The software industry has recently seen a huge shift in how software deployments are done thanks to technologies such as containers and orchestrators. While container technologies have been around, credit goes to Docker for making containers mainstream, by greatly simplifying the process of creating, managing and deploying containerized applications.
We’re now seeing a similar paradigm shift for AI software development. Teams of developers and data scientists are increasingly moving their training and inference workloads from one-developer-one-workstation model to shared centralized infrastructure, to improve resource utilization and sharing. With container orchestration tools such as Kubernetes, Docker Swarm and Marathon, developers and data scientists get more control over how and when their apps are run and ops teams don’t have to deal with deploying and managing workloads.

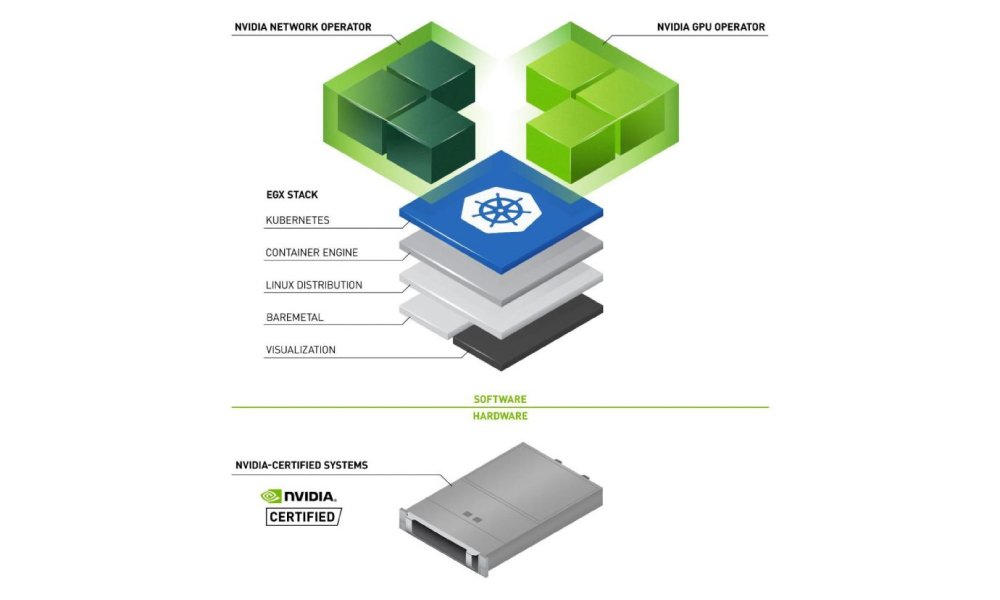
NVIDIA actively contributes to making container technologies and orchestrators GPU friendly, enabling the same deployment best practices that exists for traditional software development and deployment to be applied to AI software development.
Kubernetes for AI Deployments
If you’re new to Kubernetes, you can think of it as the operating system that runs on your cluster.
Just like how the operating system abstracts away the various hardware resources, Kubernetes does the same with a cluster and abstracts away details about the actually infrastructure setup. This offers users a consistent runtime and development environment for a cluster, similar to locally-hosted operating systems such as Linux and Windows. Data scientists and developers don’t have to worry about infrastructure-related issues. They can focus on their apps and let Kubernetes manage the infrastructure.
Since AI software relies on NVIDIA GPUs to accelerate training and inference, it’s important that Kubernetes be GPU-aware. NVIDIA worked closely with the Kubernetes community to integrate the NVIDIA Device Plugin, which exposes GPUs to Kubernetes and allows it to keep track of GPU health in the cluster.
Before we jump into how we can use Kubernetes to run large-scale AI experiments, let’s introduce a few key concepts you should know as you follow along with the example.
Containers, Pods, and Jobs
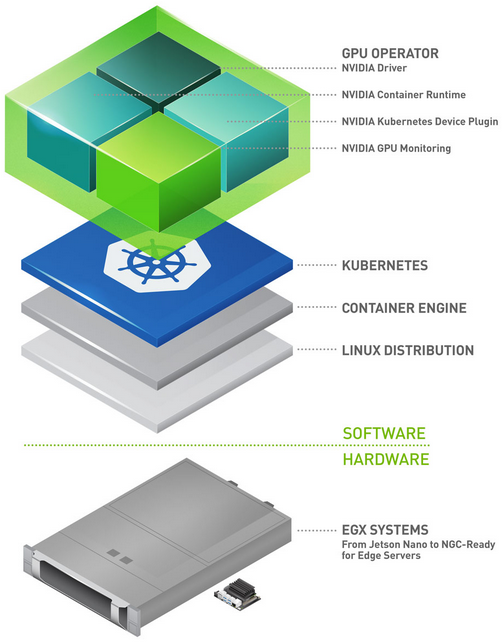
The basic deployable unit in Kubernetes is called a Pod. A Pod contains one or more processes in co-located containers which share the same volumes, IP address, and namespace. A pod never spans multiple nodes. For a training workload, a Pod may only consist of one container running your favorite deep learning framework as illustrated in figure 2.
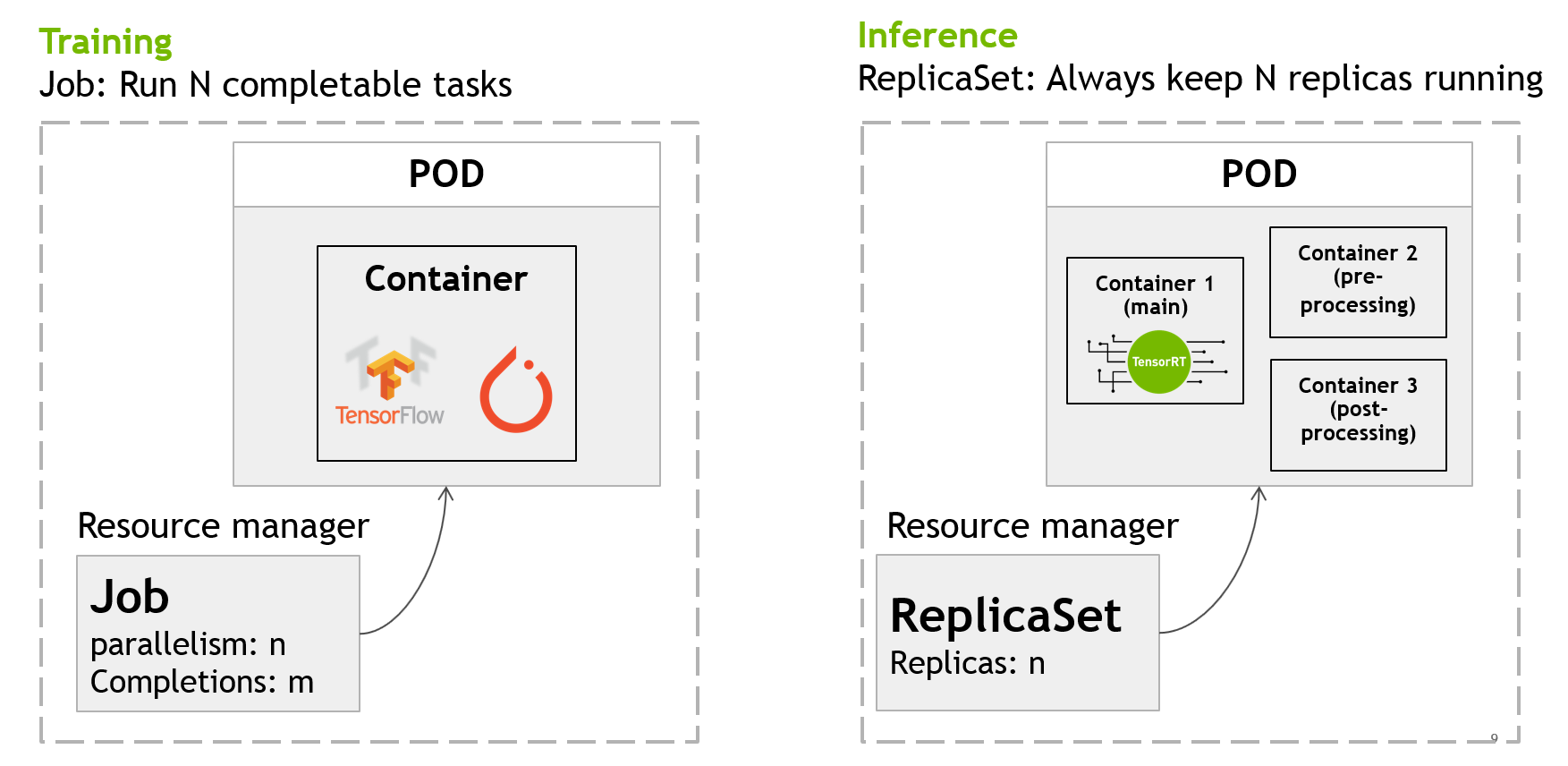
A Pod is an unmanaged resource in Kubernetes. This means if a failure occurs, the pod simply ceases to exist. Therefore, we can introduce a resource manager called Job, which is responsible for automatically rescheduling failed pods onto different nodes. Job resources are useful for workloads that go to completion like a training job.
A Pod can also have multiple containers to run processes like data pre- and post-processing for inference deployments. Inference workloads typically run as highly available services, running as continuous tasks that are never considered complete. A different resource manager called ReplicaSet can make sure that specified replicas of this job are always available and running forever unless terminated by the user. This post only focuses on training jobs. You can find more information about inference deployment on Kubernetes in an earlier blog post: NVIDIA TensorRT Inference Server Boosts Deep Learning Inference.
Kubernetes boils down to one key idea: infrastructure abstraction. A user should never have to think in terms of servers and nodes. They should focus on specifying jobs and containers in a pod, and Kubernetes takes care of all the underlying infrastructure management.
Now that we’ve briefly introduced Pods and Job resources, Let’s now dive into our example.
Hyperparameters Optimization for Training a Model on the CIFAR10 Dataset
Hyperparameters for a machine learning model are options not optimized or learned during the training phase. This is analogous to an aircraft pilot tuning knobs and pressing the right buttons before putting the plane on autopilot. The pilot is the expert, knowing from experience what configuration to choose before engaging the autopilot.
In machine learning, hyperparameters typically include options such as learning rate schedule, batch size, data augmentation options and others. Each option greatly affects the model accuracy on the same dataset. Two of the most common strategies for selecting the best hyperparameters for a model are grid search and random search. In the grid search method (also known as the parameter sweep method) you define the search space by enumerating all possible hyperparameter values and train a model on each set of values. Random search only select random sets of values sampled from the exhaustive set. The results of each training run are then validated against a separate validation set.
A large body of literature exists discussing hyperparameters optimization. Other more sophisticated approaches can be used, such as bayesian optimization. However, when starting from scratch, random search and grid search are still the best approaches to narrow down the search space.
The challenge with grid search and random search is that introducing more than a few hyperparameters and options quickly results in a combinatorial explosion. Add to this the training time required for each hyperparameter set and the problem quickly becomes intractable. Thankfully, this is also an embarrassingly parallel problem since each training run can be performed independently of others.
This is where Kubernetes comes in.
In this example, I present a general framework for running large-scale hyperparameter search experiments using Kubernetes on a GPU cluster as shown in Figure 3. The framework is flexible and allows you to do grid search or random search and implements “version everything” so you can trace back all previously run experiments.
The specific problem that we’ll solve is finding the best hyperparameters for a model trained on CIFAR10 dataset that achieves state-of-the-art accuracy.
Current state-of-the-art accuracy for CIFAR10 is about ~94 percent on Stanford’s DAWNBench webpage. Our example begins with a model derived from the submission by David Page from myrtle.ai. Our goal is to find the best hyperparameters for this model architecture that achieves the best accuracy on the test set.
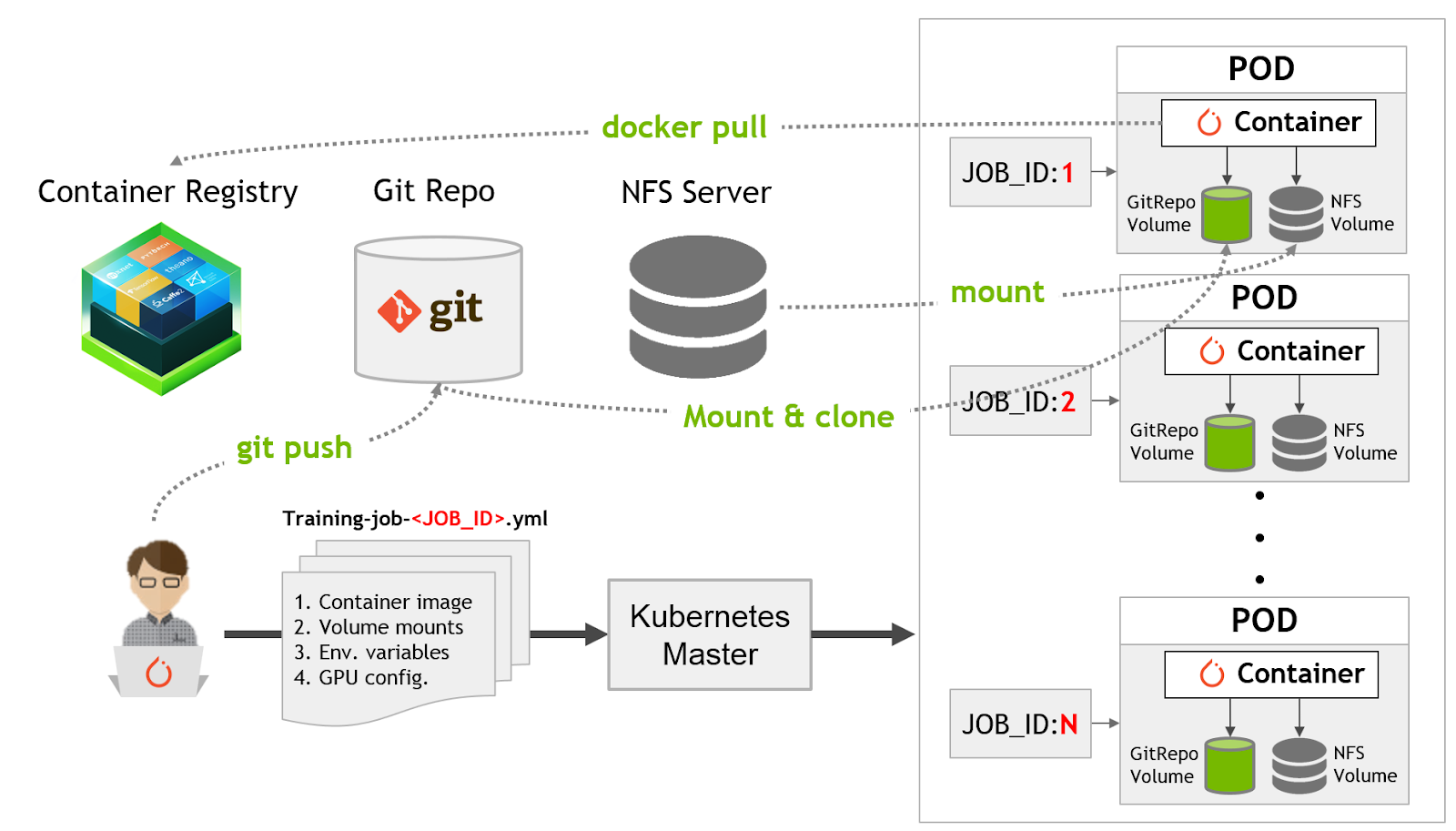
Assuming you’ve already started by setting up a Kubernetes cluster, our solution for running hyperparameter search experiments consists of the following 7 steps:
- Specify hyperparameter search space
- Develop a training script that can accept hyperparameters and apply them to the training routine
- Push training scripts and hyperparameters in a Git repository for tracking
- Upload training and test dataset to a network storage such as NFS server
- Specify Kubernetes Job specification files with application container to run, volumes to mount and GPU resources required
- Submit multiple Kubernetes job requests (one per hyperparameter set) using above specification template
- Analyze the results and pick the hyperparameter set
Let’s walk through each of these steps in detail, so you can follow along and reproduce the results.
Where can I get the code?
You can find all the code and Kubernetes specification files used in this example on GitHub. The best way to follow along with this walkthrough is to first fork the repo into your personal GitHub repo, then clone it locally so you can make changes. As stated earlier, everything in this framework is versioned. All code changes should first be pushed to your Git repository and each Pod will automatically clone the repository before running training.
If you’re new to git, I suggest following the instruction on this link on how to fork projects and clone them locally.
Step 0: Setup your Kubernetes cluster
First you need to set up a Kubernetes cluster that has at least 1 node with a supported GPU. As we’ll see later, the Kubernetes API is agnostic to the number of nodes and where they’re located. Therefore, adding more nodes and GPUs along the way should not affect the way things work.
To set up Kubernetes on your GPU cluster, follow the instructions on the NVIDIA datacenter documentation page.
This example has been tested with Kubernetes version 1.10.11
Clone the example repo on the master node by issuing git clone command. Remember to first fork the repository to your personal repo and then replace <your_github_username> with your username.
> mkdir ~/k8s-experiment && cd ~/k8s-experiment > git clone https://github.com/<your_github_username>/kubernetes-hyperparam-exp.git > cd kubernetes-hyperparam-exp
Step 1: Specify hyperparameter search space
After you’ve cloned the repo locally, let’s start making some changes to specify hyperparameters. Open the file generate_hyperparam_combinations.py and update the hyper_params variable to specify the hyperparameter space that you wish to cover. You can specify specific values, ranges or samples from specific probability distributions.
hyper_params = {
'max_learning_rate': [0.4, 0.6],
'data_aug_cutout_size': [5, 12],
'batch_size': [128, 512],
'momentum': [0.9, 0.99],
'batch_norm': ['on']
}
For this example we’ve chosen 5 different hyperparameters:
- max_learning_rate: Specifies the maximum learning rate in the learning rate schedule for training specified in cifar10_train.py:
lr_schedule = PiecewiseLinear([0, 5, 24], [0, max_learning_rate, 0]). Number of epochs is kept constant at 24.
- data_aug_cutout_size: size of cutout patches1 during data augmentation
- batch_size: size of training minibatch
- momentum: value for SGD optimizer2
- batch_norm: on/off, if batch normalization3 should be included after convolution layer
After specifying the hyperparameters run the following script.
> python generate_hyperparam_combinations.py Total number of hyperparameter sets: 16 Hyperparameter sets saved to: hyperparams.yml
This should generate a YAML file called hyperparams.yml, a plain text file which stores all the hyperparameter sets. For the above example, you should see a total of:
(2 max_learning_rate) x (2 data_aug_cutout_size) x (2 batch_size) x (2 momentum) x (1 batch_norm) = 16 hyperparameter sets
For example, if you wanted to also test accuracy with batch_norm set to ‘off’ and a batch_size of 64, you’ll end up with 48 hyperparameter sets. Similarly if you wanted to sweep a whole range of values or introduce randomly generated values, simply add it to the hyper_params variable in generate_hyperparam_combinations.py and run it, and it’ll generate the hyperparams.yml with all the combinations.
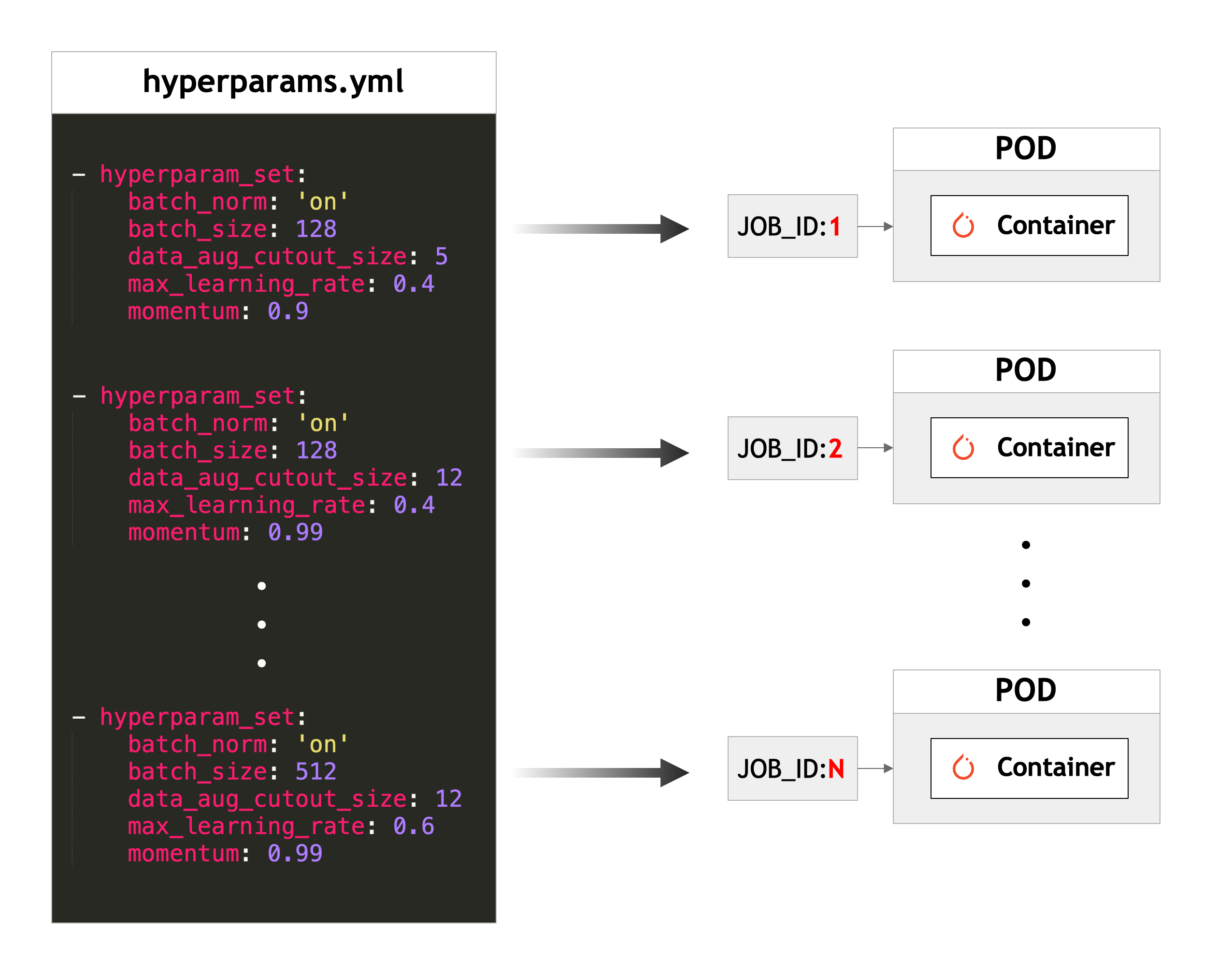
This is the most important file in this example since each Kubernetes Pod will read this file and pick one hyperparameter set to run training on as illustrated in figure 4.
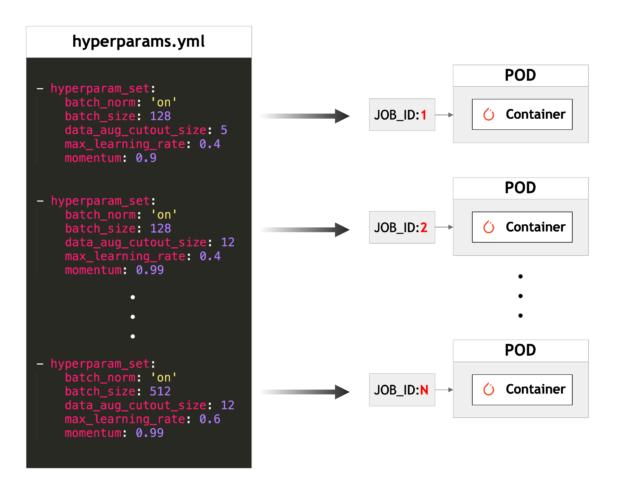
In Step 3, we’ll push these changes back to your personal GitHub repository, so that each Kubernetes Pod can pull the updated hyperparams.yml file. The entries in the file look like the listing below.
> cat hyperparams.yml - hyperparam_set: batch_norm: 'on' batch_size: 128 data_aug_cutout_size: 5 max_learning_rate: 0.4 momentum: 0.9 - hyperparam_set: batch_norm: 'on' batch_size: 512 data_aug_cutout_size: 5 max_learning_rate: 0.4 momentum: 0.9 ...
Next we define our training routine.
Step 2: Develop training script that can accept hyperparameters and apply them to the training routine
Now let’s train a neural network on the CIFAR10 dataset [4]. The training script cifar10_train.py is a modified version of the current winning entry in the Stanford DAWNBench submission list by David Page from myrtle.ai.
Our training script already includes the following modification so you don’t have to make any changes to run this particular example. The changes are presented here as a learning tool.
First, it implements a function called get_hyperparameters to import hyperparameters from hyperparams.yml we created in Step 1
When the training script executes on a Kubernetes worker node, it queries its unique job_id from an environment variable called JOB_ID which is unique to each Kubernetes Job. It then reads hyperparams.yml and returns the hyperparameter set corresponding the job id: hyper_param_set[job_id-1]["hyperparam_set"]
def get_hyperparameters(job_id):
with open("hyperparams.yml", 'r') as stream:
hyper_param_set = yaml.load(stream)
return hyper_param_set[job_id-1]["hyperparam_set"]
The second modification in cifar10_train.py applies these hyperparameters to the training run:
# Load hyperparameters hyperparams = get_hyperparameters(job_id) max_learning_rate = hyperparams["max_learning_rate"] data_aug_cutout_size = hyperparams["data_aug_cutout_size"] batch_size = hyperparams["batch_size"] momentum = hyperparams["momentum"] use_bn = hyperparams["batch_norm"]
Rest of cifar10_train.py consists of code to based on PyTorch to run training on a single GPU.
Step 3: Push training scripts and hyperparameters in a Git repository for tracking
In order to make the hyperparameters sets inhyperparams.yml you generated in Step 2 available to all Pods once you submit jobs, you need to push the changes back to your git repository. You may be asked to provide your GitHub login details.
> git add hyperparams.yml > git commit -m "Updated hyperparameters. Includes 16 hyperparameter sets" > git push
Step 4: Upload training and test dataset to a network storage such as NFS server
To avoid duplicating the dataset on each Kubernetes Pod, we’ll set up a network accessible storage location with the training and test datasets that every worker can access. In this example, we’ll also use the same network accessible storage to aggregate all the training results from each Pod. In practice, datasets are typically immutable and workers are given read-only access to them. Therefore, a separate network storage can be set up for aggregating training results from each Pod.
Kubernetes supports several types of volumes, including awsElasticBlockStore and gcePersistentDisk if you’re setting up your cluster on AWS or Google Cloud Platform, respectively. For this example we’ll setup a simple network file storage.
To follow along, set up an NFS server on the master node. You could set it up on a different server, or run it as a deployed application on Kubernetes, if you prefer. First download the cifar10 dataset into a directory and then export it to the NFS server. Run the following lines of code (requires PyTorch) to download the CIFAR10 dataset.
> python >>> import torchvision >>> DATA_DIR = ‘/path/to/dataset’ >>> train_set_raw = torchvision.datasets.CIFAR10(root=DATA_DIR, train=True, download=True) >>> test_set_raw = torchvision.datasets.CIFAR10(root=DATA_DIR, train=False, download=True)
Now, that we’ve downloaded the dataset, we can setup an NFS share and export ‘path/to/dataset’. If you’re on Ubuntu, follow the steps outlined on their help page: https://help.ubuntu.com/lts/serverguide/network-file-system.html.en
Step 5: Specify Kubernetes Job specification files in YAML
We’re now ready to tell Kubernetes to run our hyperparameter sweep experiment. Kubernetes makes it very easy to spin up resources using configuration files written in YAML. Kubernetes supports both YAML and JSON, but YAML tends to be much friendlier to read and write. If you’re not familiar with it, you’ll see how easy it is to use.
Navigate to ~/k8s-experiment/kubernetes-hyperparam-exp (the directory where you cloned this code) and open cifar10-job-template.ymlusing your favorite editor.
> nano cifar10-job-template.yml
Let’s first take a look at the key parts of the template yaml spec file.
Application section:
containers:
- name: pytorch
image: nvcr.io/nvidia/pytorch:18.11-py3
workingDir: /cifar10-training
env:
- name: JOB_ID
value: "$ITEM"
command: ["bash"]
args: ["-c","python cifar10_train.py"]
computeResourceRequests: ["nvidia-gpu"]
In this example, each job runs a single container. We specify that Kubernetes needs to pull the PyTorch (18.11) container from the NVIDIA GPU Cloud (NGC) container registry.
Next we specify an environment variable called JOB_ID, with a value currently called $ITEM. This placeholder will get replaced by a unique number for each Job, as we’ll see shortly in Step 6.
Command and argstells Kubernetes which command to run inside the container. Notice that every container runs the same cifar10_train.py script. So how does each worker know what hyperparameter set to choose and run?
This is where the environment variable JOB_ID comes in. Kubernetes introduces an environment variable in each container and cifar10_train.py will read the environment variable and pick the corresponding hyperparameter set from hyperparams.yml as illustrated in figure 4.
Volumes section:
volumes:
- name: cifar10-training
gitRepo:
repository: https://github.com/<your_github_username>/kubernetes-hyperparam-exp.git
revision: master
directory: .
- name: cifar10-dataset
nfs:
server: <IP or hostname>
path: /path/to/dataset
When Kubernetes starts a container on a worker node, it starts of with the exact same files that were added to the container image during build time. Since we’re pulling a PyTorch container image from NGC, the container only contains PyTorch and it’s supporting libraries. Kubernetes volumes allow us to mount a temporary or external storage volume in the container, and make it available to your application. In the snippet above, we specify two types of volumes:
- NFS: This instructs Kubernetes to mount our network share drive with the training and test dataset that we set up in Step 4. You’ll need to provide the IP address or host name and the NFS export path.
- gitRepo: This instructs Kubernetes to initialize a local volume and checkout the contents specified in the “repository” URL. Be sure to update the URL to match your personal GitHub repo that contains your changes.
Compute resources section:
computeResources:
- name: "nvidia-gpu"
resources:
limits:
nvidia.com/gpu: 1
Finally, we specify the compute resources for each training run. In this example, we use only one GPU per training run using one set of hyperparameters. If the training code supports multi-GPU training and you have more than one GPU available, then you can increase the number of GPUs here. Kubernetes will automatically find a node with the requested number of GPUs and schedule the job there.
Step 6: Submit multiple Kubernetes job requests using above specification template
In our example, we run multiple Kubernetes Jobs – one job per hyperparameter set – each with a unique identifier, so that no two jobs run on the same hyperparameter set specified in hyperparams.yml we created in Step 1.
To achieve this, we’ll use the Parallel Processing using Expansions approach described in the Kubernetes documentation. The idea is that you create a template (cifar10-job-template.yml) that describes the job that we need to run.
env:
- name: JOB_ID
value: "$ITEM"
In the template is a unique placeholder called $ITEM (as shown above). Running the create_jobs.shscript (as shown below) expands the template into multiple Job specification files, one for each hyperparameter set to be trained on. $ITEM in each generated Job specification file will replaced by a unique Job number.
> cd ~/k8s-experiment/kubernetes-hyperparam-exp > mkdir hyperparam-jobs-specs > ./create_jobs.sh 16 > ls hyperparam-jobs-specs/ cifar10-job-10.yml cifar10-job-14.yml cifar10-job-2.yml cifar10-job-6.yml cifar10-job-11.yml cifar10-job-15.yml cifar10-job-3.yml cifar10-job-7.yml cifar10-job-12.yml cifar10-job-16.yml cifar10-job-4.yml cifar10-job-8.yml cifar10-job-13.yml cifar10-job-1.yml cifar10-job-5.yml cifar10-job-9.yml
The above code snippet generates 16 separate job specification files. Each file has a unique name and a unique environment variable that enables each worker to query a hyperparameter set based on its JOB_ID. If you’re covering more hyperparameter sets, then simply call create_jobs.sh with an argument specifying the total number of hyperparameter sets to cover as specified by generate_hyperparam_combinations.py in Step 1.
To submit a job just run:
> kubectl create -f hyperparam-jobs-specs/ job.batch "cifar10-single-job-1" created job.batch "cifar10-single-job-10" created job.batch "cifar10-single-job-11" created job.batch "cifar10-single-job-12" created job.batch "cifar10-single-job-13" created job.batch "cifar10-single-job-14" created job.batch "cifar10-single-job-15" created job.batch "cifar10-single-job-16" created job.batch "cifar10-single-job-2" created job.batch "cifar10-single-job-3" created job.batch "cifar10-single-job-4" created job.batch "cifar10-single-job-5" created job.batch "cifar10-single-job-6" created job.batch "cifar10-single-job-7" created job.batch "cifar10-single-job-8" created job.batch "cifar10-single-job-9" created
As I mentioned earlier, Kubernetes API is agnostic to things like number of nodes, number of GPUs per node, status of each node, and so on. As a user, you simply submit your jobs using the command above and Kubernetes will take care of scheduling and running them.
You can verify what pods are running by issuing the following command on the master:
> kubectl get pods NAME READY STATUS RESTARTS AGE cifar10-single-job-1-vcnn9 0/1 Completed 0 2m cifar10-single-job-10-lk6g4 0/1 Completed 0 2m cifar10-single-job-11-64pmk 0/1 Completed 0 2m cifar10-single-job-12-sshjt 0/1 Completed 0 2m cifar10-single-job-13-gvlrn 1/1 Running 0 2m cifar10-single-job-14-5bjfq 1/1 Running 0 2m cifar10-single-job-15-jbmk4 1/1 Running 0 2m cifar10-single-job-16-h6dbg 0/1 Pending 0 2m cifar10-single-job-2-klvm2 0/1 Pending 0 2m cifar10-single-job-3-2zhn2 0/1 Pending 0 2m cifar10-single-job-4-5g8fz 0/1 Pending 0 2m cifar10-single-job-5-c4762 1/1 Running 0 2m cifar10-single-job-6-mkf2r 0/1 Pending 0 2m cifar10-single-job-7-6j8rv 0/1 Pending 0 2m cifar10-single-job-8-wl5h8 0/1 Pending 0 2m cifar10-single-job-9-zlxhz 0/1 Pending 0 2m
If there are enough GPU resources in your cluster, all jobs will start at the same time. If you have fewer resources than the number of jobs, the job status will be marked pending until resources free up. Kubernetes automatically takes care of resource allocation and scheduling.
Step 7: Analyze results and pick the best hyperparameter set
After all the jobs have completed running, navigate to your NFS share and you should see a list of log files which contain training run metrics such as training time, test accuracy, etc.
> ls -rw-r--r-- 1 root root 209 Dec 11 02:44 results_job_id_10.log -rw-r--r-- 1 root root 214 Dec 11 02:44 results_job_id_11.log -rw-r--r-- 1 root root 209 Dec 11 02:44 results_job_id_12.log -rw-r--r-- 1 root root 214 Dec 11 02:46 results_job_id_13.log ...
Here is an example of what our output file looks like:
> cat results_job_id_14.log epoch,24 lr,0.0 train time,2.9695417881011963 train loss,0.38534954896907214 train acc,0.8684761597938144 test time,0.34630489349365234 test loss,0.3725375 test acc,0.8757 total time,75.12576508522034
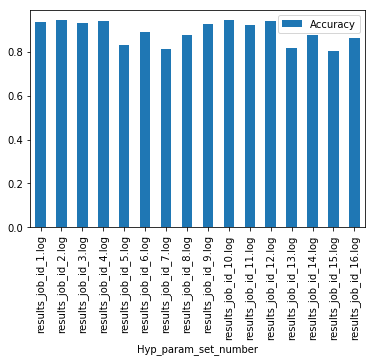
Now open the Jupyter notebook Hyperparam_search_results.ipynb and run through the cells to analyze the results. We go through all the output log files, one for each Job, and pick the model and hyperparameter set that gave us the best test accuracy results. The best results from our run yields an accuracy of 94.26% and the hyperparameters that yield this result is shown as the output of cell 7:
Results of hyperparameter sweep experiment:
-------------------------------------------
Maximum accuracy: 0.9426
Experiment set with max accuracy: results_job_id_2.log
{'batch_norm': 'on',
'batch_size': 512,
'data_aug_cutout_size': 5,
'max_learning_rate': 0.4,
'momentum': 0.9}
Conclusion
Hopefully this gives you a good overview of how Kubernetes can be used to run large-scale hyperparameter sweep experiments. Through an example, we saw how to set up a generic framework for running large-scale training experiments using Kubernetes. In practice, many organizations prefer to build on top of existing solution such as Kubeflow rather than building from scratch like we did in this post. Ultimately, Kubernetes offers flexible customization options and has a huge and continuously growing community that you can leverage as you embark on your Kubernetes journey.
For more information on getting started with Kubernetes for GPU-accelerated workloads visit the developer page for links to previous talks, videos and documentation.
Common use cases of Kubernetes for AI include:
- Many users, many nodes: Many-users can share the same infrastructure in your organization by defining Kubernetes namespaces to logically isolate the cluster resources amongst teams.
- Cloud bursting: Developers can easily burst into the cloud when there is a sudden increase in demand for training or inference.
- Production inference: Kubernetes offers capabilities such as automatic scaling and load balancing, automated rollouts and rollbacks, and ensures high availability of inference applications such as TensorRT Inference Server.
For AI workloads on Kubernetes, NVIDIA maintains tuned and tested deep learning framework containers such as TensorFlow, PyTorch, MXNet and others on the NGC container registry, and I encourage you to use them for the best performance on GPUs. NVIDIA releases new versions of the most popular AI containers every month on NGC, all tested for performance on NVIDIA GPUs on the top cloud providers, NVIDIA DGX systems, select NVIDIA TITAN and Quadro GPUs, and NGC-Ready systems from OEM partners.
The major cloud providers also offer managed Kubernetes services that can leverage NVIDIA GPUs, so you can quickly get started with deep learning training or inference workloads. For more information, refer to this documentation page on how to get started with Kubernetes on AWS and Google Cloud Platform.
To learn more join this webinar on the same topic on Tuesday, Dec 18, 2018 to learn more about using Kubernetes in AI environments. You’ll also have the opportunity to ask questions and hear answers to questions from other participants.
References
1Improved regularization of convolutional neural networks with cutout, T DeVries, GW Taylor – arXiv preprint arXiv:1708.04552, 2017
2Ning Qian. On the momentum term in gradient descent learning algorithms. Neural networks : the official journal of the International Neural Network Society, 12(1):145–151, 1999
3Batch normalization: Accelerating deep network training by reducing internal covariate shift, S Ioffe, C Szegedy – arXiv preprint arXiv:1502.03167, 2015
4Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton, https://www.cs.toronto.edu/~kriz/cifar.html