Update: Jetson Nano and JetBot webinars. We’ve received a high level of interest in Jetson Nano and JetBot, so we’re hosting two webinars to cover these topics. The Jetson Nano webinar discusses how to implement machine learning frameworks, develop in Ubuntu, run benchmarks, and incorporate sensors. Register for the Jetson Nano webinar. A Jetbot webinar has Python GPIO library tutorials and information on how to train neural networks and perform real-time object detection with JetBot. Register for the JetBot webinar. Both webinars are roughly an hour long and feature a Q&A session at the end.

NVIDIA announced the Jetson Nano Developer Kit at the 2019 NVIDIA GPU Technology Conference (GTC), a $99 computer available now for embedded designers, researchers, and DIY makers, delivering the power of modern AI in a compact, easy-to-use platform with full software programmability. Jetson Nano delivers 472 GFLOPS of compute performance with a quad-core 64-bit ARM CPU and a 128-core integrated NVIDIA GPU. It also includes 4GB LPDDR4 memory in an efficient, low-power package with 5W/10W power modes and 5V DC input, as shown in figure 1.
The newly released JetPack 4.2 SDK provides a complete desktop Linux environment for Jetson Nano based on Ubuntu 18.04 with accelerated graphics, support for NVIDIA CUDA Toolkit 10.0, and libraries such as cuDNN 7.3 and TensorRT 5.The SDK also includes the ability to natively install popular open source Machine Learning (ML) frameworks such as TensorFlow, PyTorch, Caffe, Keras, and MXNet, along with frameworks for computer vision and robotics development like OpenCV and ROS.
Full compatibility with these frameworks and NVIDIA’s leading AI platform makes it easier than ever to deploy AI-based inference workloads to Jetson. Jetson Nano brings real-time computer vision and inferencing across a wide variety of complex Deep Neural Network (DNN) models. These capabilities enable multi-sensor autonomous robots, IoT devices with intelligent edge analytics, and advanced AI systems. Even transfer learning is possible for re-training networks locally onboard Jetson Nano using the ML frameworks.
The Jetson Nano Developer Kit fits in a footprint of just 80x100mm and features four high-speed USB 3.0 ports, MIPI CSI-2 camera connector, HDMI 2.0 and DisplayPort 1.3, Gigabit Ethernet, M.2 Key-E module, MicroSD card slot, and 40-pin GPIO header. The ports and GPIO header works out-of-the-box with a variety of popular peripherals, sensors, and ready-to-use projects, such as the 3D-printable deep learning JetBot that NVIDIA has open-sourced on GitHub.
The devkit boots from a removable MicroSD card which can be formatted and imaged from any PC with an SD card adapter. The devkit can be conveniently powered via either the Micro USB port or a 5V DC barrel jack adapter. The camera connector is compatible with affordable MIPI CSI sensors including modules based on the 8MP IMX219, available from Jetson ecosystem partners. Also supported is the Raspberry Pi Camera Module v2, which includes driver support in JetPack. Table 1 shows key specifications.
| Processing | |
| CPU | 64-bit Quad-core ARM A57 @ 1.43GHz |
| GPU | 128-core NVIDIA Maxwell @ 921MHz |
| Memory | 4GB 64-bit LPDDR4 @ 1600MHz | 25.6 GB/s |
| Video Encoder* | 4Kp30 | (4x) 1080p30 | (2x) 1080p60 |
| Video Decoder* | 4Kp60 | (2x) 4Kp30 | (8x) 1080p30 | (4x) 1080p60 |
| Interfaces | |
| USB | 4x USB 3.0 A (Host) | USB 2.0 Micro B (Device) |
| Camera | MIPI CSI-2 x2 (15-position Flex Connector) |
| Display | HDMI | DisplayPort |
| Networking | Gigabit Ethernet (RJ45) |
| Wireless | M.2 Key-E with PCIe x1 |
| Storage | MicroSD card (16GB UHS-1 recommended minimum) |
| Other I/O | (3x) I2C | (2x) SPI | UART | I2S | GPIOs |
The devkit is built around a 260-pin SODIMM-style System-on-Module (SoM), shown in figure 2. The SoM contains the processor, memory, and power management circuitry. The Jetson Nano compute module is 45x70mm and will be shipping starting in June 2019 for $129 (in 1000-unit volume) for embedded designers to integrate into production systems. The production compute module will include 16GB eMMC onboard storage and enhanced I/O with PCIe Gen2 x4/x2/x1, MIPI DSI, additional GPIO, and 12 lanes of MIPI CSI-2 for connecting up to three x4 cameras or up to four cameras in x4/x2 configurations. Jetson’s unified memory subsystem, which is shared between CPU, GPU, and multimedia engines, provides streamlined ZeroCopy sensor ingest and efficient processing pipelines.

Deep Learning Inference Benchmarks
Jetson Nano can run a wide variety of advanced networks, including the full native versions of popular ML frameworks like TensorFlow, PyTorch, Caffe/Caffe2, Keras, MXNet, and others. These networks can be used to build autonomous machines and complex AI systems by implementing robust capabilities such as image recognition, object detection and localization, pose estimation, semantic segmentation, video enhancement, and intelligent analytics.
Figure 3 shows results from inference benchmarks across popular models available online. See here for the instructions to run these benchmarks on your Jetson Nano. The inferencing used batch size 1 and FP16 precision, employing NVIDIA’s TensorRT accelerator library included with JetPack 4.2. Jetson Nano attains real-time performance in many scenarios and is capable of processing multiple high-definition video streams.
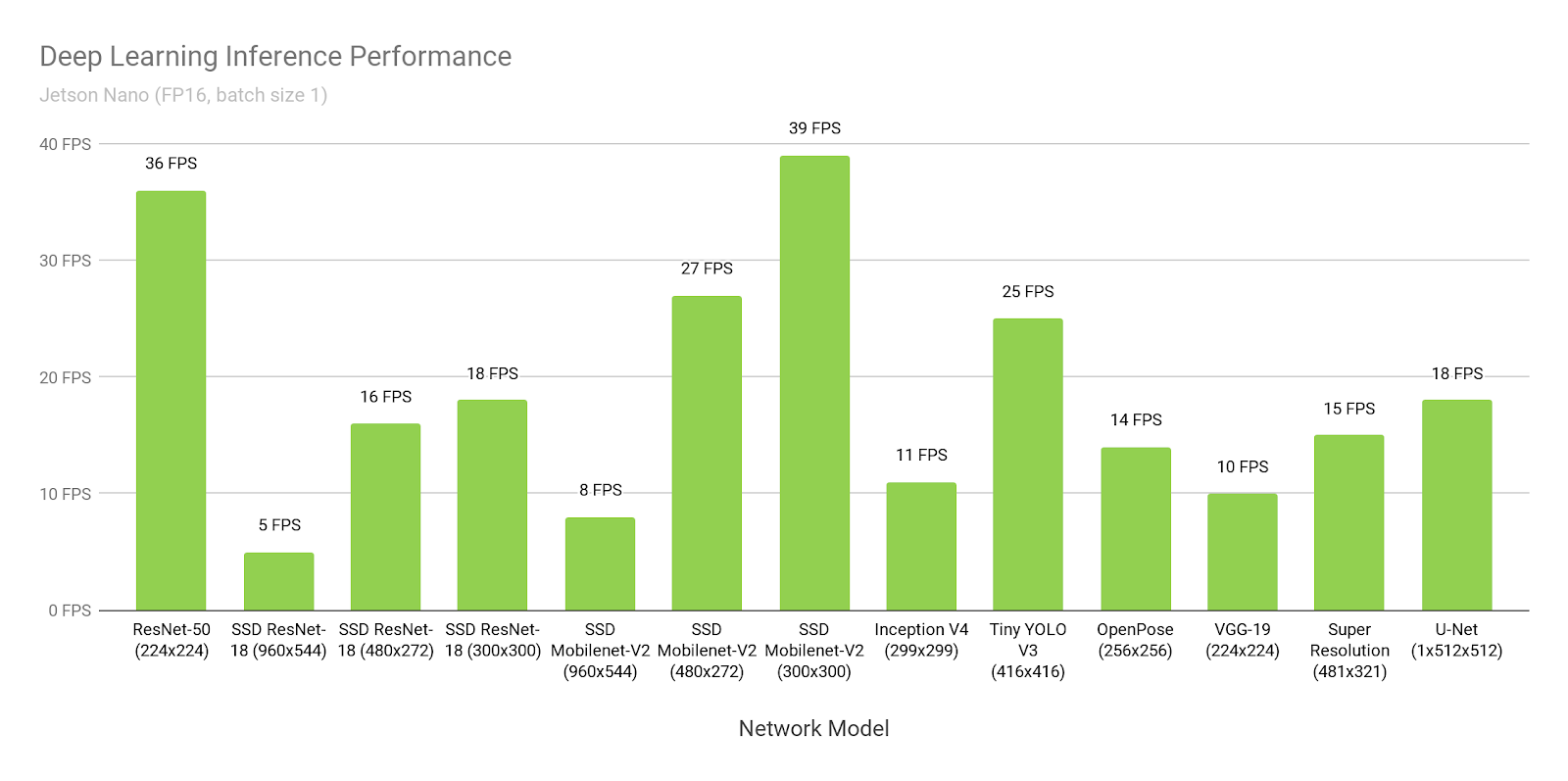
Table 2 provides full results, including the performance of other platforms like the Raspberry Pi 3, Intel Neural Compute Stick 2, and Google Edge TPU Coral Dev Board:
| Model | Application | Framework | NVIDIA Jetson Nano | Raspberry Pi 3 | Raspberry Pi 3 + Intel Neural Compute Stick 2 | Google Edge TPU Dev Board |
| ResNet-50 (224×224) |
Classification | TensorFlow | 36 FPS | 1.4 FPS | 16 FPS | DNR |
| MobileNet-v2 (300×300) |
Classification | TensorFlow | 64 FPS | 2.5 FPS | 30 FPS | 130 FPS |
| SSD ResNet-18 (960×544) | Object Detection | TensorFlow | 5 FPS | DNR | DNR | DNR |
| SSD ResNet-18 (480×272) | Object Detection | TensorFlow | 16 FPS | DNR | DNR | DNR |
| SSD ResNet-18 (300×300) | Object Detection | TensorFlow | 18 FPS | DNR | DNR | DNR |
| SSD Mobilenet-V2 (960×544) | Object Detection |
TensorFlow | 8 FPS | DNR | 1.8 FPS | DNR |
| SSD Mobilenet-V2 (480×272) | Object Detection | TensorFlow | 27 FPS | DNR | 7 FPS | DNR |
| SSD Mobilenet-V2
(300×300) |
Object Detection | TensorFlow | 39 FPS | 1 FPS | 11 FPS | 48 FPS |
| Inception V4
(299×299) |
Classification | PyTorch | 11 FPS | DNR | DNR | 9 FPS |
| Tiny YOLO V3
(416×416) |
Object Detection | Darknet | 25 FPS | 0.5 FPS | DNR | DNR |
| OpenPose
(256×256) |
Pose Estimation | Caffe | 14 FPS | DNR | 5 FPS | DNR |
| VGG-19 (224×224) | Classification | MXNet | 10 FPS | 0.5 FPS | 5 FPS | DNR |
| Super Resolution (481×321) | Image Processing | PyTorch | 15 FPS | DNR | 0.6 FPS | DNR |
| Unet
(1x512x512) |
Segmentation | Caffe | 18 FPS | DNR | 5 FPS | DNR |
DNR (did not run) results occurred frequently due to limited memory capacity, unsupported network layers, or hardware/software limitations. Fixed-function neural network accelerators often support a relatively narrow set of use-cases, with dedicated layer operations supported in hardware, with network weights and activations required to fit in limited on-chip caches to avoid significant data transfer penalties. They may fall back on the host CPU to run layers unsupported in hardware and may rely on a model compiler that supports a reduced subset of a framework (TFLite, for example).
Jetson Nano’s flexible software and full framework support, memory capacity, and unified memory subsystem, make it able to run a myriad of different networks up to full HD resolution, including variable batch sizes on multiple sensor streams concurrently. These benchmarks represent a sampling of popular networks, but users can deploy a wide variety of models and custom architectures to Jetson Nano with accelerated performance. And Jetson Nano is not just limited to DNN inferencing. Its CUDA architecture can be leveraged for computer vision and Digital Signal Processing (DSP), using algorithms including FFTs, BLAS, and LAPACK operations, along with user-defined CUDA kernels.
Multi-Stream Video Analytics
Jetson Nano processes up to eight HD full-motion video streams in real-time and can be deployed as a low-power edge intelligent video analytics platform for Network Video Recorders (NVR), smart cameras, and IoT gateways. NVIDIA’s DeepStream SDK optimizes the end-to-end inferencing pipeline with ZeroCopy and TensorRT to achieve ultimate performance at the edge and for on-premises servers. The video below shows Jetson Nano performing object detection on eight 1080p30 streams simultaneously with a ResNet-based model running at full resolution and a throughput of 500 megapixels per second (MP/s).
DeepStream application running on Jetson Nano with ResNet-based
object detector concurrently on eight independent 1080p30 video streams.
The block diagram in figure 4 shows an example NVR architecture using Jetson Nano for ingesting and processing up to eight digital streams over Gigabit Ethernet with deep learning analytics. The system can decode 500 MP/s of H.264/H.265 and encode 250 MP/s of H.264/H.265 video.
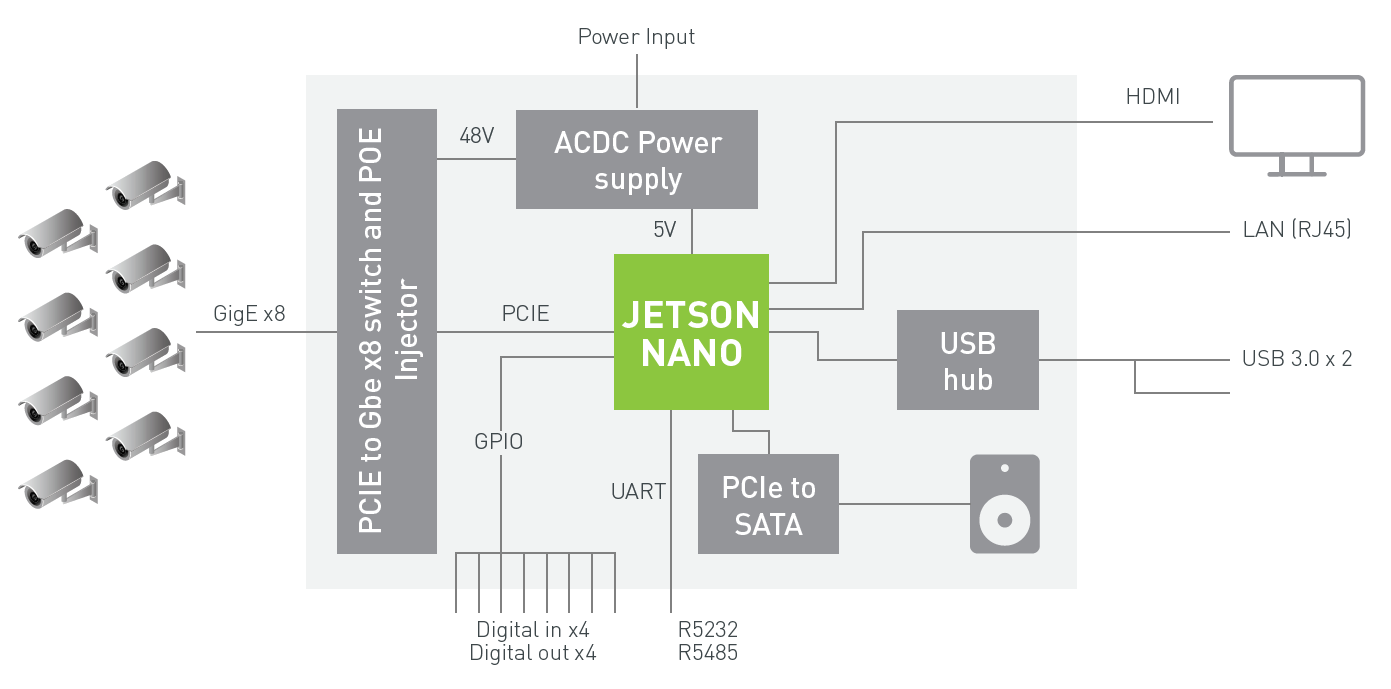
DeepStream SDK support for Jetson Nano is planned for Q2 2019 release. Please join the DeepStream Developer Program to receive notifications about the upcoming release.
JetBot
NVIDIA JetBot shown in figure 5 is a new open source autonomous robotics kit that provides all the software and hardware plans to build an AI-powered deep learning robot for under $250. The hardware materials include Jetson Nano, IMX219 8MP camera, 3D-printable chassis, battery pack, motors, I2C motor driver, and accessories.

The project provides you with easy to learn examples through Jupyter notebooks on how to write Python code to control the motors, train JetBot to detect obstacles, follow objects like people and household objects, and train JetBot to follow paths around the floor. New capabilities can be created for JetBot by extending the code and using the AI frameworks.
There are also ROS nodes available for JetBot, supporting ROS Melodic for those who wish to integrate ROS-based applications and capabilities such as SLAM and advanced path planning. The GitHub repository containing the ROS nodes for JetBot also includes a model for the Gazebo 3D robotics simulator allowing new AI behaviors to be developed and tested in virtual environments before being deployed to the robot. The Gazebo simulator generates synthetic camera data and runs onboard the Jetson Nano, too.
Hello AI World
Hello AI World offers a great way to start using Jetson and experiencing the power of AI. In just a couple of hours, you can have a set of deep learning inference demos up and running for real-time image classification and object detection (using pre-trained models) on the Jetson Nano Developer Kit with JetPack SDK and NVIDIA TensorRT. The tutorial focuses on networks related to computer vision and includes the use of live cameras. You also get to code your own easy-to-follow recognition program in C++. Available Deep Learning ROS Nodes integrate these recognition, detection, and segmentation inferencing capabilities with ROS for incorporation into advanced robotic systems and platforms. These real-time inferencing nodes can easily be dropped into existing ROS applications. Figure 6 highlights some examples.

Developers who want to try training their own models can follow the full “Two Days to a Demo” tutorial, which covers the re-training and customization of image classification, object detection, and semantic segmentation models with transfer learning. Transfer learning fine tunes the model weights for a particular dataset and avoids having to train the model from scratch. Transfer learning is most effectively performed on a PC or cloud instance with an NVIDIA discrete GPU attached, since training requires more computational resources and time than inferencing.
However, since Jetson Nano can run the full training frameworks like TensorFlow, PyTorch, and Caffe, it’s also able to re-train with transfer learning for those who may not have access to another dedicated training machine and are willing to wait longer for results. Table 3 highlights some initial results of transfer learning from the Two Days to a Demo tutorial with PyTorch using Jetson Nano for training Alexnet and ResNet-18 on a 200,000 image, 22.5GB subset of ImageNet:
| Network | Batch Size | Time per Epoch | Images/sec |
| AlexNet | 64 | 1.16 hours | 45 |
| ResNet-18 | 64 | 3.22 hours | 16 |
The time per epoch is how long it takes to make a full pass through the training dataset of 200K images. Classification networks may need as little as 2-5 epochs for usable results and production models should be trained for more epochs on a discrete GPU system until they reach maximum accuracy. However, Jetson Nano enables you to experiment with deep learning and AI on a low-cost platform by letting the network re-train overnight. Not all custom datasets may be as large as the 22.5GB example used here. Thus, the images/second indicate the Jetson Nano’s training performance, with the time per epoch scaling with the size of the dataset, training batch size, and network complexity. Other models can be re-trained on Jetson Nano too with increased training time.
AI for Everyone
The compute performance, compact footprint, and flexibility of Jetson Nano brings endless possibilities to developers for creating AI-powered devices and embedded systems. Get started today with the Jetson Nano Developer Kit for only $99, which will be sold through our main global distributors and can also be purchased from maker channels, Seeed Studio and SparkFun. Visit our Embedded Developer Zone to download the software and documentation, and browse open-source projects available for Jetson Nano. Join the community on the Jetson DevTalk forums for support, and be sure to share your projects. We look forward to seeing what you create!