. Useful for implementing navigation, motion control, and other autonomous functions, deep learning greatly reduces the amount of hard-coded software required to implement complex, intelligent machines. See this GitHub repo for a tutorial of using TensorRT to quickly recognize objects with Jetson TX1’s onboard camera, and for locating the coordinates of pedestrians in the video feed.
In addition to quickly evaluating neural networks, TensorRT can be effectively used alongside NVIDIA’s DIGITS workflow for interactive GPU-accelerated network training (see Figure 4). DIGITS can be run in the cloud or locally on a desktop, and provides easy configuration and interactive visualization of network training with Caffe or Torch. There are multiple DIGITS walkthrough examples available to get you started training networks with your own datasets. DIGITS saves a model snapshot every training epoch (pass through the training data). The desired model snapshot, or .caffemodel, along with the network prototxt specification are copied over to Jetson TX1, where TensorRT loads and parses the network files and builds the optimized execution plan.
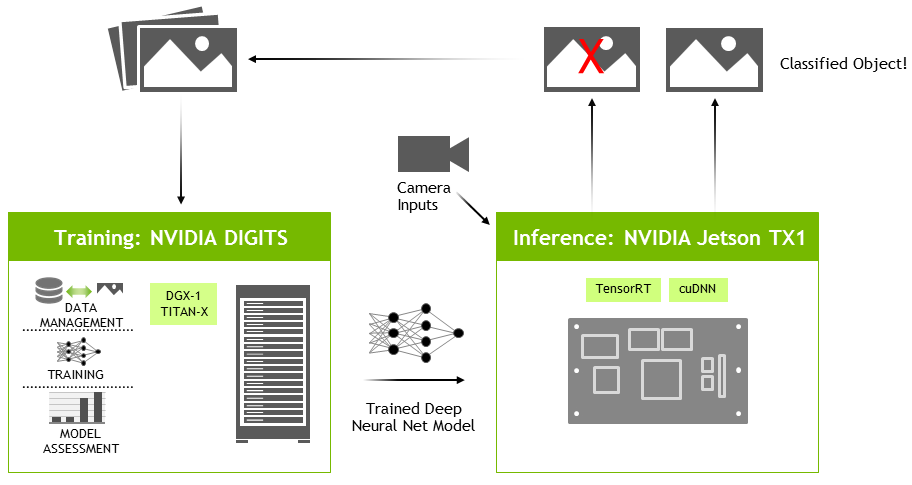
Using DIGITS with the DGX-1 supercomputer for training and TensorRT on Jetson, NVIDIA’s complete compute platform enables developers everywhere with end-to-end deep learning solutions for deploying advanced artificial intelligence and scientific research.
CUDA Toolkit 8.0 and cuDNN 5.1
CUDA Toolkit 8.0 includes the latest updates to CUDA for Jetson TX1’s integrated NVIDIA GPU. Host compiler support has been updated to include GCC 5.x and the NVCC CUDA compiler has been optimized for up to 2x faster compilation. CUDA 8 includes nvGRAPH, a new library of GPU-accelerated graph algorithms such as PageRank and single-source shortest paths. CUDA 8 also includes new APIs for using half-precision floating point computation (FP16) in CUDA kernels as well as in libraries such as cuBLAS and cuFFT. Version 5.1 of cuDNN, the CUDA Deep Neural Network library, supports the latest advanced network models like LSTMs (long short-term memory) and RNNs (recurrent neural networks). See this Parallel Forall post about the RNN modes now supported in cuDNN, including ReLU, Gated Recurrent Units (GRU), and LSTMs.
cuDNN has been integrated into all of the most popular deep learning frameworks, including Caffe, Torch, CNTK, TensorFlow and others. Using Torch compiled with bindings to cuDNN, recently available networks like LSTMs enable features in areas such as deep Reinforcement Learning, in which AI agents learn to operate online in real-world or virtual environments based on sensor state and feedback from a reward function. By unleashing deep reinforcement learners to explore their environments and adapt to changing conditions, AI agents develop understanding and adopt complex predictive and intuitive human-like behaviors. The OpenAI Gym project has many examples of virtual environments used for training AI agents.. In environments with significantly complex state spaces (like those found in many real-world scenarios), deep neural networks are used by the reinforcement learner to choose the next actions by estimating future potential reward based on sensory input (commonly referred to as Q-Learning and Deep Q-learning Networks:DQNs). Since DQNs are often quite large in order to map sensor states (like high-resolution camera and LIDAR data) to outputs for each potential action the agent can perform, cuDNN is crucial for accelerating the reinforcement learning network so the AI agent remains interactive and can learn in real time. Figure 5 shows the output of a DQN I wrote for learning on board Jetson TX1 in real time. The code for this example, available on GitHub, is implemented in Torch with cuDNN bindings, and has a C++ library API for integrating into robotic platforms such as the Robot Operating System (ROS).
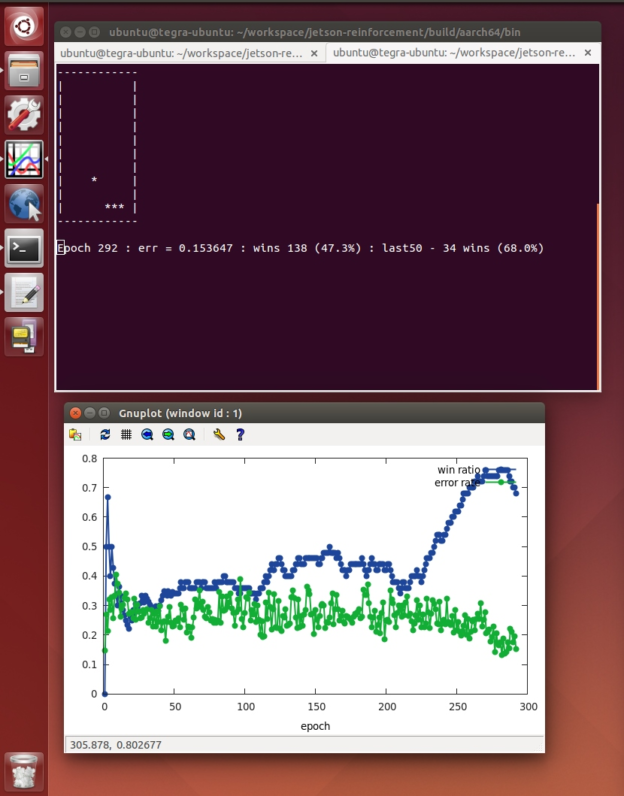
In many real-world robotics applications and sensor configurations a fully-observable state space may not be available, so the network can’t maintain instantaneous sensory access to the entire state of the environment. The GPU-accelerated LSTMs from cuDNN are particularly effective at solving this problem of partial-observability, relying on memory encoded from LSTMs to remember prior experiences and chain together observations. LSTMs are also useful in Natural Language Processing (NLP) applications with grammatical structure.
Jetson Multimedia SDK
Also included with JetPack 2.3, the new Jetson Multimedia API package offers developers lower-level API access for flexible application development while using the Tegra X1 hardware codec, MIPI CSI Video Ingest (VI) and Image Signal Processors (ISPs). This is in addition to the GStreamer media framework available in previous releases. The Jetson Multimedia APIs include camera ingest and ISP control, and Video4Linux2 (V4L2) for encode, decode, scaling and other functions. These lower-level APIs provide finer control over the underlying hardware blocks.
The V4L2 support offers access to video encode & decode devices, format conversion and scaling functionality, including support for EGL and efficient memory streaming. V4L2 for encode opens up many features like bit rate control, quality presets, low latency encoding, temporal tradeoff, providing motion vector maps and much more for flexible and rich application development. Decoder capability is significantly enhanced by the addition of robust error and information reporting, skip frame support, EGL image output and more. VL42 exposes the Jetson TX1’s powerful video hardware capabilities for image format conversion, scaling, cropping, rotating, filtering and multiple simultaneous stream encoding.
To assist developers in quickly integrating deep learning applications with data streaming sources, the Jetson Multimedia API is packaged with powerful examples of using the V4L2 codecs alongside TensorRT. Included in the Multimedia API package is the object detection network example from Figure 6 which is derived from GoogleNet and streams pre-encoded H.264 video data through the V4L2 decoder and TensorRT.

In contrast to core image recognition, object detection provides bounding locations within the image in addition to the classification, making it useful for tracking and obstacle avoidance. The Multimedia API sample network is derived from GoogleNet with additional layers for extracting the bounding boxes. At 960×540 half-HD input resolution, the object detection network captures at higher resolution than the original GoogleNet, while retaining real-time performance on Jetson TX1 using TensorRT.
Additional features in the Jetson Multimedia API package include ROI encoding, which allows definition of up to 6 regions of interest in a frame. This enables transmission and storage bandwidth optimization by allowing a higher bit rate to be assigned for only the regions of interest. To further promote efficient streaming between APIs like CUDA and OpenGL with EGLStreams, the NV dma_buf structure is exposed in the Multimedia API.
Camera ISP API
Based on Khronos OpenKCam, the low-level camera/ISP API libargus offers granular per-frame control over camera parameters and EGL stream outputs that allow efficient interoperation with GStreamer and V4L2 pipelines. The camera API gives developers lower-level access to MIPI CSI camera video ingest and configuration of ISP engines. Sample C++ code and the API reference are also included. The following example code snippet searches for available cameras, initializes the camera stream, and captures a video frame.
#include <Argus/Argus.h>
#include <EGLStream/EGLStream.h>
#include
using namespace Argus;
// enumerate camera devices and create Argus session
UniqueObj cameraProvider(CameraProvider::create());
CameraProvider* iCameraProvider = interface_cast(cameraProvider);
std::vector<CameraDevice*> cameras;
Status status = iCameraProvider->getCameraDevices(&cameras);
UniqueObj captureSession(iCameraProvider->createCaptureSession(cameras[0],
&status));
ICaptureSession *iSession = interface_cast(captureSession);
// configure the camera output streaming parameters
UniqueObj streamSettings(iSession->createOutputStreamSettings());
IOutputStreamSettings *iStreamSettings = interface_cast(streamSettings);
iStreamSettings->setPixelFormat(PIXEL_FMT_YCbCr_420_888);
iStreamSettings->setResolution(Size(640, 480));
// connect the camera output to EGLStream
UniqueObj stream(iSession->createOutputStream(streamSettings.get()));
UniqueObj consumer(EGLStream::FrameConsumer::create(stream.get()));
EGLStream::IFrameConsumer *iFrameConsumer = interface_cast(consumer);
// acquire a frame from EGLStream
const uint64_t FIVE_SECONDS_IN_NANOSECONDS = 5000000000;
UniqueObj frame(iFrameConsumer->acquireFrame(FIVE_SECONDS_IN_NANOSECONDS,
&status));
EGLStream::IFrame *iFrame = interface_cast(frame);
EGLStream::Image *image = iFrame->getImage();
The Jetson TX1 Developer Kit includes a 5MP camera module with the Omnivision OV5693 RAW image sensor. ISP support for that module is now enabled via either the camera API or GStreamer plugin. Full support for a 2.1MP camera from Leopard Imaging’s IMX185 is also available in this release via the camera/ISP API (see Leopard Imaging’s Jetson Camera Kit). ISP support for additional sensors is enabled via Preferred Partner services. In addition, USB cameras, CSI cameras with integrated ISP, and RAW output CSI cameras in ISP-bypass mode can be used with the V4L2 API.
Going forward, all camera device drivers should use the V4L2 media-controller sensor kernel driver API—see the V4L2 Sensor Driver Programming Guide for details and a full example based on the Developer Kit camera module.
Intelligent Machines Everywhere
JetPack 2.3 contains all the latest tools and components for deploying production-grade high-performance embedded systems using NVIDIA Jetson TX1 and GPU technology. Powering the latest breakthroughs in deep learning and artificial intelligence, NVIDIA GPUs are used to solve important challenges faced everyday. Using GPUs and the tools in JetPack 2.3, anyone can get started designing advanced AI for solving real-world problems. Visit NVIDIA’s Deep Learning Institute for hands-on training courses and these Jetson wiki resources available about deep learning. NVIDIA’s Jetson TX1 DevTalk forum is also available for technical support and discussion with developers in the community. Download JetPack today and install the latest NVIDIA tools for Jetson and PC.









