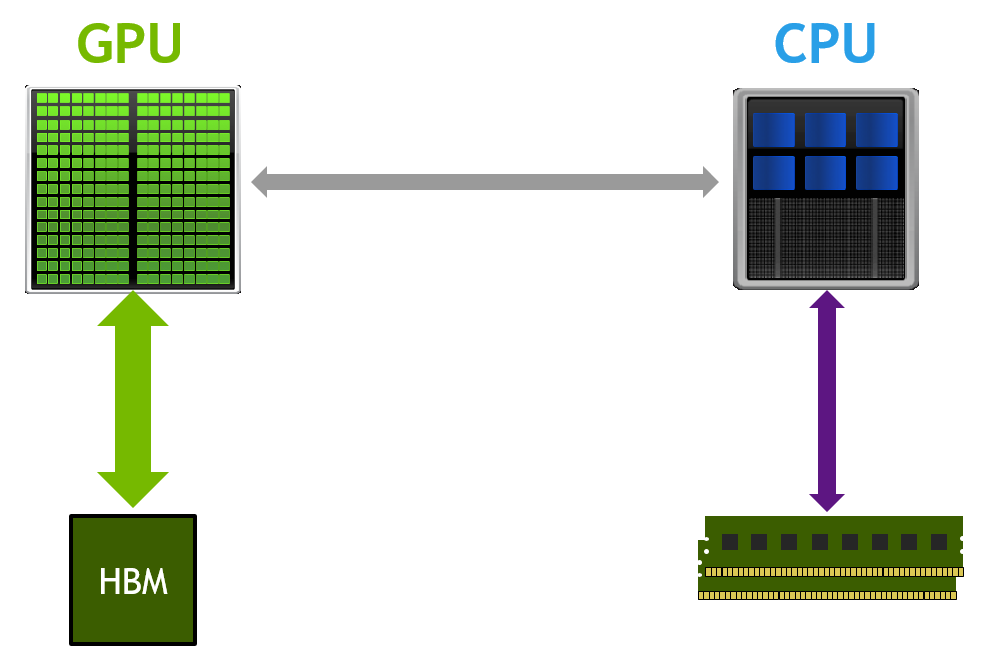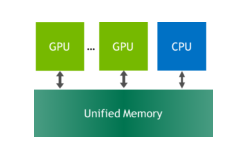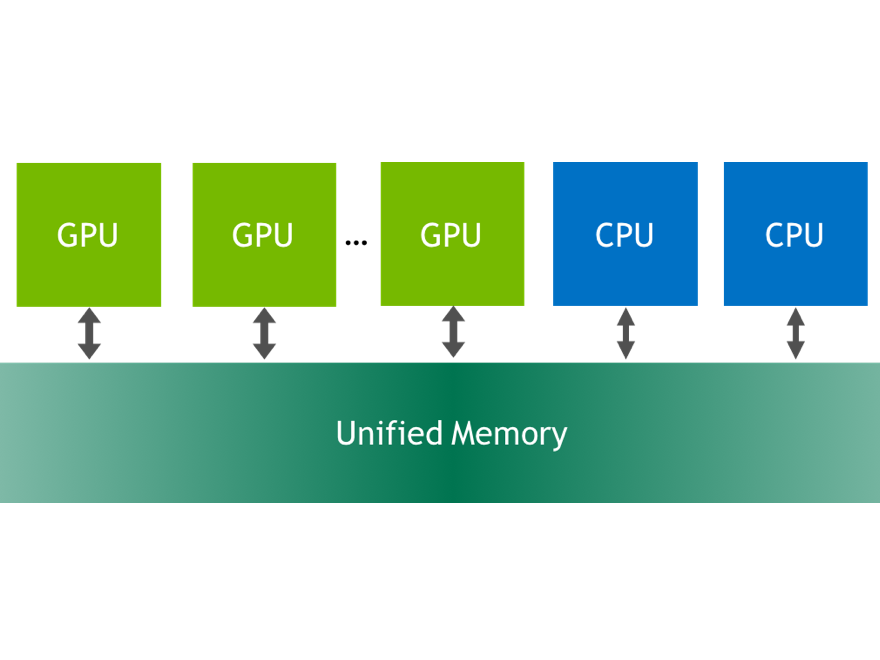
Many of today’s applications process large volumes of data. While GPU architectures have very fast HBM or GDDR memory, they have limited capacity. Making the most of GPU performance requires the data to be as close to the GPU as possible. This is especially important for applications that iterate over the same data multiple times or have a high flops/byte ratio. Many real-world codes have to selectively use data on the GPU due to its limited memory capacity, and it is the programmer’s responsibility to move only necessary parts of the working set to GPU memory. 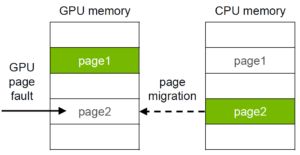
Traditionally, developers have used explicit memory copies to transfer data. While this usually gives the best performance, it requires very careful management of GPU resources and predictable access patterns. Zero-copy access provides fine-grained direct access to the entire system memory, but the speed is limited by the interconnect (PCIe or NVLink) and it’s not possible to take advantage of data locality.
Unified Memory combines the advantages of explicit copies and zero-copy access: the GPU can access any page of the entire system memory and at the same time migrate the data on-demand to its own memory for high bandwidth access. To get the best Unified Memory performance it’s important to understand how on-demand page migration works. In this post I’ll break it down step by step and show you what you can do to optimize your code to get the most out of Unified Memory.
A Streaming Example
I will focus on a streaming example that reads or writes a contiguous range of data originally resident in the system memory. Although this type of access pattern is quite basic, it is fundamental for many applications. If Unified Memory performance is good on this common access pattern, we can remove all manual data transfers and just directly access the pointers relying on automatic migration. The following simple CUDA kernel reads or writes a chunk of memory in a contiguous fashion.
template <typename data_type, op_type op>
__global__ void stream_thread(data_type *ptr, const size_t size,
data_type *output, const data_type val)
{
size_t tid = threadIdx.x + blockIdx.x * blockDim.x;
size_t n = size / sizeof(data_type);
data_type accum = 0;
for(; tid < n; tid += blockDim.x * gridDim.x)
if (op == READ) accum += ptr[tid];
else ptr[tid] = val;
if (op == READ)
output[threadIdx.x + blockIdx.x * blockDim.x] = accum;
}
This benchmark migrates data from CPU to GPU memory and accesses all data once on the GPU. The input data (ptr) is allocated with cudaMallocManaged or cudaMallocHost and initially populated on the CPU. I tested three different approaches to migrating the data.
- On-demand migration by passing the
cudaMallocManagedpointer directly to the kernel; - Prefetching the data before the kernel launch by calling
cudaMemPrefetchAsyncon thecudaMallocManagedpointer; - Copying the data from
cudaMallocHostto a preallocatedcudaMallocbuffer on the GPU usingcudaMemcpyAsync.
In all three cases I measure any explicit data transfer time and the kernel time.
Figure 1 shows initial performance results for the GPU inbound (read) transfers when using different allocators for PCIe and NVLink systems. All systems are using the CUDA 9 toolkit and driver. There are two PCIe systems, one with Tesla P100 and another with Tesla V100. For both PCIe systems the peak bandwidth between the CPU and the GPU is 16GB/s. The NVink system is an IBM Minsky server with 2 links of NVLink connecting the CPU and the GPU with peak interconnect bandwidth of 40GB/s.
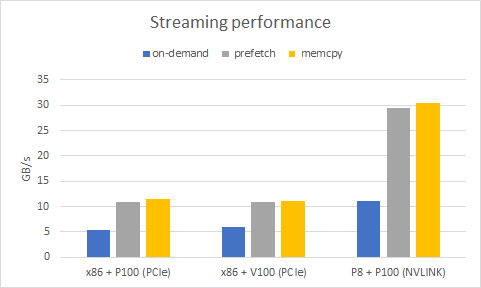
Considering that Unified Memory introduces a complex page fault handling mechanism, the on-demand streaming Unified Memory performance is quite reasonable. Still it’s almost 2x slower (5.4GB/s) than prefetching (10.9GB/s) or explicit memory copy (11.4GB/s) for PCIe. The difference is more profound for NVLink. The upside is that if you have a lot of compute in your kernel then the migrations can be amortized or overlapped with other computation, and in some scenarios Unified Memory performance may even be better than a non-overlapping cudaMemcpy and kernel approach. In my simple example there is a minimal amount of compute (only local per-thread accumulation) and the explicit prefetching and copy approaches set an upper bound for the achievable bandwidth. Let’s see if we can improve the pure streaming Unified Memory performance and understand how close we can get to the achieved bandwidth of explicit data transfers.
Page Migration Mechanism
Before diving into optimizations I want to explain what happens when a cudaMallocManaged allocation is accessed on the GPU. You can check out my GTC 2017 talk for more details.The sequence of operations (assuming no cudaMemAdvise hints are set and there is no thrashing) is:
- Allocate new pages on the GPU;
- Unmap old pages on the CPU;
- Copy data from the CPU to the GPU;
- Map new pages on the GPU;
- Free old CPU pages.
Much like CPUs, GPUs have multiple levels of TLBs (Translation Lookaside Buffer: a memory cache that stores recent virtual to physical memory address translations) to perform address translations. When Pascal and Volta GPUs access a page that is not resident in the local GPU memory the translation for this page generates a fault message and locks the TLBs for the corresponding SM (on Tesla P100 it locks a pair of SMs that share a single TLB). This means any outstanding translations can proceed but any new translations will be stalled until all faults are resolved. This is necessary to make sure the SM’s view of memory is consistent since during page fault processing the driver may modify the page table and add or revoke access to pages. The GPU can generate many faults concurrently and it’s possible to get multiple fault messages for the same page. The Unified Memory driver processes these faults, remove duplicates, updates mappings and transfers the data. This fault handling adds significant overhead to streaming performance of Unified Memory on current generation GPU architectures.
Understanding Profiler Output
Since each fault increases the driver’s processing time it is important to minimize page faults during CUDA kernel execution. At the same time you want to provide enough information about your program’s access pattern to the driver so it can prefetch efficiently. Here’s the nvprof profiler output from running my initial streaming code on a small 64MB dataset.
==95657== Unified Memory profiling result:
Device "Tesla P100-SXM2-16GB (0)"
Count Avg Size Min Size Max Size Total Size Total Time Name
349 187.78KB 64.000KB 896.00KB 64.00000MB 2.568640ms Host To Device
88 - - - - 5.975872ms Gpu page fault groups
The total migration size is 64MB, which matches the setup. There are also the minimum and the maximum migration sizes. The minimum size usually equals the OS page size which is 64KB on the test system (IBM Power CPU). In practice, the transfer size is not fixed to the OS page size and can vary significantly. As you can see from the profiler output the driver has transferred chunks of up to 896 KB. The mechanism for this is called density prefetching, which works by testing how much of the predefined region has been or is being transferred; if it meets a certain threshold the driver prefetches the rest of the pages. In addition, the driver may also merge nearby smaller pages into larger pages on the GPU to improve TLB coverage. All this happens automatically during page fault processing (and outside of user control). Note that this is the current driver behavior and the performance heuristics might change in future. (Note that the Linux Unified Memory driver is open source, so keen developers can review what happens under the hood).
The number 88 above on the second line is not the total number of faults, but rather the number of page fault groups. The faults are written to a special buffer in system memory and multiple faults forming a group are processed simultaneously by the Unified Memory driver. You can get the total number of faults for each group by specifying --print-gpu-trace, as the following nvprof excerpt shows.
==32593== Profiling result: ...,"Unified Memory","Virtual Address","Name" ...,"114","0x3dffe6c00000","[Unified Memory GPU page faults]" ... ...,"81","0x3dffe6c00000","[Unified Memory GPU page faults]" ... ...,"12","0x3dffe6c40000","[Unified Memory GPU page faults]" ...
The profiler shows that there are 114 faults reported just for a single page, and then more faults for the same address later. The driver must filter duplicate faults and transfer each page just once. Moreover, for this simple implementation very few different pages are accessed at the same time. Therefore, during fault processing the driver doesn’t have enough information about what data can be migrated to the GPU. Using vectorized load/store instructions up to 128 bits wide may reduce the overall number of faults and spread out the access pattern a bit, but it won’t change the big picture. So the question is how to increase the number of uniquely accessed pages to take advantage of the driver prefetching mechanism?
Warp-Per-Page Approach
Instead of having multiple hardware warps accessing the same page, we can divide pages between warps to have a one-to-one mapping and have each warp perform multiple iterations over the 64K region. Here is an updated kernel implementing this idea.
#define STRIDE_64K 65536
template
__global__ void stream_warp(data_type *ptr, const size_t size, data_type *output, const data_type val)
{
int lane_id = threadIdx.x & 31;
size_t warp_id = (threadIdx.x + blockIdx.x * blockDim.x) >> 5;
int warps_per_grid = (blockDim.x * gridDim.x) >> 5;
size_t warp_total = (size + STRIDE_64K-1) / STRIDE_64K;
size_t n = size / sizeof(data_type);
data_type accum = 0;
for(; warp_id < warp_total; warp_id += warps_per_grid) {
#pragma unroll
for(int rep = 0; rep < STRIDE_64K/sizeof(data_type)/32; rep++) {
size_t ind = warp_id * STRIDE_64K/sizeof(data_type) + rep * 32 + lane_id;
if (ind < n) {
if (op == READ) accum += ptr[ind];
else ptr[ind] = val;
}
}
}
if (op == READ)
output[threadIdx.x + blockIdx.x * blockDim.x] = accum;
}
The profiler output shows that now there is just one fault per page in most cases and overall the number of page fault groups is also reduced.
...,"Unified Memory","Virtual Address","Name" ...,"1","0x3dffe6e00000","[Unified Memory GPU page faults]" ...,"1","0x3dffe6e10000","[Unified Memory GPU page faults]" ...
Figure 2 shows updated results for the streaming benchmark.
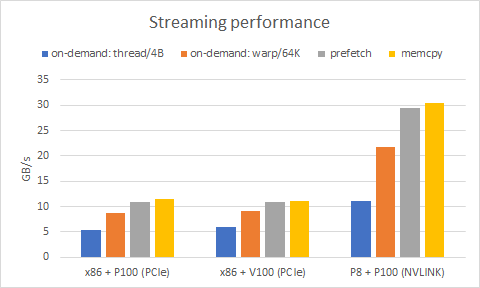
There is a solid speedup up to 2x compared to the original code and now on-demand migration is just 30% short of the maximum achieved bandwidth for both PCIe and NVLink. Note that this minor change in access pattern is not intrusive so you can easily wrap it into a lightweight macro or a C++ class to reuse in your applications. For many other access patterns it may be possible to apply similar techniques. As GPUs are getting wider with more SMs the number of concurrent page faults is increasing so it is even more important to process them efficiently.
Overlapping Kernels and Prefetches
On-demand migration is powerful in the way it enables fine-grain overlap between data transfers and kernel execution. However, as I explained previously this overlap is severely limited due to the SM stalls caused by page fault handling. Even with very sophisticated driver prefetching heuristics, on-demand access with migration will never beat explicit bulk data copies or prefetches in terms of performance for large contiguous memory regions. This is the price for simplicity and ease of use. If the application’s access pattern is well defined and structured you should prefetch usingcudaMemPrefetchAsync. You can completely avoid stalls by manually tiling your data into contiguous memory regions and sending them to the GPU with cudaMemPrefetchAsync similar to cudaMemcpyAsync. This allows for more explicit control of what’s happening and at the same time provides a uniform view of memory by using a single address space, but there are some caveats.
Looking at Figure 2 it’s clear that cudaMemPrefetchAsync is on par with cudaMemcpyAsync for achieved bandwidth. However, prefetches and copies have different sequences of operations. While cudaMemcpyAsync only needs to submit copies over the interconnect, cudaMemPrefetchAsync also needs to traverse a list of pages and update corresponding mappings in the CPU and GPU page tables. Some of the operations have to be done in order, which limits concurrency and latency hiding opportunities. On the other hand, cudaMemcpyAsync requires the application to maintain host and device memory allocations separately.
There are specific rules on how prefetching interacts with CUDA streams. For busy CUDA streams, the call to prefetch is deferred to a separate background thread by the driver because the prefetch operation has to execute in stream order. The background thread performs the prefetch operation when all prior operations in the stream complete. For idle streams, the driver has a choice to either defer the operation or not, but the driver typically does not defer because of the associated overhead. The exact scenarios under which the driver may decide to defer can vary from driver to driver.
For host-to-device prefetches that are not deferred by the driver, the call returns after the pages have been unmapped from the CPU and the work to migrate those pages to the GPU and update the GPU’s page tables has been enqueued on the GPU. In other words, the call returns before the entire prefetch operation has completed. For device-to-host prefetches that are not deferred by the driver, the call doesn’t return until the entire prefetch operation has completed. This is because the CPU’s page tables cannot be updated asynchronously. So to unblock the CPU for device-to-host prefetches, the stream should not be idle when calling cudaMemPrefetchAsync. The tradeoff is that the deferred path has some additional overhead but it helps to enqueue more work without stalling the CPU, which may lead to better overlapping opportunities.
Achieving good one-way prefetch-kernel overlap is relatively easy as long as the kernel is submitted first. This may be counterintuitive, but it works because CUDA kernel launches are non-blocking and return almost immediately. Two-way prefetch overlap is more complicated because if you use the same CPU path (either deferred or non-deferred) for device-to-host and host-to-device prefetches they are likely to be serialized. Let’s look at a simple example.
for (int i = 0; i < num_tiles; i++) { // offload previous tile to the cpu if (i > 0)
cudaMemPrefetchAsync(a + tile_size * (i-1), tile_size * sizeof(size_t), cudaCpuDeviceId, s1);
// run multiple kernels on current tile
for (int j = 0; j < num_kernels; j++)
kernel<<<1024, 1024, 0, s2>>>(tile_size, a + tile_size * i);
// prefetch next tile to the gpu
if (i < num_tiles)
cudaMemPrefetchAsync(a + tile_size * (i+1), tile_size * sizeof(size_t), 0, s3);
// sync all streams
cudaDeviceSynchronize();
}
This is a common tiling approach that partitions the working set into equal chunks and transfers the data for the previous and the next tiles in parallel with the processing of the current tile. For example, such a scheme is used in the NVIDIA cuBLAS XT library for out-of-core matrix multiplication. In the simple example here I have used a dummy kernel running multiple times to emulate real work happening on the GPU. All operations are submitted to three different streams so you would expect to get all three of them running concurrently. This would be the case for cudaMemcpyAsync but not for cudaMemPrefetchAsync. If you run it through the profiler you’ll see a timeline like the one in Figure 3, effectively showing no overlap between the transfers due to the device-to-host prefetch blocking the CPU.
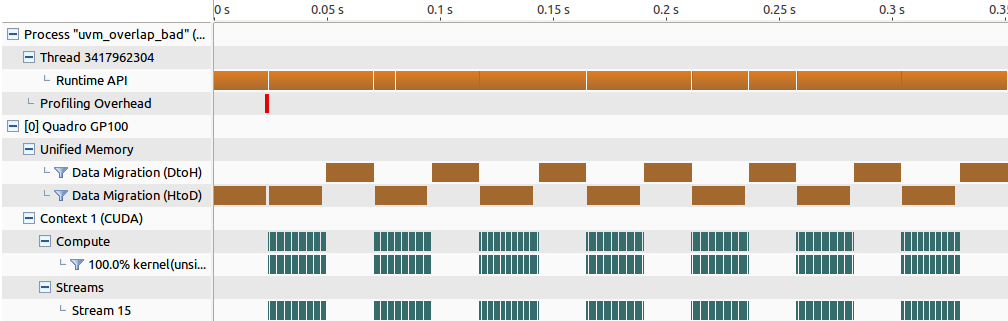
Therefore, it’s important to make sure that we have the device-to-host prefetch issued in a busy stream while the host-to-device prefetch is issued in an idle stream. Here is a modified version that achieves the new overlapping strategy.
// prefetch first tile
cudaMemPrefetchAsync(a, tile_size * sizeof(size_t), 0, s2);
cudaEventRecord(e1, s2);
for (int i = 0; i < num_tiles; i++) {
// make sure previous kernel and current tile copy both completed
cudaEventSynchronize(e1);
cudaEventSynchronize(e2);
// run multiple kernels on current tile
for (int j = 0; j < num_kernels; j++)
kernel<<<1024, 1024, 0, s1>>>(tile_size, a + tile_size * i);
cudaEventRecord(e1, s1);
// prefetch next tile to the gpu in a separate stream
if (i < num_tiles-1) {
// make sure the stream is idle to force non-deferred HtoD prefetches first
cudaStreamSynchronize(s2);
cudaMemPrefetchAsync(a + tile_size * (i+1), tile_size * sizeof(size_t), 0, s2);
cudaEventRecord(e2, s2);
}
// offload current tile to the cpu after the kernel is completed using the deferred path
cudaMemPrefetchAsync(a + tile_size * i, tile_size * sizeof(size_t), cudaCpuDeviceId, s1);
// rotate streams and swap events
st = s1; s1 = s2; s2 = st;
st = s2; s2 = s3; s3 = st;
et = e1; e1 = e2; e2 = et;
}
Figure 4 shows the profiler timeline for this new code with almost perfect three-way overlap (compute, DtoH and HtoD).
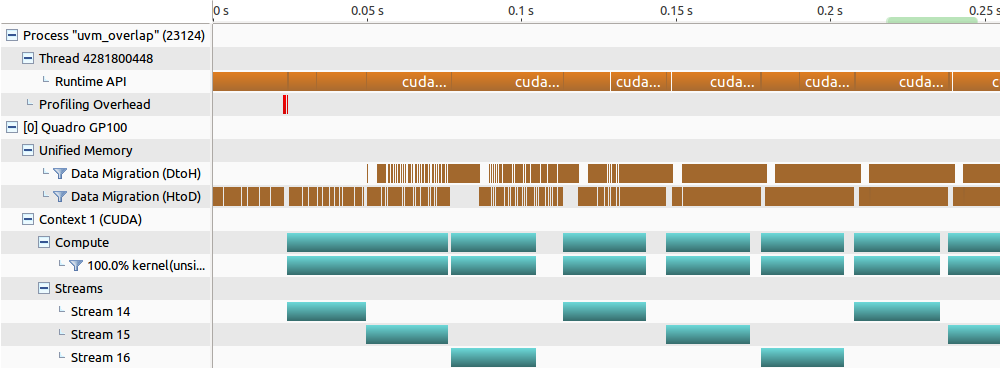
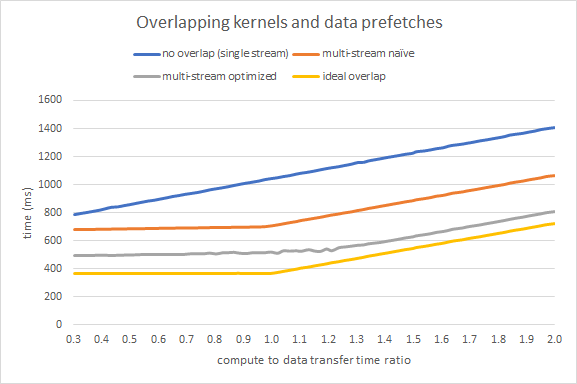
The overall speedup from better overlapping will depend on your compute to copy ratio. I ran the benchmark by using 16 tiles of 256MB and varying the compute workload weight to see the performance impact. Figure 5 shows timings in ms for the naive and optimized methods and two additional lines: no overlap using a single stream (sum of kernel and prefetch times), and ideal overlap (maximum of kernel and prefetch times). The optimized approach is 1.3x-1.5x faster than the original multi-stream code. For compute intensive workloads (high compute to data transfer ratio) the optimized version is only 10% slower than the ideal scenario.
Future Unified Memory Performance Improvements
When using Unified Memory on Pascal or Volta in CUDA 9 all pages that are accessed by the GPU get migrated to that GPU by default. Although it is possible to modify this behavior by using explicit hints (cudaMemAdvise) for the Unified Memory driver, sometimes you just don’t know if your data is accessed often enough to ensure there will be benefit from moving it to the GPU.
Volta introduces new hardware access counters that can track remote accesses to pages. These counters can be used internally to notify the driver when a certain page is accessed too often remotely so the driver can decide to move it to local memory. This helps to resolve thrashing situations more elegantly by accurately capturing and moving only the hot pages to the processor’s local memory. For applications with a mixed access pattern you can imagine the pages that are accessed sparsely will not be migrated and it can help to save bandwidth. Stay tuned for future CUDA updates with more details on access counters and updated Unified Memory performance data.
Get Started with Unified Memory in CUDA
In this post I’ve aimed to provide experienced CUDA developers the knowledge needed to optimize applications to get the best Unified Memory performance. If you are new to CUDA and would like to get started with Unified Memory, please check out the posts An Even Easier Introduction to CUDA and Unified Memory for CUDA Beginners. To learn how Unified Memory makes it possible to build applications that process data sets much larger than GPU memory, read my previous post, Beyond GPU Memory Limits with Unified Memory on Pascal.