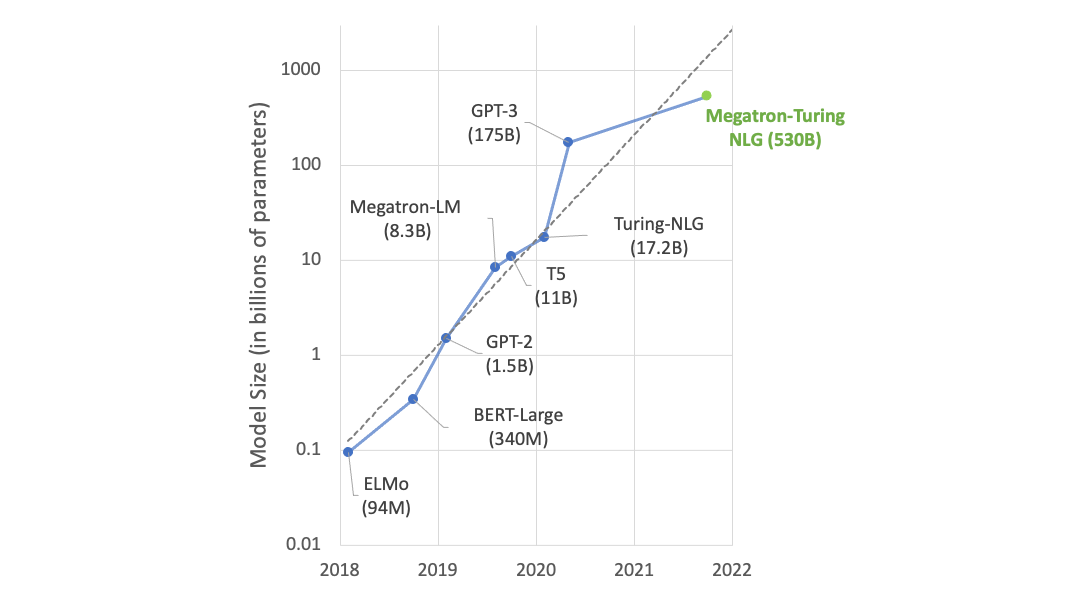
Recent work has demonstrated that larger language models dramatically advance the state of the art in natural language processing (NLP) applications such as question-answering, dialog systems, summarization, and article completion. However, during training, large models do not fit in the available memory of a single accelerator, requiring model parallelism to split the parameters across multiple accelerators.
Our recent project Megatron presented a simple and efficient model parallel approach by making only a few targeted modifications to existing PyTorch transformer implementations. We studied the computational efficiency of this approach and showed that we reach 76% scaling efficiency on 512 GPUs compared to a fast, single-GPU baseline.
Using Megatron, we showcased convergence of an 8.3 billion parameter GPT2 language model and achieved state-of-the-art results on multiple tasks, including WikiText-103 and LAMBADA. Megatron was recently used by Microsoft’s Turing NLG to train the world’s largest language model with 17 billion parameters, which pushed the latest results further.
In this post, we present the extension of Megatron to Bidirectional Encoder Representations from Transformers (BERT) and train models up to 3.9 billion parameters, making it the world’s largest BERT model at 12x the size of BERT-large. We show that careful attention to the placement of layer normalization in BERT-style models is critical to achieving increased accuracies as the model size grows.
We evaluated the trained BERT models on several downstream tasks, including MNLI, QQP, SQuAD, and RACE and showed that as the model size increases, the downstream task accuracy improves in all cases. Our 3.9B model achieved state-of-the-art results on the RACE test set leaderboard, both as a single model as well as an ensemble.
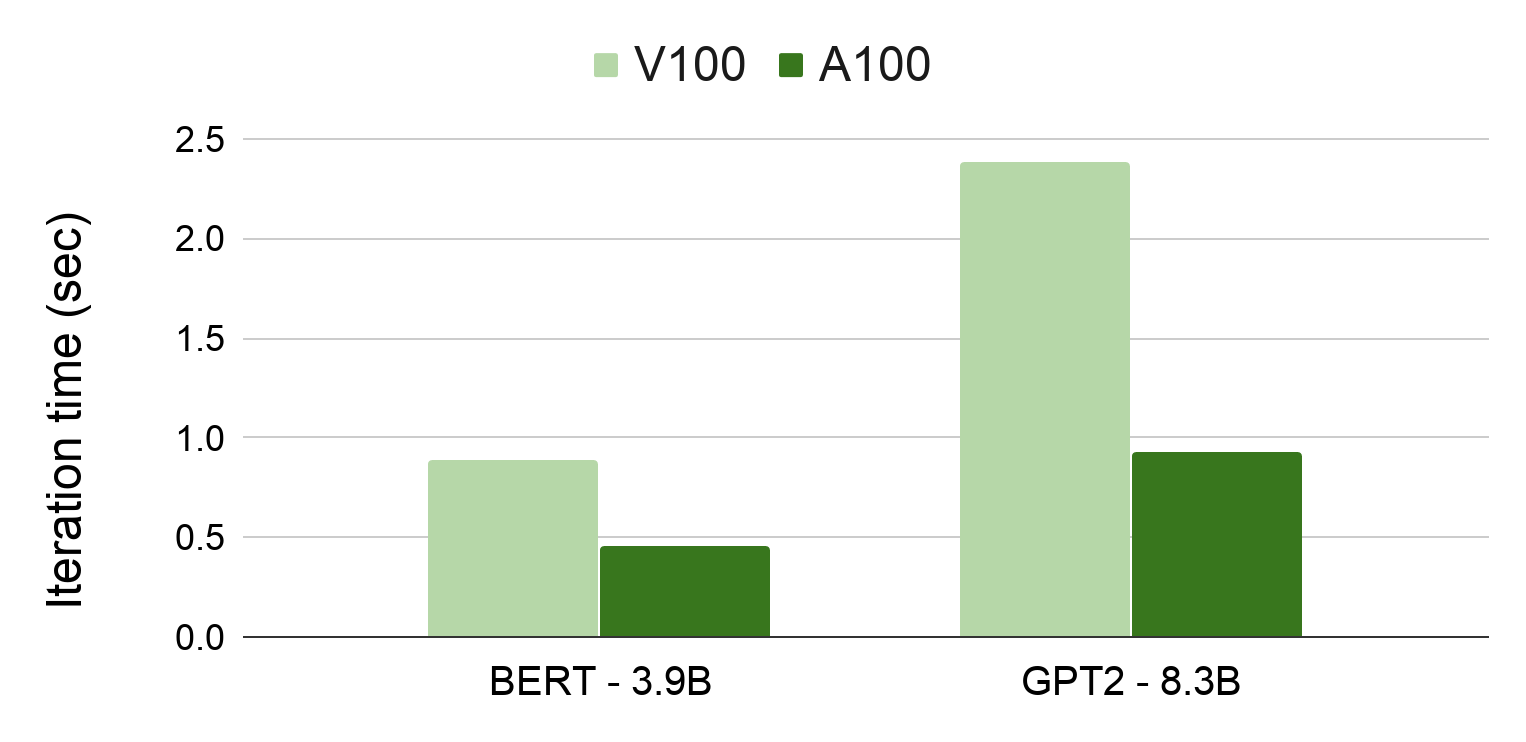
In addition, we evaluated the computational efficiency of Megatron on the recently announced NVIDIA A100 GPU. The empirical results show that for the GPT2 model, we achieve more than 2.5x speedup compared to V100 for the end-to-end application when using 16-bit floating point (FP16).
We further investigated the model parallel scaling of Megatron on A100 and showed that an eight-way model parallel achieves 79.6% scaling efficiency compared to a strong, single-GPU baseline that achieves 111 teraFLOPs, which is 35.7% of the theoretical peak FLOPs of the A100 GPU in FP16.
We have open-sourced our code in the Megatron-LM GitHub repo. Further details can be found in our paper, Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism.
Megatron-BERT
Language model pretraining using BERT led to a breakthrough in language representation learning and showed significant improvements on several downstream tasks. RoBERTa performed a careful study of BERT and made several improvements in BERT pretraining. Both the original BERT paper and RoBERTa showed that scaling the model size from 117M (BERT-base) to 336M (BERT-large) improves the accuracy of the downstream tasks significantly. However, they never considered models larger than that.
Recent work posed the following question, “Is having better NLP models as easy as having larger models?” It showed that increasing the size of the BERT model from 336M to 1.3B leads to worse accuracy. To address this degradation and to alleviate the memory requirements of large models, the authors introduced parameter sharing and showed that their models scaled much better compared to the original BERT model.
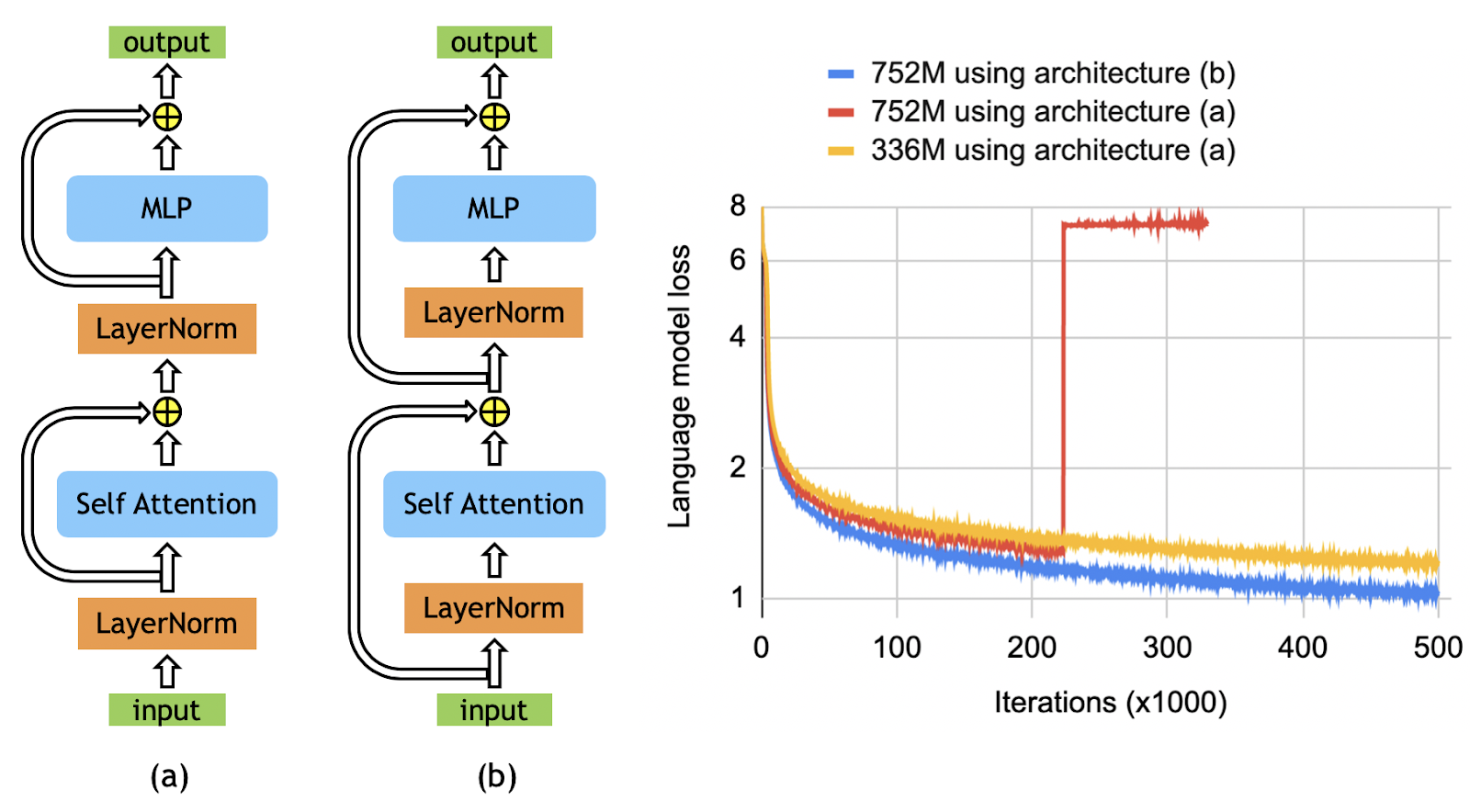
We investigated this degradation in model accuracy. We empirically demonstrated that rearranging the order of the layer normalization and the residual connections, as shown in Figure 1, is critical to enabling the scaling of the BERT-style models beyond 336M parameters. This rearrangement is similar to the one used in GPT2 and some prior work in machine translation and allows the gradients to directly flow through the network without going through layer normalization. The architecture (b) in Figure 1 eliminates instabilities observed using the original BERT architecture, allowing us to train larger models.
Pretraining
Using the architecture change in Figure 1(b), we considered three different cases as detailed in Table 1. The 336M model has the same size as BERT-large. The 1.3B is the same as the BERT-xlarge configuration that was previously shown to get worse results than the BERT-large model.
We further scaled the BERT model using both larger hidden sizes as well as more layers. That’s how we arrived at the 3.9B parameter case, the largest BERT model ever trained. This network uses four-way model parallelism. It requires 55% more compute FLOPs per iteration and batch than ALBERT-xxlarge while being trained on only one-third of the total tokens as ALBERT-xxlarge, thereby requiring only 52% compute FLOPS compared to the ALBERT-xxlarge training.
We largely followed the training process described in ALBERT. For all cases, we set the batch size to 1024 and used a learning rate of 1.0e-4 warmed up over 10K iterations and decayed linearly over 2 million iterations. Other training parameters were kept the same as ALBERT. We trained the models on an aggregate corpus containing 174 GB of deduplicated text collected from Wikipedia, RealNews, CC-Stories, OpenWebtext, and BooksCorpus.
| Parameter count | Hidden size | Attention heads | Layers | Model parallel GPUs | Model + Data parallel GPUs |
| 336M | 1024 | 16 | 24 | 1 | 128 |
| 1.3B | 2048 | 32 | 24 | 1 | 256 |
| 3.9B | 2560 | 40 | 48 | 4 | 512 |
Table 1. Model configurations used for BERT.
Results
On a 3% held-out validation set, our 336M, 1.3B, and 3.9B models achieved a loss of 1.58, 1.30, and 1.16, respectively, a monotonic decrease with the model size. We fine-tuned the trained models on several downstream tasks including MNLI and QQP from the GLUE benchmark, SQuAD 1.1 and SQuAD 2.0 from the Stanford Question Answering Dataset, and the reading comprehension RACE dataset.
For fine-tuning, we followed the same procedure as RoBERTa. We first performed hyperparameter tuning on batch size and learning rate. After we obtained the best values, we reported the median development set results over five different random seeds for initialization.
Table 2 shows the development set results and compares it to other BERT-style models for MNLI, QQP, SQuAD 1.1, and SQuAD 2.0, and test set results for RACE. The trained tokens in Table 2 represent consumed tokens during model pretraining (proportional to batch size times number of iterations) normalized by consumed tokens during model pretraining for the 336M model. We observed the following:
- As the model size increases, the downstream task accuracies improve in all cases.
- The 3.9B model establishes state-of-the-art results compared to other BERT-style models.
| Model | Trained tokens (ratio) | MNLI m/mm accuracy (dev set) | QQP accuracy (dev set) | SQuAD 1.1 F1/EM (dev set) | SQuAD 2.0 F1/EM (dev set) | RACE m/h accuracy (test set) |
| RoBERTa | 2 | 90.2 / 90.2 | 92.2 | 94.6 / 88.9 | 89.4 / 86.5 | 83.2 (86.5 / 81.8) |
| ALBERT | 3 | 90.8 | 92.2 | 94.8 / 89.3 | 90.2 / 87.4 | 86.5 (89.0 / 85.5) |
| XLNet | 2 | 90.8 / 90.8 | 92.3 | 95.1 / 89.7 | 90.6 / 87.9 | 85.4 (88.6 / 84.0) |
| Megatron-336M | 1 | 89.7 / 90.0 | 92.3 | 94.2 / 88.0 | 88.1 / 84.8 | 83.0 (86.9 / 81.5) |
| Megatron-1.3B | 1 | 90.9 / 91.0 | 92.6 | 94.9 / 89.1 | 90.2 / 87.1 | 87.3 (90.4 / 86.1) |
| Megatron-3.9B | 1 | 91.4 / 91.4 | 92.7 | 95.5 / 90.0 | 91.2 / 88.5 | 89.5 (91.8 / 88.6) |
For the RACE dataset as well as SQuAD, we reported the results for the Megatron-3.9B model using a five-way ensemble and compared it with the results established by ALBERT in Table 3. For the RACE dataset, the test set is available. However, for SQuAD, the model was too large to fit on the evaluation server’s GPUs, and as a result, we could not report test set results.
Instead, we reported the development ensemble results and compared them to the development ensemble results of ALBERT. Our ensemble Megatron-3.9B results in much better F1/EM scores for SQuAD and establishes state-of-the-art results on the RACE leaderboard.
| Model | SQuAD 1.1 dev set F1 / EM | SQuAD 2.0 dev set F1 / EM | RACE m/h test set accuracy |
| ALBERT ensemble | 95.5 / 90.1 | 91.4 / 88.9 | 89.4 (91.2 / 88.6) |
| Megatron-3.9B ensemble | 95.8 / 90.5 | 91.7 / 89.0 | 90.9 (93.1 / 90.0) |
Megatron using A100
NVIDIA recently launched A100, the next-generation AI chip with 312 teraFLOPs of FP16 compute power (624 teraFLOPs with sparsity) and 40 GB of DRAM. This makes A100 a very unique accelerator for large-scale computations performed with Megatron.
Using A100, we benchmarked two of the largest models that we have trained with Megatron:
- Megatron-GPT2 with 8.3 billion parameters
- Megatron-BERT with 3.9 billion parameters
Figure 2 compares the results to previously reported numbers using V100 GPUs. The numbers reported here use only a single DGX server, are from models in FP16, and include software optimization performed for A100. Megatron-GPT2 shows a 2.5x speedup in the end-to-end application on A100, compared to previously published results using V100. We should note that A100 contains hardware acceleration for sparse neural networks, which can provide a peak of 2x faster arithmetic throughput. Exploring A100 sparsity for transformer networks is the subject of future work.

Table 4 shows the results of looking further into model parallel weak scaling using A100. We considered four GPT2 configurations ranging from 1.2B to 8.7B parameters and using up to eight-way model parallelism. The number of model parallel GPUs is chosen such that the model fits into DRAM of the accelerators.
| Number of parameters (billions) | Model parallel GPUs | Weak Scaling | Sustained teraFLOPs per GPU | Percentage of theoretical peak FLOPs |
| 1.2 | 1 | Baseline (100%) | 111 | 35.7% |
| 2 | 2 | 90.7% | 103 | 33.1% |
| 4.2 | 4 | 86.5% | 97 | 31.1% |
| 8.7 | 8 | 79.6% | 85 | 27.2% |
The baseline with 1.2B parameters sustains 111 teraFLOPs throughout the entire application which is 35.7% of the theoretical peak FLOPs without using sparsity. We observed excellent scaling numbers. For example, the eight-way model parallel case achieves 79.6% weak scaling compared to the strong 1.2B baseline, and it sustains 27.2% of the theoretical peak FLOPs per GPU.
Conclusion
In this work, we showed that for BERT models, careful attention to the placement of layer normalization is critical to achieving increased accuracy as the model size increases.
We studied the effect of model size on downstream task accuracy, trained BERT models as large as 3.9 billion parameters, achieved far superior results on downstream tasks, and established new SOTA results for RACE datasets. We benchmarked Megatron on the recently launched NVIDIA A100 GPUs and showed that up to 2.5x speedups can be achieved compared to previously published results.
Finally, we open sourced our code to enable future work leveraging model parallel transformers. We are excited to train bigger and better models faster with A100.